

高性能MySQL-创建高性能的索引详解(图文)

本文是关于创建索引的的内容:
(1) 索引的类型
(2)索引的优点
(3)优化索引的策略
这里给出一个索引的思维导图: 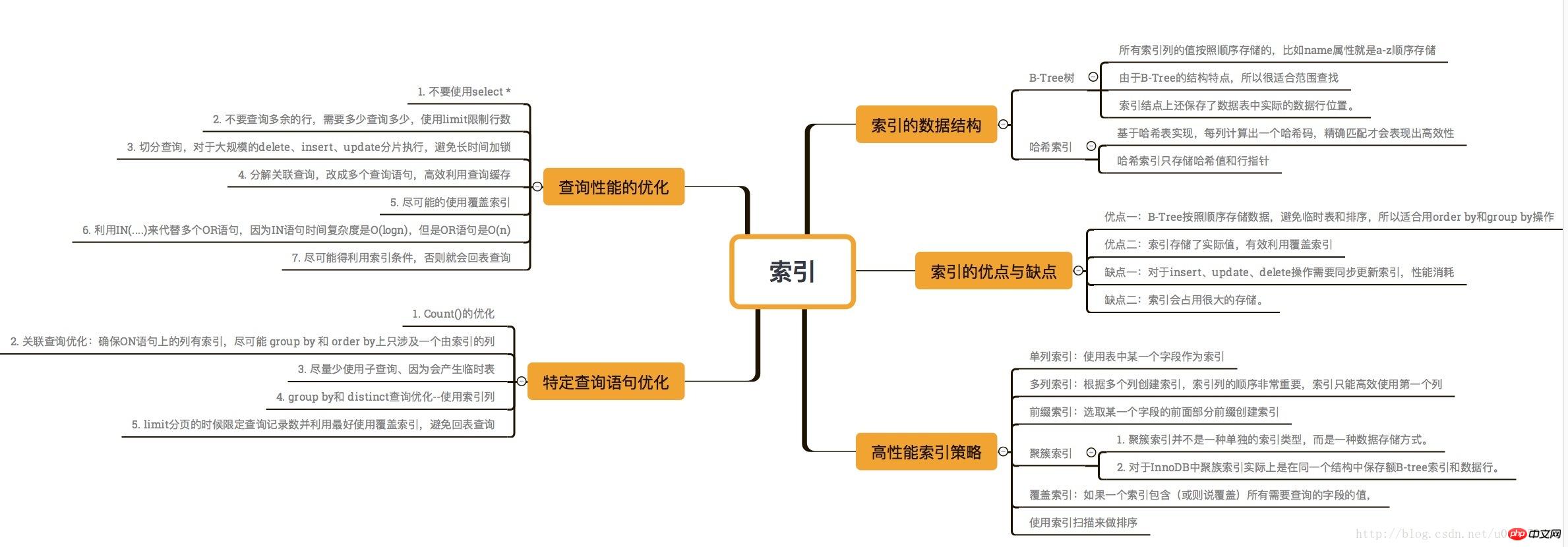
索引是存储引擎用于快速找到记录的一种数据结构。索引是对 查询性能优化 最有效的手段了,索引能够轻松将查询性能提升几个数量级。索引我们一般都是对某一列加索引。
存储引擎先在索引中找到对应值,然后根据匹配的索引记录上的rowid找到对应的数据行。比如运行如下查询语句:
SELECT first_name from actor where actor_id=5;
如果在actor_id列上建立有索引, MySQL将使用该索引找到actor_id 为5对应的行,也就是说,MySQL先在索引上按值查找,然后返回所有包含该值的数据行。
索引可以包含一个或则多个列的值,如果索引包含多个列,那么列的顺序也十分重要,因为MySQL只能高效的使用索引的最左前缀列。创建一个包含两个列的索引和创建两个包含包含一个列的索引是大不相同的。
1.索引数据结构的类型:
索引最常见的是B-Tree索引和哈希索引。
(1)B-Tree树索引
一般情况下索引都是指B-Tree索引,它使用B-Tree数据结构来存储数据。实际上其实是基于B+Tree实现的,在每个叶子结点都包含一个指向下一个叶子结点的指针。
B-Tree意味着所有的值都是按照顺序存储的,比如对于name属性,就是按照从a-z的顺序存储的。使用B-Tree索引后,存储引擎不再需要进行全表扫描来获取需要的数据,而是从索引的根节点开始进行搜索,最终结果是要么找到对应的值,要么记录不存在。这样就能够加快访问数据的速度。
B-Tree对索引列是顺序组织存储的,所以很适合查找范围数据。(比如查找I-k开头的名字,这样效率会很高)
B-Tree索引适合的查询类型
(1) 全值匹配:和索引中的所有列进行匹配。
(2)匹配最左前缀:对于一个索引包含多个列,只使用索引的第一列。
(3)匹配列前缀:匹配某一列的值的开头部分。(比如匹配name字段的时候,只匹配以J开头的姓名)这里只用到了索引的第一列。
(4)匹配范围值:匹配字段在某一个范围内的记录,这里只用到了索引的第一列。
(5)精确匹配某一列并范围匹配另外一列:对于一个索引包含多个字段的情况,比如精确匹配第一列,第二列范围匹配。
(6)只访问索引的查询:之访问索引行而不访问记录中其余字段的数据行。
上面的范围匹配,主要是因为索引的按顺序存储索引列,导致的范围匹配的高效性。
对于B-Tree的索引也有一些限制:
(1)索引只能从最左列开始查找
(2)如果查询中有某个列的范围查找,则其右边所有列都无法使用索引优化。
看到上面的两个限制应该就能明白关于索引中包含多个列的时候,索引列的顺序是很重要的。
(2)Hash哈希索引
