

python实现简单爬虫功能的示例

在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材。
我们最常规的做法就是通过鼠标右键,选择另存为。但有些图片鼠标右键的时候并没有另存为选项,还有办法就通过就是通过截图工具截取下来,但这样就降低图片的清晰度。好吧~!其实你很厉害的,右键查看页面源代码。
我们可以通过python 来实现这样一个简单的爬虫功能,把我们想要的代码爬取到本地。下面就看看如何使用python来实现这样一个功能。
一,获取整个页面数据
首先我们可以先获取要下载图片的整个页面信息。
getjpg.py
#coding=utf-8
import urllib
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
html = getHtml("http://tieba.baidu.com/p/2738151262")
print html
Urllib 模块提供了读取web页面数据的接口,我们可以像读取本地文件一样读取www和ftp上的数据。首先,我们定义了一个getHtml()函数:
urllib.urlopen()方法用于打开一个URL地址。
read()方法用于读取URL上的数据,向getHtml()函数传递一个网址,并把整个页面下载下来。执行程序就会把整个网页打印输出。
二,筛选页面中想要的数据
Python 提供了非常强大的正则表达式,我们需要先要了解一点python 正则表达式的知识才行.
假如我们百度贴吧找到了几张漂亮的壁纸,通过到前段查看工具。找到了图片的地址,如:src=”http://imgsrc.baidu.com/forum......jpg”pic_ext=”jpeg”
修改代码如下:
import re
import urllib
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
return imglist
html = getHtml("http://tieba.baidu.com/p/2460150866")
print getImg(html)
我们又创建了getImg()函数,用于在获取的整个页面中筛选需要的图片连接。re模块主要包含了正则表达式:
re.compile() 可以把正则表达式编译成一个正则表达式对象.
re.findall() 方法读取html 中包含 imgre(正则表达式)的数据。
运行脚本将得到整个页面中包含图片的URL地址。
三,将页面筛选的数据保存到本地
把筛选的图片地址通过for循环遍历并保存到本地,代码如下:
#coding=utf-8
import urllib
import re
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' % x)
x+=1
html = getHtml("http://tieba.baidu.com/p/2460150866")
print getImg(html)
这里的核心是用到了urllib.urlretrieve()方法,直接将远程数据下载到本地。
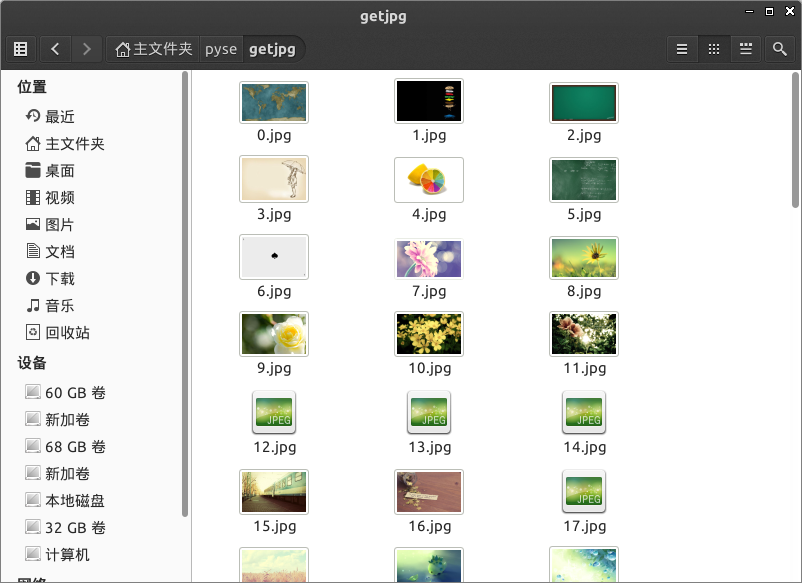
通过一个for循环对获取的图片连接进行遍历,为了使图片的文件名看上去更规范,对其进行重命名,命名规则通过x变量加1。保存的位置默认为程序的存放目录。
程序运行完成,将在目录下看到下载到本地的文件。
感谢阅读,希望能帮助到大家,谢谢大家对本站的支持!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Cara Mencantikkan Format XML
Apr 02, 2025 pm 09:57 PM
Cara Mencantikkan Format XML
Apr 02, 2025 pm 09:57 PM
Pengindahan XML pada dasarnya meningkatkan kebolehbacaannya, termasuk lekukan yang munasabah, rehat garis dan organisasi tag. Prinsipnya adalah untuk melintasi pokok XML, tambah lekukan mengikut tahap, dan mengendalikan tag dan tag kosong yang mengandungi teks. Perpustakaan XML.Etree.ElementTree Python menyediakan fungsi Pretty_XML yang mudah yang dapat melaksanakan proses pengindahan di atas.
