

本文介绍在Android平台中实现对XML的三种解析方式。
XML在各种开发中都广泛应用,Android也不例外。作为承载数据的一个重要角色,如何读写XML成为Android开发中一项重要的技能。
在Android中,常见的XML解析器分别为DOM解析器、SAX解析器和PULL解析器,下面,我将一一向大家详细介绍。
第一种方式:DOM解析器:
DOM是基于树形结构的的节点或信息片段的集合,允许开发人员使用DOM API遍历XML树、检索所需数据。分析该结构通常需要加载整个文档和构造树形结构,然后才可以检索和更新节点信息。Android完全支持DOM 解析。利用DOM中的对象,可以对XML文档进行读取、搜索、修改、添加和删除等操作。
DOM的工作原理:使用DOM对XML文件进行操作时,首先要解析文件,将文件分为独立的元素、属性和注释等,然后以节点树的形式在内存中对XML文件进行表示,就可以通过节点树访问文档的内容,并根据需要修改文档——这就是DOM的工作原理。
DOM实现时首先为XML文档的解析定义一组接口,解析器读入整个文档,然后构造一个驻留内存的树结构,这样代码就可以使用DOM接口来操作整个树结构。
由于DOM在内存中以树形结构存放,因此检索和更新效率会更高。但是对于特别大的文档,解析和加载整个文档将会很耗资源。 当然,如果XML文件的内容比较小,采用DOM是可行的。
常用的DoM接口和类:
Document:该接口定义分析并创建DOM文档的一系列方法,它是文档树的根,是操作DOM的基础。
Element:该接口继承Node接口,提供了获取、修改XML元素名字和属性的方法。
Node:该接口提供处理并获取节点和子节点值的方法。
NodeList:提供获得节点个数和当前节点的方法。这样就可以迭代地访问各个节点。
DOMParser:该类是Apache的Xerces中的DOM解析器类,可直接解析XML文件。
下面是DOM的解析流程:

第二种方式:SAX解析器:
SAX(Simple API for XML)解析器是一种基于事件的解析器,事件驱动的流式解析方式是,从文件的开始顺序解析到文档的结束,不可暂停或倒退。它的核心是事件处理模式,主要是围绕着事件源以及事件处理器来工作的。当事件源产生事件后,调用事件处理器相应的处理方法,一个事件就可以得到处理。在事件源调用事件处理器中特定方法的时候,还要传递给事件处理器相应事件的状态信息,这样事件处理器才能够根据提供的事件信息来决定自己的行为。
SAX解析器的优点是解析速度快,占用内存少。非常适合在Android移动设备中使用。
SAX的工作原理:SAX的工作原理简单地说就是对文档进行顺序扫描,当扫描到文档(document)开始与结束、元素(element)开始与结束、文档(document)结束等地方时通知事件处理函数,由事件处理函数做相应动作,然后继续同样的扫描,直至文档结束。
在SAX接口中,事件源是org.xml.sax包中的XMLReader,它通过parser()方法来解析XML文档,并产生事件。事件处理器是org.xml.sax包中ContentHander、DTDHander、ErrorHandler,以及EntityResolver这4个接口。XMLReader通过相应事件处理器注册方法setXXXX()来完成的与ContentHander、DTDHander、ErrorHandler,以及EntityResolver这4个接口的连接。
常用的SAX接口和类: Attrbutes:用于得到属性的个数、名字和值。 ContentHandler:定义与文档本身关联的事件(例如,开始和结束标记)。大多数应用程序都注册这些事件。 DTDHandler:定义与DTD关联的事件。它没有定义足够的事件来完整地报告DTD。如果需要对DTD进行语法分析,请使用可选的DeclHandler。 DeclHandler是SAX的扩展。不是所有的语法分析器都支持它。 EntityResolver:定义与装入实体关联的事件。只有少数几个应用程序注册这些事件。 ErrorHandler:定义错误事件。许多应用程序注册这些事件以便用它们自己的方式报错。 DefaultHandler:它提供了这些接LI的缺省实现。在大多数情况下,为应用程序扩展DefaultHandler并覆盖相关的方法要比直接实现一个接口更容易。 详见下表: 可知,我们需要XmlReader 以及DefaultHandler来配合解析xml。 下面是SAX的解析流程: 
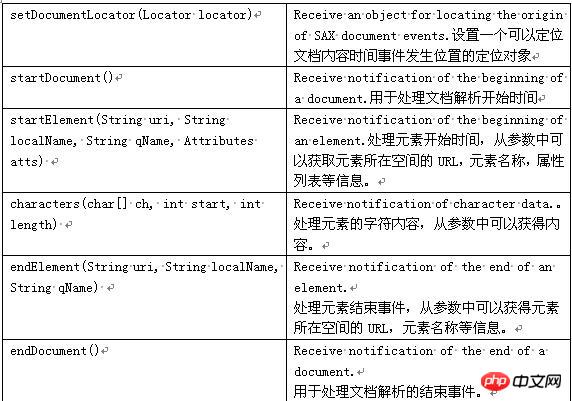

第三种方式:PULL解析器:
Android并未提供对Java StAX API的支持。但是,Android附带了一个pull解析器,其工作方式类似于StAX。它允许用户的应用程序代码从解析器中获取事件,这与SAX解析器自动将事件推入处理程序相反。
PULL解析器的运行方式和SAX类似,都是基于事件的模式。不同的是,在PULL解析过程中返回的是数字,且我们需要自己获取产生的事件然后做相应的操作,而不像SAX那样由处理器触发一种事件的方法,执行我们的代码。
下面是PULL解析XML的过程:
读取到xml的声明返回 START_DOCUMENT;
读取到xml的结束返回 END_DOCUMENT ;
读取到xml的开始标签返回 START_TAG
读取到xml的结束标签返回 END_TAG
读取到xml的文本返回 TEXT
PULL解析器小巧轻便,解析速度快,简单易用,非常适合在Android移动设备中使用,Android系统内部在解析各种XML时也是用PULL解析器,Android官方推荐开发者们使用Pull解析技术。Pull解析技术是第三方开发的开源技术,它同样可以应用于JavaSE开发。
PULL 的工作原理:XML pull提供了开始元素和结束元素。当某个元素开始时,我们可以调用parser.nextText从XML文档中提取所有字符数据。当解释到一个文档结束时,自动生成EndDocument事件。