哈希索引是基于哈希表实现的,只有精确匹配索引所有列的查询才有效。对于每一行数据存储引擎都会所有的索引列计算一个哈希码,哈希码是一个较小的值,并且不同键值的行计算出来的哈希码也不一样。
1)哈希索引只存储哈希值和行指针,并不存储具体的字段值,所以一定会存在读取行的过程。
2)哈希索引并不是按照索引值顺序存储的,所以就无法用于排序。
3)哈希索引只支持等值比较查询,不支持范围比较查询,这与哈希表的特性与有关。
4)哈希索引就存在哈希冲突的问题,对于哈希冲突的数据必须遍历链表中的所有行指针。
上面的这些限制,哈希索引只适合于特定的场合,但是一旦适合哈希索引,性能就会特别高。
使用hash索引时,一般情况下还要再查询条件中带上hash前的值,比如:
mysql>select * from words where crc=crc32(‘gnu’) and word=’gnu’;
这里crc字段就是word字段哈希之后的值,因为hash之后可能存在冲突,带上原本的值做上二次比较,就可以精确定位。
2.索引的优点:
索引可以让服务器快速定位到表的指定位置。但是这不是唯一的作用,比如:
(1)对于B-Tree索引,由于B-Tree是按照顺序存储数据的,所以用来做order by 操作或则是 group by操作的效率很高。
(2)因为索引中存储了实际的列值,所以某些查询只需要索引就可以完成全部查询。
总结来说就是3点:
(1)索引大大减少服务器需要扫描的数据量;
(2)索引可以帮助服务器避免排序和临时表;
(3)索引可以将随机IO变为排序IO。
3.高性能的索引策略
先概括一下索引的策略:
1)单列索引
2)多列索引
3)前缀索引
4)聚簇索引
5)覆盖索引
单列索引
所谓单列索引是指:使用数据表字段中的某一列作为索引。但是索引列不能是表达式的一部分,也不能是函数的参数。
比如对于下面的一个例子:
select actor_id from actor where actor_id+1=5;
对于这样的一个SQL,where语句后面 是一个表达式,其实很明显是actor_id=4的条件,但是MySQL却无法解析,索引无法正却使用索引。
还有一种是函数参数:也是无法正常的使用索引的
select ... where TO_DAYS(CURRENT_DATE) - TO_DAYS(date_col)<=10;
多列索引以及选择合适的索引顺序
注意这里要区分:为每个列创建独立的索引和为多个列创建一个索引的区别。
比如下面这种情况:
CREATE TABLE t{
c1 int,
c2 int,
c3 int,key(c1),key(c2),key(c3)
}这一种就是为表中的3个列都创建了索引。
但是多个列创建索引就是:创建了一个索引,包含customer_id,和staff_id
alter table payment add KEY(customer_id, staff_id);
