

MySQL分布式集群之MyCAT(二)schema代码详解

在第一部分,有简单的介绍MyCAT的搭建和配置文件的基本情况,这一篇详细介绍schema的一些具体参数,以及实际作用
首先贴上自己测试用的schema文件,双引号之前的反斜杠不会消除,姑且当成不存在吧...
<?xml version=\"1.0\"?>
<!DOCTYPE mycat:schema SYSTEM \"schema.dtd\">
<mycat:schema xmlns:mycat=\"http://org.opencloudb/\">
<schema name=\"mycat\" checkSQLschema=\"false\" sqlMaxLimit=\"100\">
<!-- auto sharding by id (long) -->
<table name=\"students\" dataNode=\"dn1,dn2,dn3,dn4\" rule=\"rule1\" />
<table name=\"log_test\" dataNode=\"dn1,dn2,dn3,dn4\" rule=\"rule2\" />
<!-- global table is auto cloned to all defined data nodes ,so can join
with any table whose sharding node is in the same data node -->
<!--<table name=\"company\" primaryKey=\"ID\" type=\"global\" dataNode=\"dn1,dn2,dn3\" />
<table name=\"goods\" primaryKey=\"ID\" type=\"global\" dataNode=\"dn1,dn2\" />
-->
<table name=\"item_test\" primaryKey=\"ID\" type=\"global\" dataNode=\"dn1,dn2,dn3,dn4\" />
<!-- random sharding using mod sharind rule -->
<!-- <table name=\"hotnews\" primaryKey=\"ID\" dataNode=\"dn1,dn2,dn3\"
rule=\"mod-long\" /> -->
<!--
<table name=\"worker\" primaryKey=\"ID\" dataNode=\"jdbc_dn1,jdbc_dn2,jdbc_dn3\" rule=\"mod-long\" />
-->
<!-- <table name=\"employee\" primaryKey=\"ID\" dataNode=\"dn1,dn2\"
rule=\"sharding-by-intfile\" />
<table name=\"customer\" primaryKey=\"ID\" dataNode=\"dn1,dn2\"
rule=\"sharding-by-intfile\">
<childTable name=\"orders\" primaryKey=\"ID\" joinKey=\"customer_id\"
parentKey=\"id\">
<childTable name=\"order_items\" joinKey=\"order_id\"
parentKey=\"id\" />
<ildTable>
<childTable name=\"customer_addr\" primaryKey=\"ID\" joinKey=\"customer_id\"
parentKey=\"id\" /> -->
</schema>
<!-- <dataNode name=\"dn\" dataHost=\"localhost\" database=\"test\" /> -->
<dataNode name=\"dn1\" dataHost=\"localhost\" database=\"test1\" />
<dataNode name=\"dn2\" dataHost=\"localhost\" database=\"test2\" />
<dataNode name=\"dn3\" dataHost=\"localhost\" database=\"test3\" />
<dataNode name=\"dn4\" dataHost=\"localhost\" database=\"test4\" />
<!--
<dataNode name=\"jdbc_dn1\" dataHost=\"jdbchost\" database=\"db1\" />
<dataNode name=\"jdbc_dn2\" dataHost=\"jdbchost\" database=\"db2\" />
<dataNode name=\"jdbc_dn3\" dataHost=\"jdbchost\" database=\"db3\" />
-->
<dataHost name=\"localhost\" maxCon=\"100\" minCon=\"10\" balance=\"1\"
writeType=\"1\" dbType=\"mysql\" dbDriver=\"native\">
<heartbeat>select user()<beat>
<!-- can have multi write hosts -->
<writeHost host=\"localhost\" url=\"localhost:3306\" user=\"root\" password=\"wangwenan\">
<!-- can have multi read hosts -->