常用的XML pull的接口和类:
XmlPullParser:XML pull解析器是一个在XMLPULL VlAP1中提供了定义解析功能的接口。
XmlSerializer:它是一个接口,定义了XML信息集的序列。
XmlPullParserFactory:这个类用于在XMPULL V1 API中创建XML Pull解析器。
XmlPullParserException:抛出单一的XML pull解析器相关的错误。
PULL的解析流程如下:
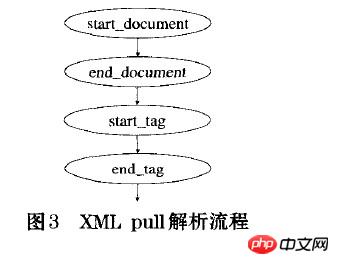
[附加]第四种方式: Android.util.Xml类
在Android API中,另外提供了Android.util.Xml类,同样可以解析XML文件,使用方法类似SAX,也都需编写Handler来处理XML的解析,但是在使用上却比SAX来得简单 ,如下所示:
以android.util.XML实现XML解析 ,
MyHandler myHandler=new MyHandler0;
android.util.Xm1.parse(ur1.openC0nnection().getlnputStream0,Xm1.Encoding.UTF-8,myHandler);
下面是一个参考文档river.xml,放在assets目录.如下:
<?xml version="1.0" encoding="utf-8"?> <rivers> <river name="灵渠" length="605"> <introduction>
灵渠在广西壮族自治区兴安县境内,是世界上最古老的运河之一,有着“世界古代水利建筑明珠”的美誉。灵渠古称秦凿渠、零渠、陡河、兴安运河,于公元前214年凿成通航,距今已2217年,仍然发挥着功用。
</
introduction
>
<
imageurl
>
http://www.php.cn/
</
imageurl
>
</
river
>
<
river
name
="胶莱运河"
length
="200"
>
<
introduction
>
胶莱运河南起黄海灵山海口,北抵渤海三山岛,流经现胶南、胶州、平度、高密、昌邑和莱州等,全长200公里,流域面积达5400平方公里,南北贯穿山东半岛,沟通黄渤两海。胶莱运河自平度姚家村东的分水岭南北分流。南流由麻湾口入胶州湾,为南胶莱河,长30公里。北流由海仓口入莱州湾,为北胶莱河,长100余公里。
</
introduction
>
<
imageurl
>
http://www.php.cn/
</
imageurl
>
</
river
>
<
river
name
="苏北灌溉总渠"
length
="168"
>
<
introduction
>
位于淮河下游江苏省北部,西起洪泽湖边的高良涧,流经洪泽,青浦、淮安,阜宁、射阳,滨海等六县(区),东至扁担港口入海的大型人工河道。全长168km。
</
introduction
>
<
imageurl
>
http://www.php.cn/
</
imageurl
>
</
river
>
</
rivers
>
采用DOM解析时具体处理步骤是:
1 首先利用DocumentBuilderFactory创建一个DocumentBuilderFactory实例
2 然后利用DocumentBuilderFactory创建DocumentBuilder
3 然后加载XML文档(Document),
4 然后获取文档的根结点(Element),
5 然后获取根结点中所有子节点的列表(NodeList),
6 然后使用再获取子节点列表中的需要读取的结点。
当然我们观察节点,我需要用一个River对象来保存数据,抽象出River类
public class River implements Serializable {
privatestaticfinallong serialVersionUID = 1L;
private String name;
public String getName() {
return name; }
public void setName(String name) {
this.name = name; }
public int getLength() {
return length; }
public void setLength(int length) {
this.length = length; }
public String getIntroduction() {
return introduction; }
public void setIntroduction(String introduction) {
this.introduction = introduction; }
public String getImageurl() {
return imageurl; }
public void setImageurl(String imageurl) {
this.imageurl = imageurl; }
private int length;
private String introduction;
private String imageurl; }下面我们就开始读取xml文档对象,并添加进List中:
代码如下: 我们这里是使用assets中的river.xml文件,那么就需要读取这个xml文件,返回输入流。 读取方法为:inputStream=this.context.getResources().getAssets().open(fileName); 参数是xml文件路径,当然默认的是assets目录为根目录。
然后可以用DocumentBuilder对象的parse方法解析输入流,并返回document对象,然后再遍历doument对象的节点属性。
//获取全部河流数据
/**
* 参数fileName:为xml文档路径