上面这个索引其实是包含了两个索引,一个是customer_id这个索引,还有一个是(customer_id,staff_id)。注意staff_id并不能作为单独的索引使用。
对于多列索引,最重要的就是怎么选择索引列的顺序,其实这一点与实际的查询需求有关。主要是为了满足排序和分组。
先从数据结构层次来分析,我们知道索引是以B-Tree的形式存储的,在一个多列索引列中,索引的顺序意味着索引首先按照最左列进行排序,其次是第二列。所以对于一个多列索引,如果以第二列或则第三列直接作为索引,基本是没有用到索引。由于索引的有序性很好的满足了order by、group by和distinct等子句的查询需求。
从上面的分析我们就能认识到多列索引中列的顺序是多么重要。关于多列索引中有一点经验法则:
(1)在不需要考虑排序和分组时,通常情况下将选择性最高的列放在索引最前列。(这时候索引只需要优化where查询条件,能够很快过滤出需要的行)
索引列的选择性定义:不重复的索引值和数据表的记录总数的比值。索引的选择性越高也就是查询效率越高。比如对于人员信息表,phone这一字段的选择性是很高的,几乎为1,但是对于sex性别这一字段的选择性是非常低的,因为只有两个选择男或则是女,几乎为0。
(2)实际情况下也与数据的分布有很大关系。
以下面的查询为例:
SELECT * FROM item WHERE staff_id=2 AND customer_id=584;
这时候应该创建(staff_id, customer_id)的索引还是应该创建(customer_id,staff_id)的索引呢?这时候就应该确认一下那个字段的选择性更高,先查询一下staff_id和customer_id的总数,哪个小就将哪个放在前面。
前缀索引
前缀索引:有时候需要索引的列可能会很长,这时候会导致索引大而且很慢,我们可以只索引列开始的部分(也就是只索引某一列的前面几个字符),这样可以大大节省索引空间也能加快索引的速度,但是也会降低索引的选择性(也就是索引查出来的结果会变多)。
使用的技巧在于:选择足够长的前缀保证较高的选择性,同时又不能太长,避免占用太多的存储空间。
聚簇索引
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。这里主要以InnoDB为例来说明聚簇索引。
InnoDB中聚族索引实际上是在同一个结构中保存额B-tree索引和数据行。当表中有聚族索引时,它的数据行实际上是存放在索引的叶子页中。聚簇的含义实际上就是数据行和相邻的B-Tree中键值紧凑的存储在一起。数据行只能存放在一个地方,所以聚簇索引只能有一个。
下面以一个示例图来说明:索引列是整数值,叶子页包含了行的全部数据,但是结点页只包含了索引列(下图中的整型值)。
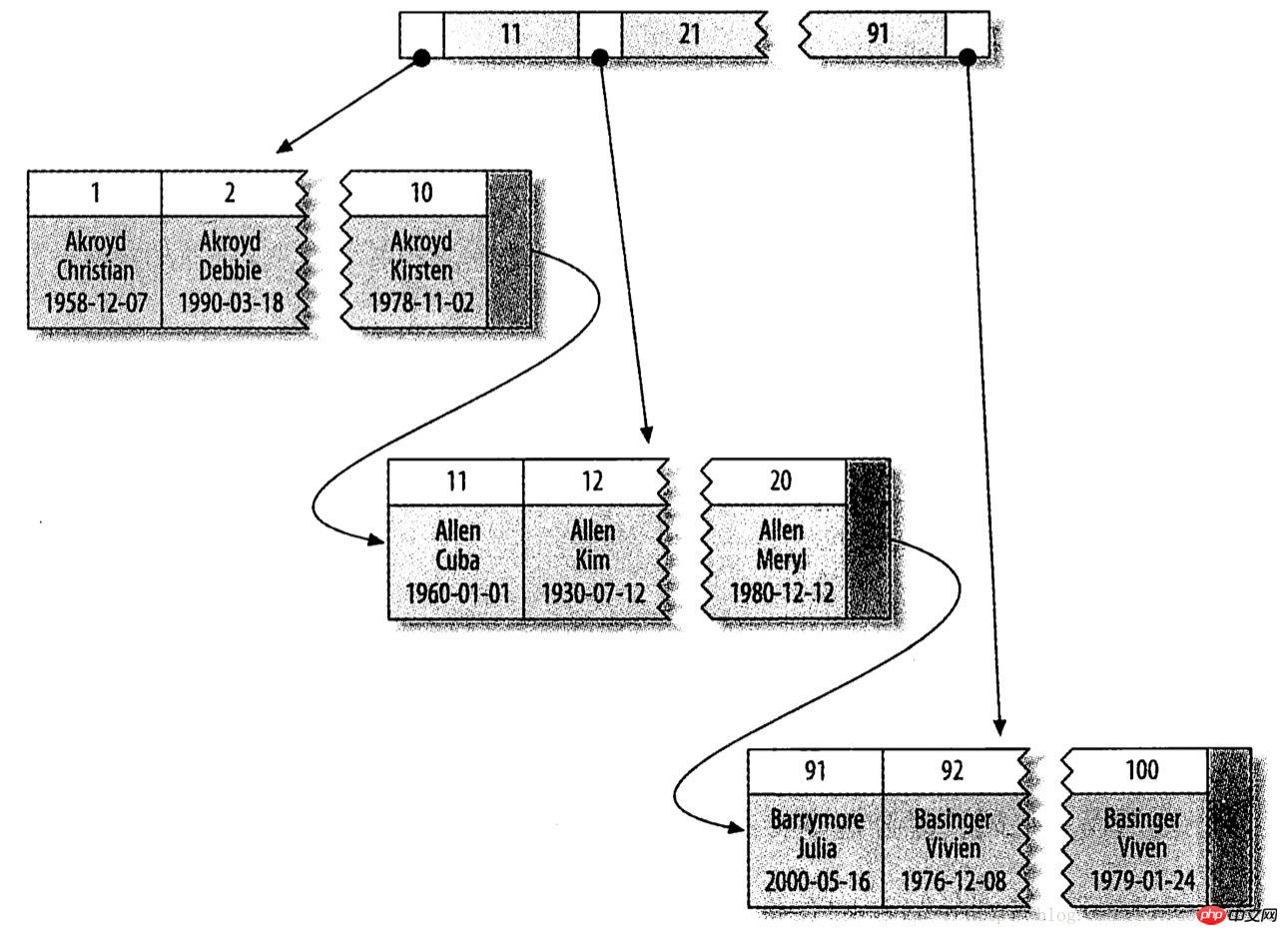
在目前为止的MySQL版本中,InnoDB的聚簇索引还只支持使用主键来聚簇数据。如果没有定义主键,InnoDB会选择一个唯一的非空索引来替代。