 Cara Membuka Format XML
Apr 02, 2025 pm 09:00 PM
Cara Membuka Format XML
Apr 02, 2025 pm 09:00 PM
Gunakan kebanyakan editor teks untuk membuka fail XML; Jika anda memerlukan paparan pokok yang lebih intuitif, anda boleh menggunakan editor XML, seperti editor XML oksigen atau XMLSPY; Jika anda memproses data XML dalam program, anda perlu menggunakan bahasa pengaturcaraan (seperti Python) dan perpustakaan XML (seperti XML.Etree.ElementTree) untuk menghuraikan.
 Adakah pengubahsuaian XML memerlukan pengaturcaraan?
Apr 02, 2025 pm 06:51 PM
Adakah pengubahsuaian XML memerlukan pengaturcaraan?
Apr 02, 2025 pm 06:51 PM
Mengubah kandungan XML memerlukan pengaturcaraan, kerana ia memerlukan penemuan tepat nod sasaran untuk menambah, memadam, mengubah suai dan menyemak. Bahasa pengaturcaraan mempunyai perpustakaan yang sepadan untuk memproses XML dan menyediakan API untuk melaksanakan operasi yang selamat, cekap dan terkawal seperti pangkalan data operasi.
 Adakah terdapat aplikasi mudah alih yang boleh menukar XML ke PDF?
Apr 02, 2025 pm 08:54 PM
Adakah terdapat aplikasi mudah alih yang boleh menukar XML ke PDF?
Apr 02, 2025 pm 08:54 PM
Permohonan yang menukarkan XML terus ke PDF tidak dapat dijumpai kerana mereka adalah dua format yang berbeza. XML digunakan untuk menyimpan data, manakala PDF digunakan untuk memaparkan dokumen. Untuk melengkapkan transformasi, anda boleh menggunakan bahasa pengaturcaraan dan perpustakaan seperti Python dan ReportLab untuk menghuraikan data XML dan menghasilkan dokumen PDF.
 Adakah terdapat XML percuma untuk alat PDF untuk telefon bimbit?
Apr 02, 2025 pm 09:12 PM
Adakah terdapat XML percuma untuk alat PDF untuk telefon bimbit?
Apr 02, 2025 pm 09:12 PM
Tidak ada XML percuma yang mudah dan langsung ke alat PDF di mudah alih. Proses visualisasi data yang diperlukan melibatkan pemahaman dan rendering data yang kompleks, dan kebanyakan alat yang dipanggil "percuma" di pasaran mempunyai pengalaman yang buruk. Adalah disyorkan untuk menggunakan alat sampingan komputer atau menggunakan perkhidmatan awan, atau membangunkan aplikasi sendiri untuk mendapatkan kesan penukaran yang lebih dipercayai.
 Adakah kelajuan penukaran cepat apabila menukar XML ke PDF pada telefon bimbit?
Apr 02, 2025 pm 10:09 PM
Adakah kelajuan penukaran cepat apabila menukar XML ke PDF pada telefon bimbit?
Apr 02, 2025 pm 10:09 PM
Kelajuan XML mudah alih ke PDF bergantung kepada faktor -faktor berikut: kerumitan struktur XML. Kaedah Penukaran Konfigurasi Perkakasan Mudah Alih (Perpustakaan, Algoritma) Kaedah Pengoptimuman Kualiti Kod (Pilih perpustakaan yang cekap, mengoptimumkan algoritma, data cache, dan menggunakan pelbagai threading). Secara keseluruhannya, tidak ada jawapan mutlak dan ia perlu dioptimumkan mengikut keadaan tertentu.
 Bagaimana cara menukar fail XML ke PDF di telefon anda?
Apr 02, 2025 pm 10:12 PM
Bagaimana cara menukar fail XML ke PDF di telefon anda?
Apr 02, 2025 pm 10:12 PM
Tidak mustahil untuk menyelesaikan penukaran XML ke PDF secara langsung di telefon anda dengan satu aplikasi. Ia perlu menggunakan perkhidmatan awan, yang boleh dicapai melalui dua langkah: 1. Tukar XML ke PDF di awan, 2. Akses atau muat turun fail PDF yang ditukar pada telefon bimbit.
 Bagaimana cara menukar XML ke PDF di telefon anda?
Apr 02, 2025 pm 10:18 PM
Bagaimana cara menukar XML ke PDF di telefon anda?
Apr 02, 2025 pm 10:18 PM
Ia tidak mudah untuk menukar XML ke PDF secara langsung pada telefon anda, tetapi ia boleh dicapai dengan bantuan perkhidmatan awan. Adalah disyorkan untuk menggunakan aplikasi mudah alih ringan untuk memuat naik fail XML dan menerima PDF yang dihasilkan, dan menukarnya dengan API awan. API awan menggunakan perkhidmatan pengkomputeran tanpa pelayan, dan memilih platform yang betul adalah penting. Kerumitan, pengendalian kesilapan, keselamatan, dan strategi pengoptimuman perlu dipertimbangkan ketika mengendalikan penjanaan XML dan penjanaan PDF. Seluruh proses memerlukan aplikasi front-end dan API back-end untuk bekerjasama, dan ia memerlukan pemahaman tentang pelbagai teknologi.