<readHost host=\"hostS1\" url=\"localhost:3307\" user=\"root\" password=\"wangwenan\"/>
</writeHost>
<writeHost host=\"localhost1\" url=\"localhost:3308\" user=\"root\" password=\"wangwenan\">
<!-- can have multi read hosts -->
<readHost host=\"hostS11\" url=\"localhost:3309\" user=\"root\" password=\"wangwenan\"/>
</writeHost>
</dataHost>
<!-- <writeHost host=\"hostM2\" url=\"localhost:3316\" user=\"root\" password=\"123456\"/> -->
<!--
<dataHost name=\"jdbchost\" maxCon=\"1000\" minCon=\"1\" balance=\"0\" writeType=\"0\" dbType=\"mongodb\" dbDriver=\"jdbc\">
<heartbeat>select user()<beat>
<writeHost host=\"hostM\" url=\"mongodb://192.168.0.99/test\" user=\"admin\" password=\"123456\" ></writeHost>
</dataHost>
-->
<!--
<dataHost name=\"jdbchost\" maxCon=\"1000\" minCon=\"10\" balance=\"0\"
dbType=\"mysql\" dbDriver=\"jdbc\">
<heartbeat>select user()<beat>
<writeHost host=\"hostM1\" url=\"jdbc:mysql://localhost:3306\"
user=\"root\" password=\"123456\">
</writeHost>
</dataHost>
-->
</mycat:schema> 第一行参数<schema name="mycat" checkSQLschema="false" sqlMaxLimit="100"/>
在这一行参数里面,schema name定义了可以在MyCAT前端显示的逻辑数据库的名字,
checkSQLschema这个参数为False的时候,表明MyCAT会自动忽略掉表名前的数据库名,比如说mydatabase1.test1,会被当做test1;
sqlMaxLimit指定了SQL语句返回的行数限制;

如截图,这个limit会让MyCAT在分发SQL语句的时候,自动加上一个limit,限制从分库获得的结果的行数,另外,截图右上角可以看到,MyCAT本身也是有缓存的;
那么,如果我们执行的语句要返回较多的数据行,在不修改这个limit的情况下,MyCAT会怎么做?
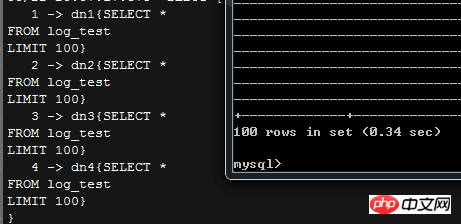
可以从截图看到,MyCAT完全就没搭理前端的实际需求,老老实实返回100条数据,所以如果实际应用里面需要返回大量数据,可能就得手动改逻辑了
MyCAT的1.4版本里面,用户的Limit参数会覆盖掉默认的MyCAT设置
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
<table
name="students" dataNode="dn1,dn2,dn3,dn4" rule="rule1" />
这一行代表在MyCAT前端会显示哪些表名,类似几行都代表一样的意思,这里强调的是表,而MyCAT并不会在配置文件里面定义表结构
如果在前端使用show create table ,MyCAT会显示正常的表结构信息,观察Debug日志,

可以看到,MyCAT把命令分发给了dn1代表的数据库,然后把dn1的查询结果返回给了前端
可以判断,类似的数据库级别的一些查询指令,有可能是单独分发给某个节点,然后再把某个节点的信息返回给前端;
dataNode的意义很简单,这个逻辑表的数据存储在后端的哪几个数据库里面
rule代表的是这个逻辑表students的具体切分策略,目前MyCAT只支持按照某一个特殊列,遵循一些特殊的规则来切分,如取模,枚举等,具体的留给之后细说
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
<table
name="item_test" primaryKey="ID" type="global" dataNode="dn1,dn2,dn3,dn4" />
这一行代表的是全局表,这意味着,item_test这张表会在四个dataNode里面都保存有完整的数据副本,那么查询的时候还会分发到所有的数据库么?
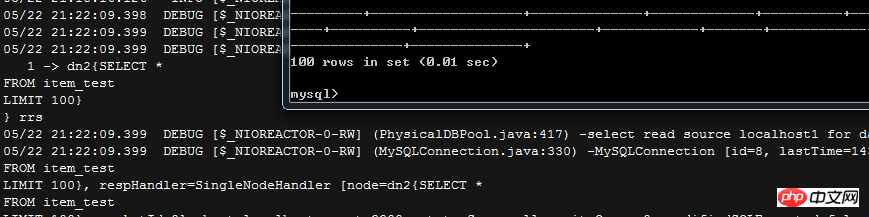
结果如截图,MyCAT依然是规规矩矩的返回了100条数据(╮(╯_╰)╭),而针对全局表的查询,只会分发到某一个节点上
配置的primaryKey没发现作用在哪里,姑且忽略吧,以后发现了再补上
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
childtable我在测试中并没有实际用起来不过在MyCAT的设计文档里面有提到,childtable是一种依赖于父表的结构,
这意味着,childtable的joinkey会按照父表的parentKey的策略一起切分,当父表与子表进行连接,且连接条件是childtable.joinKey=parenttable.parentKey时,不会进行跨库的连接.