*/
public List<River> getRiversFromXml(String fileName){
List<River> rivers=new ArrayList<River>();
DocumentBuilderFactory factory=null;
DocumentBuilder builder=null;
Document document=null;
InputStream inputStream=null;
//首先找到xml文件
factory=DocumentBuilderFactory.newInstance();
try {
//找到xml,并加载文档
builder=factory.newDocumentBuilder();
inputStream=this.context.getResources().getAssets().open(fileName);
document=builder.parse(inputStream);
//找到根Element
Element root=document.getDocumentElement();
NodeList nodes=root.getElementsByTagName(RIVER);
//遍历根节点所有子节点,rivers 下所有river
River river=null;
for(int i=0;i<nodes.getLength();i++){
river=new River();
//获取river元素节点
Element riverElement=(Element)(nodes.item(i));
//获取river中name属性值
river.setName(riverElement.getAttribute(NAME));
river.setLength(Integer.parseInt(riverElement.getAttribute(LENGTH)));
//获取river下introduction标签
Element introduction=(Element)riverElement.getElementsByTagName(INTRODUCTION).item(0);
river.setIntroduction(introduction.getFirstChild().getNodeValue());
Element imageUrl=(Element)riverElement.getElementsByTagName(IMAGEURL).item(0);
river.setImageurl(imageUrl.getFirstChild().getNodeValue());
rivers.add(river);
}
}catch (IOException e){
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
}
catch (ParserConfigurationException e) {
e.printStackTrace();
}finally{
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return rivers;
}
在这里添加到List中, 然后我们使用ListView将他们显示出来。如图所示:
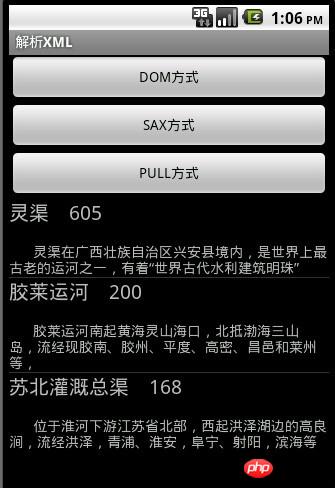
采用SAX解析时具体处理步骤是:
1 创建SAXParserFactory对象
2 根据SAXParserFactory.newSAXParser()方法返回一个SAXParser解析器
3 根据SAXParser解析器获取事件源对象XMLReader
4 实例化一个DefaultHandler对象
5 连接事件源对象XMLReader到事件处理类DefaultHandler中
6 调用XMLReader的parse方法从输入源中获取到的xml数据
7 通过DefaultHandler返回我们需要的数据集合。
代码如下:
public List<River> parse(String xmlPath){
List<River> rivers=null;
SAXParserFactory factory=SAXParserFactory.newInstance();
try {
SAXParser parser=factory.newSAXParser();
//获取事件源
XMLReader xmlReader=parser.getXMLReader();
//设置处理器
RiverHandler handler=new RiverHandler();
xmlReader.setContentHandler(handler);
//解析xml文档
//xmlReader.parse(new InputSource(new URL(xmlPath).openStream()));
xmlReader.parse(new InputSource(this.context.getAssets().open(xmlPath)));
rivers=handler.getRivers();
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return rivers;
}
重点在于DefaultHandler对象中对每一个元素节点,属性,文本内容,文档内容进行处理。
前面说过DefaultHandler是基于事件处理模型的,基本处理方式是:当SAX解析器导航到文档开始标签时回调startDocument方法,导航到文档结束标签时回调endDocument方法。当SAX解析器导航到元素开始标签时回调startElement方法,导航到其文本内容时回调characters方法,导航到标签结束时回调endElement方法。