聚簇的数据的优点:
(1)可以把相关数据保存在一起。比如查询电子邮箱邮件为例,以用户ID为主键,通过用户ID聚簇数据,这样只需要从磁盘读取少量数据页就能获取某个用户全部邮件。
(2)数据访问更快。聚簇索引将索引和数据保存在一个B-Tree中,因此从聚簇索引中获取数据通常比如同索引查找的快。(当然存在查找列就是索引列的情况)
(3)使用覆盖索引扫描的查询可以直接使用页结点中的主键。
利用查询和设计表时上面的优点能够极大的提升性能,但是也有一些缺点:
(1)聚簇数据极大提升了IO密集型应用的性能,但是数据全部放在内存中,访问的顺序就不重要了,聚簇索引也就失去了优势。
(2)插入速度严重依赖插入顺序。
(3)更新聚簇索引列的代价很高,会强制把InnoDB每个被更新的行移动到新的位置。
覆盖索引
如果一个索引包含(或则说覆盖)所有需要查询的字段的值,我们就称之为覆盖索引。
覆盖索引是非常有用的工具,对于索引来说,只需要扫描索引就能在索引的叶子节点中获得所有的数据,而不需要回表查询,这就能极大的提高性能。带来的好处也很多:
(1)索引条目通常远远小于数据行的大小,如果只需要读取索引那MySQL就会极大的减少数据访问量,这对缓存的负载非常重要。
(2)因为索引是按照列值顺序存储的,所以对于IO密集型的范围查找会比随机从磁盘中读取每一行数据的Io要少得多、
使用索引扫描来做排序
MySQL有两种方式可以生成有序的结果:
(1)通过order by 排序操作;
(2)按索引顺序扫描;
如果explain出来的type值是index,则说明MySQL使用了索引扫描来做排序。
索引扫描本身很快,只需要从一条记录往下一条记录移动即可,但是如果索引列不能覆盖所有查询字段,那么每次扫描一条索引记录都要回表查询一次,其性能还不如直接顺序全表扫描。
尽可能设计同一索引即满足排序又可用于查找。
4.索引的缺点
(1)对于insert、update、delete操作,需要同步更新索引,导致速度变慢。
(2)索引会占用很大的存储。
Atas ialah kandungan terperinci 高性能MySQL-创建高性能的索引详解(图文). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Kemahiran pemprosesan struktur data besar PHP
May 08, 2024 am 10:24 AM
Kemahiran pemprosesan struktur data besar PHP
May 08, 2024 am 10:24 AM