PS:具体测试以后再补
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
dataNode的参数在之前的篇章介绍过,这里直接跳过~
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
dataHost配置的是实际的后端数据库集群,大部分参数简单易懂,这里就不一个个介绍了,只介绍比较重要的两个参数,writeType和balance.
writeType和balance是用来控制后端集群的读写分离的关键参数,这里我用了双主双从的集群配置
这里的测试过程比较麻烦,所以直接贴结论:
1.balance=0时,读操作都在localhost上(localhost失败时,后端直接失败)
2.balance=1时,读操作会随机分散在localhost1和两个readhost上面(localhost失败时,写操作会在localhost1,如果localhost1再失败,则无法进行写操作)
3.balance=2时,写操作会在localhost上,读操作会随机分散在localhost1,localhost1和两个readhost上面(同上)
4.writeType=0时,写操作会在localhost上,如果localhost失败,会自动切换到localhost1,localhost恢复以后并不会切换回localhost进行写操作
5.writeType=1时,写操作会随机分布在localhost和localhost1上,单点失败并不会影响集群的写操作,但是后端的从库会无法从挂掉的主库获取更新,会在读数据的时候出现数据不一致
举例:localhost失败了,写操作会在localhost1上面进行,localhost1的主从正常运行,但是localhost的从库无法从localhost获取更新,localhost的从库于其他库出现数据不一致
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
实际上,MyCAT本身的读写分离是基于后端集群的同步来实现的,而MyCAT本身则提供语句的分发功能,当然,那个sqlLimit的限制也使得MyCAT会对前端应用层的逻辑造成一些影响
由schema到table的配置,则显示出MyCAT本身的逻辑结构里面,就包含了分库分表的这种特性(可以指定不同的表存在于不同的数据库中,而不必分到全部数据库)
Atas ialah kandungan terperinci MySQL分布式集群之MyCAT(二)schema代码详解. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Mysql: Konsep mudah untuk pembelajaran mudah
Apr 10, 2025 am 09:29 AM
Mysql: Konsep mudah untuk pembelajaran mudah
Apr 10, 2025 am 09:29 AM
MySQL adalah sistem pengurusan pangkalan data sumber terbuka. 1) Buat Pangkalan Data dan Jadual: Gunakan perintah Createdatabase dan Createtable. 2) Operasi Asas: Masukkan, Kemas kini, Padam dan Pilih. 3) Operasi lanjutan: Sertai, subquery dan pemprosesan transaksi. 4) Kemahiran Debugging: Semak sintaks, jenis data dan keizinan. 5) Cadangan Pengoptimuman: Gunakan indeks, elakkan pilih* dan gunakan transaksi.
 Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Anda boleh membuka phpmyadmin melalui langkah -langkah berikut: 1. Log masuk ke panel kawalan laman web; 2. Cari dan klik ikon phpmyadmin; 3. Masukkan kelayakan MySQL; 4. Klik "Login".
 Cara Membuat Premium Navicat
Apr 09, 2025 am 07:09 AM
Cara Membuat Premium Navicat
Apr 09, 2025 am 07:09 AM
Buat pangkalan data menggunakan Navicat Premium: Sambungkan ke pelayan pangkalan data dan masukkan parameter sambungan. Klik kanan pada pelayan dan pilih Buat Pangkalan Data. Masukkan nama pangkalan data baru dan set aksara yang ditentukan dan pengumpulan. Sambung ke pangkalan data baru dan buat jadual dalam penyemak imbas objek. Klik kanan di atas meja dan pilih masukkan data untuk memasukkan data.