根据以上的解释,我们可以得出以下处理xml文档逻辑:
1:当导航到文档开始标签时,在回调函数startDocument中,可以不做处理,当然你可以验证下UTF-8等等。
2:当导航到rivers开始标签时,在回调方法startElement中可以实例化一个集合用来存贮list,不过我们这里不用,因为在构造函数中已经实例化了。
3:导航到river开始标签时,就说明需要实例化River对象了,当然river标签中还有name ,length属性,因此实例化River后还必须取出属性值,attributes.getValue(NAME),同时赋予river对象中,同时添加为导航到的river标签添加一个boolean为真的标识,用来说明导航到了river元素。
4:当然有river标签内还有子标签(节点),但是SAX解析器是不知道导航到什么标签的,它只懂得开始,结束而已。那么如何让它认得我们的各个标签呢?当然需要判断了,于是可以使用回调方法startElement中的参数String localName,把我们的标签字符串与这个参数比较下,就可以了。我们还必须让SAX知道,现在导航到的是某个标签,因此添加一个true属性让SAX解析器知道。
5:它还会导航到文本内标签,(就是里面的内容),回调方法characters,我们一般在这个方法中取出就是
里面的内容,并保存。 6:当然它是一定会导航到结束标签 或者的,如果是标签,记得把river对象添加进list中。如果是river中的子标签,就把前面设置标记导航到这个标签的boolean标记设置为false. 按照以上实现思路,可以实现如下代码:
/**导航到开始标签触发**/
publicvoid startElement (String uri, String localName, String qName, Attributes attributes){
String tagName=localName.length()!=0?localName:qName;
tagName=tagName.toLowerCase().trim();
//如果读取的是river标签开始,则实例化River
if(tagName.equals(RIVER)){
isRiver=true;
river=new River();
/**导航到river开始节点后**/
river.setName(attributes.getValue(NAME));
river.setLength(Integer.parseInt(attributes.getValue(LENGTH)));
}
//然后读取其他节点
if(isRiver){
if(tagName.equals(INTRODUCTION)){
xintroduction=true;
}else if(tagName.equals(IMAGEURL)){
ximageurl=true;
}
}
}
/**导航到结束标签触发**/
public void endElement (String uri, String localName, String qName){
String tagName=localName.length()!=0?localName:qName;
tagName=tagName.toLowerCase().trim();
//如果读取的是river标签结束,则把River添加进集合中
if(tagName.equals(RIVER)){
isRiver=true;
rivers.add(river);
}
//然后读取其他节点
if(isRiver){
if(tagName.equals(INTRODUCTION)){
xintroduction=false;
}else if(tagName.equals(IMAGEURL)){
ximageurl=false;
}
}
}
//这里是读取到节点内容时候回调
public void characters (char[] ch, int start, int length){
//设置属性值
if(xintroduction){
//解决null问题
river.setIntroduction(river.getIntroduction()==null?"":river.getIntroduction()+new String(ch,start,length));
}else if(ximageurl){
//解决null问题
river.setImageurl(river.getImageurl()==null?"":river.getImageurl()+new String(ch,start,length));
}
}
运行效果跟上例DOM 运行效果相同。
采用PULL解析基本处理方式:
当PULL解析器导航到文档开始标签时就开始实例化list集合用来存贮数据对象。导航到元素开始标签时回判断元素标签类型,如果是river标签,则需要实例化River对象了,如果是其他类型,则取得该标签内容并赋予River对象。当然它也会导航到文本标签,不过在这里,我们可以不用。
根据以上的解释,我们可以得出以下处理xml文档逻辑:
1:当导航到XmlPullParser.START_DOCUMENT,可以不做处理,当然你可以实例化集合对象等等。
2:当导航到XmlPullParser.START_TAG,则判断是否是river标签,如果是,则实例化river对象,并调用getAttributeValue方法获取标签中属性值。
3:当导航到其他标签,比如Introduction时候,则判断river对象是否为空,如不为空,则取出Introduction中的内容,nextText方法来获取文本节点内容
4:当然啦,它一定会导航到XmlPullParser.END_TAG的,有开始就要有结束嘛。在这里我们就需要判读是否是river结束标签,如果是,则把river对象存进list集合中了,并设置river对象为null.