Kemahiran pemprosesan struktur data besar: Pecahan: Pecahkan set data dan proseskannya dalam bahagian untuk mengurangkan penggunaan memori. Penjana: Hasilkan item data satu demi satu tanpa memuatkan keseluruhan set data, sesuai untuk set data tanpa had. Penstriman: Baca fail atau hasil pertanyaan baris demi baris, sesuai untuk fail besar atau data jauh. Storan luaran: Untuk set data yang sangat besar, simpan data dalam pangkalan data atau NoSQL.
 Bagaimana untuk mengoptimumkan prestasi pertanyaan MySQL dalam PHP?
Jun 03, 2024 pm 08:11 PM
Bagaimana untuk mengoptimumkan prestasi pertanyaan MySQL dalam PHP?
Jun 03, 2024 pm 08:11 PM
Prestasi pertanyaan MySQL boleh dioptimumkan dengan membina indeks yang mengurangkan masa carian daripada kerumitan linear kepada kerumitan logaritma. Gunakan PreparedStatements untuk menghalang suntikan SQL dan meningkatkan prestasi pertanyaan. Hadkan hasil pertanyaan dan kurangkan jumlah data yang diproses oleh pelayan. Optimumkan pertanyaan penyertaan, termasuk menggunakan jenis gabungan yang sesuai, membuat indeks dan mempertimbangkan untuk menggunakan subkueri. Menganalisis pertanyaan untuk mengenal pasti kesesakan; gunakan caching untuk mengurangkan beban pangkalan data;
 Bagaimana untuk menggunakan sandaran dan pemulihan MySQL dalam PHP?
Jun 03, 2024 pm 12:19 PM
Bagaimana untuk menggunakan sandaran dan pemulihan MySQL dalam PHP?