 MySQL dan SQL: Kemahiran Penting untuk Pemaju
Apr 10, 2025 am 09:30 AM
MySQL dan SQL: Kemahiran Penting untuk Pemaju
Apr 10, 2025 am 09:30 AM
MySQL dan SQL adalah kemahiran penting untuk pemaju. 1.MYSQL adalah sistem pengurusan pangkalan data sumber terbuka, dan SQL adalah bahasa standard yang digunakan untuk mengurus dan mengendalikan pangkalan data. 2.MYSQL menyokong pelbagai enjin penyimpanan melalui penyimpanan data yang cekap dan fungsi pengambilan semula, dan SQL melengkapkan operasi data yang kompleks melalui pernyataan mudah. 3. Contoh penggunaan termasuk pertanyaan asas dan pertanyaan lanjutan, seperti penapisan dan penyortiran mengikut keadaan. 4. Kesilapan umum termasuk kesilapan sintaks dan isu -isu prestasi, yang boleh dioptimumkan dengan memeriksa penyataan SQL dan menggunakan perintah menjelaskan. 5. Teknik pengoptimuman prestasi termasuk menggunakan indeks, mengelakkan pengimbasan jadual penuh, mengoptimumkan operasi menyertai dan meningkatkan kebolehbacaan kod.
 Cara Membuat Sambungan Baru ke MySQL di Navicat
Apr 09, 2025 am 07:21 AM
Cara Membuat Sambungan Baru ke MySQL di Navicat
Apr 09, 2025 am 07:21 AM
Anda boleh membuat sambungan MySQL baru di Navicat dengan mengikuti langkah -langkah: Buka aplikasi dan pilih Sambungan Baru (Ctrl N). Pilih "MySQL" sebagai jenis sambungan. Masukkan nama host/alamat IP, port, nama pengguna, dan kata laluan. (Pilihan) Konfigurasikan pilihan lanjutan. Simpan sambungan dan masukkan nama sambungan.
 Cara Memulihkan Data Selepas SQL Memadam Barisan
Apr 09, 2025 pm 12:21 PM
Cara Memulihkan Data Selepas SQL Memadam Barisan
Apr 09, 2025 pm 12:21 PM
Memulihkan baris yang dipadam secara langsung dari pangkalan data biasanya mustahil melainkan ada mekanisme sandaran atau transaksi. Titik Utama: Rollback Transaksi: Jalankan balik balik sebelum urus niaga komited untuk memulihkan data. Sandaran: Sandaran biasa pangkalan data boleh digunakan untuk memulihkan data dengan cepat. Snapshot Pangkalan Data: Anda boleh membuat salinan bacaan pangkalan data dan memulihkan data selepas data dipadam secara tidak sengaja. Gunakan Pernyataan Padam dengan berhati -hati: Periksa syarat -syarat dengan teliti untuk mengelakkan data yang tidak sengaja memadamkan. Gunakan klausa WHERE: Secara jelas menentukan data yang akan dipadam. Gunakan Persekitaran Ujian: Ujian Sebelum Melaksanakan Operasi Padam.
 Cara menggunakan redis berulir tunggal
Apr 10, 2025 pm 07:12 PM
Cara menggunakan redis berulir tunggal
Apr 10, 2025 pm 07:12 PM
Redis menggunakan satu seni bina berulir untuk memberikan prestasi tinggi, kesederhanaan, dan konsistensi. Ia menggunakan I/O multiplexing, gelung acara, I/O yang tidak menyekat, dan memori bersama untuk meningkatkan keserasian, tetapi dengan batasan batasan konkurensi, satu titik kegagalan, dan tidak sesuai untuk beban kerja yang berintensifkan.
 PHPMyAdmin Connection MySQL
Apr 10, 2025 pm 10:57 PM
PHPMyAdmin Connection MySQL
Apr 10, 2025 pm 10:57 PM
Bagaimana untuk menyambung ke MySQL menggunakan phpmyadmin? URL untuk mengakses phpmyadmin biasanya http: // localhost/phpmyadmin atau http: // [alamat ip pelayan anda]/phpmyadmin. Masukkan nama pengguna dan kata laluan MySQL anda. Pilih pangkalan data yang ingin anda sambungkan. Klik butang "Sambungan" untuk membuat sambungan.