由以上的处理逻辑,我们可以得出以下代码:
public List<River> parse(String xmlPath){
List<River> rivers=new ArrayList<River>();
River river=null;
InputStream inputStream=null;
//获得XmlPullParser解析器
XmlPullParser xmlParser = Xml.newPullParser();
try {
//得到文件流,并设置编码方式
inputStream=this.context.getResources().getAssets().open(xmlPath);
xmlParser.setInput(inputStream, "utf-8");
//获得解析到的事件类别,这里有开始文档,结束文档,开始标签,结束标签,文本等等事件。
int evtType=xmlParser.getEventType();
//一直循环,直到文档结束
while(evtType!=XmlPullParser.END_DOCUMENT){
switch(evtType){
case XmlPullParser.START_TAG:
String tag = xmlParser.getName();
//如果是river标签开始,则说明需要实例化对象了
if (tag.equalsIgnoreCase(RIVER)) {
river = new River();
//取出river标签中的一些属性值
river.setName(xmlParser.getAttributeValue(null, NAME));
river.setLength(Integer.parseInt(xmlParser.getAttributeValue(null, LENGTH)));
}else if(river!=null){
//如果遇到introduction标签,则读取它内容
if(tag.equalsIgnoreCase(INTRODUCTION)){
river.setIntroduction(xmlParser.nextText());
}else if(tag.equalsIgnoreCase(IMAGEURL)){
river.setImageurl(xmlParser.nextText());
}
}
break;
case XmlPullParser.END_TAG:
//如果遇到river标签结束,则把river对象添加进集合中
if (xmlParser.getName().equalsIgnoreCase(RIVER) && river != null) {
rivers.add(river);
river = null;
}
break;
default:break;
}
//如果xml没有结束,则导航到下一个river节点
evtType=xmlParser.next();
}
} catch (XmlPullParserException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
return rivers;
}运行效果和上面的一样。
几种解析技术的比较与总结:
对于Android的移动设备而言,因为设备的资源比较宝贵,内存是有限的,所以我们需要选择适合的技术来解析XML,这样有利于提高访问的速度。
1 DOM在处理XML文件时,将XML文件解析成树状结构并放入内存中进行处理。当XML文件较小时,我们可以选DOM,因为它简单、直观。
2 SAX则是以事件作为解析XML文件的模式,它将XML文件转化成一系列的事件,由不同的事件处理器来决定如何处理。XML文件较大时,选择SAX技术是比较合理的。虽然代码量有些大,但是它不需要将所有的XML文件加载到内存中。这样对于有限的Android内存更有效,而且Android提供了一种传统的SAX使用方法以及一个便捷的SAX包装器。 使用Android.util.Xml类,从示例中可以看出,会比使用 SAX来得简单。
3 XML pull解析并未像SAX解析那样监听元素的结束,而是在开始处完成了大部分处理。这有利于提早读取XML文件,可以极大的减少解析时间,这种优化对于连接速度较漫的移动设备而言尤为重要。对于XML文档较大但只需要文档的一部分时,XML Pull解析器则是更为有效的方法。
Atas ialah kandungan terperinci 详解Android实现XML解析技术(图). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Tiga rangka kerja utama untuk pembangunan android
Tiga rangka kerja utama untuk pembangunan android
 Apakah sistem android
Apakah sistem android
 Bagaimana untuk membuka kunci sekatan kebenaran android
Bagaimana untuk membuka kunci sekatan kebenaran android
 Apakah kaedah untuk memulakan semula aplikasi dalam Android?
Apakah kaedah untuk memulakan semula aplikasi dalam Android?
 Kaedah pelaksanaan fungsi main balik suara Android
Kaedah pelaksanaan fungsi main balik suara Android
 Bagaimana untuk menukar pdf ke format xml
Bagaimana untuk menukar pdf ke format xml
 Apakah jenis alat laso dalam PS?
Apakah jenis alat laso dalam PS?
 Bagaimana untuk menyediakan VPS selamat
Bagaimana untuk menyediakan VPS selamat








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