Jun 03, 2024 pm 12:19 PM
Membuat sandaran dan memulihkan pangkalan data MySQL dalam PHP boleh dicapai dengan mengikuti langkah berikut: Sandarkan pangkalan data: Gunakan arahan mysqldump untuk membuang pangkalan data ke dalam fail SQL. Pulihkan pangkalan data: Gunakan arahan mysql untuk memulihkan pangkalan data daripada fail SQL.
 Bagaimana untuk memasukkan data ke dalam jadual MySQL menggunakan PHP?
Jun 02, 2024 pm 02:26 PM
Bagaimana untuk memasukkan data ke dalam jadual MySQL menggunakan PHP?
Jun 02, 2024 pm 02:26 PM
Bagaimana untuk memasukkan data ke dalam jadual MySQL? Sambung ke pangkalan data: Gunakan mysqli untuk mewujudkan sambungan ke pangkalan data. Sediakan pertanyaan SQL: Tulis pernyataan INSERT untuk menentukan lajur dan nilai yang akan dimasukkan. Laksanakan pertanyaan: Gunakan kaedah query() untuk melaksanakan pertanyaan sisipan Jika berjaya, mesej pengesahan akan dikeluarkan.
 Bagaimana untuk membetulkan ralat mysql_native_password tidak dimuatkan pada MySQL 8.4
Dec 09, 2024 am 11:42 AM
Bagaimana untuk membetulkan ralat mysql_native_password tidak dimuatkan pada MySQL 8.4
Dec 09, 2024 am 11:42 AM
Salah satu perubahan utama yang diperkenalkan dalam MySQL 8.4 (keluaran LTS terkini pada 2024) ialah pemalam "Kata Laluan Asli MySQL" tidak lagi didayakan secara lalai. Selanjutnya, MySQL 9.0 mengalih keluar pemalam ini sepenuhnya. Perubahan ini mempengaruhi PHP dan apl lain
 Bagaimana untuk menggunakan prosedur tersimpan MySQL dalam PHP?
Jun 02, 2024 pm 02:13 PM
Bagaimana untuk menggunakan prosedur tersimpan MySQL dalam PHP?
Jun 02, 2024 pm 02:13 PM
Untuk menggunakan prosedur tersimpan MySQL dalam PHP: Gunakan PDO atau sambungan MySQLi untuk menyambung ke pangkalan data MySQL. Sediakan penyata untuk memanggil prosedur tersimpan. Laksanakan prosedur tersimpan. Proses set keputusan (jika prosedur tersimpan mengembalikan hasil). Tutup sambungan pangkalan data.
 Bagaimana untuk membuat jadual MySQL menggunakan PHP?
Jun 04, 2024 pm 01:57 PM
Bagaimana untuk membuat jadual MySQL menggunakan PHP?
Jun 04, 2024 pm 01:57 PM
Mencipta jadual MySQL menggunakan PHP memerlukan langkah berikut: Sambung ke pangkalan data. Buat pangkalan data jika ia tidak wujud. Pilih pangkalan data. Buat jadual. Laksanakan pertanyaan. Tutup sambungan.
 Perbezaan antara pangkalan data oracle dan mysql
May 10, 2024 am 01:54 AM
Perbezaan antara pangkalan data oracle dan mysql
May 10, 2024 am 01:54 AM
Pangkalan data Oracle dan MySQL adalah kedua-dua pangkalan data berdasarkan model hubungan, tetapi Oracle lebih unggul dari segi keserasian, skalabiliti, jenis data dan keselamatan manakala MySQL memfokuskan pada kelajuan dan fleksibiliti dan lebih sesuai untuk set data bersaiz kecil. ① Oracle menyediakan pelbagai jenis data, ② menyediakan ciri keselamatan lanjutan, ③ sesuai untuk aplikasi peringkat perusahaan ① MySQL menyokong jenis data NoSQL, ② mempunyai langkah keselamatan yang lebih sedikit, dan ③ sesuai untuk aplikasi bersaiz kecil hingga sederhana.
