

pandas库介绍之DataFrame基本操作

怎样删除list中空字符?
最简单的方法:new_list = [ x for x in li if x != '' ]
今天是5.1号。
这一部分主要学习pandas中基于前面两种数据结构的基本操作。
设有DataFrame结果的数据a如下所示: a b c one 4 1 1 two 6 2 0 three 6 1 6
一、查看数据(查看对象的方法对于Series来说同样适用)
1.查看DataFrame前xx行或后xx行
a=DataFrame(data);
a.head(6)表示显示前6行数据,若head()中不带参数则会显示全部数据。
a.tail(6)表示显示后6行数据,若tail()中不带参数则也会显示全部数据。
2.查看DataFrame的index,columns以及values
a.index ; a.columns ; a.values 即可
3.describe()函数对于数据的快速统计汇总
a.describe()对每一列数据进行统计,包括计数,均值,std,各个分位数等。
4.对数据的转置
a.T
5.对轴进行排序
a.sort_index(axis=1,ascending=False);
其中axis=1表示对所有的columns进行排序,下面的数也跟着发生移动。后面的ascending=False表示按降序排列,参数缺失时默认升序。
6.对DataFrame中的值排序
a.sort(columns='x')
即对a中的x这一列,从小到大进行排序。注意仅仅是x这一列,而上面的按轴进行排序时会对所有的columns进行操作。
二、选择对象
1.选择特定列和行的数据
a['x'] 那么将会返回columns为x的列,注意这种方式一次只能返回一个列。a.x与a['x']意思一样。
取行数据,通过切片[]来选择
如:a[0:3] 则会返回前三行的数据。
2.loc是通过标签来选择数据
a.loc['one']则会默认表示选取行为'one'的行;
a.loc[:,['a','b'] ] 表示选取所有的行以及columns为a,b的列;
a.loc[['one','two'],['a','b']] 表示选取'one'和'two'这两行以及columns为a,b的列;
a.loc['one','a']与a.loc[['one'],['a']]作用是一样的,不过前者只显示对应的值,而后者会显示对应的行和列标签。
3.iloc则是直接通过位置来选择数据
这与通过标签选择类似
a.iloc[1:2,1:2] 则会显示第一行第一列的数据;(切片后面的值取不到)
a.iloc[1:2] 即后面表示列的值没有时,默认选取行位置为1的数据;
a.iloc[[0,2],[1,2]] 即可以自由选取行位置,和列位置对应的数据。
4.使用条件来选择
使用单独的列来选择数据
a[a.c>0] 表示选择c列中大于0的数据
使用where来选择数据
a[a>0] 表直接选择a中所有大于0的数据
使用isin()选出特定列中包含特定值的行
a1=a.copy()
a1[a1['one'].isin(['2','3'])] 表显示满足条件:列one中的值包含'2','3'的所有行。
三、设置值(赋值)
赋值操作在上述选择操作的基础上直接赋值即可。
例a.loc[:,['a','c']]=9 即将a和c列的所有行中的值设置为9
a.iloc[:,[1,3]]=9 也表示将a和c列的所有行中的值设置为9
同时也依然可以用条件来直接赋值
a[a>0]=-a 表示将a中所有大于0的数转化为负值
四、缺失值处理
在pandas中,使用np.nan来代替缺失值,这些值将默认不会包含在计算中。
1.reindex()方法
用来对指定轴上的索引进行改变/增加/删除操作,这将返回原始数据的一个拷贝。
a.reindex(index=list(a.index)+['five'],columns=list(a.columns)+['d'])
a.reindex(index=['one','five'],columns=list(a.columns)+['d'])
即用index=[]表示对index进行操作,columns表对列进行操作。
2.对缺失值进行填充
a.fillna(value=x)
表示用值为x的数来对缺失值进行填充
3.去掉包含缺失值的行
a.dropna(how='any')
表示去掉所有包含缺失值的行
五、合并
1.contact
contact(a1,axis=0/1,keys=['xx','xx','xx',...]),其中a1表示要进行进行连接的列表数据,axis=1时表横着对数据进行连接。axis=0或不指定时,表将数据竖着进行连接。a1中要连接的数据有几个则对应几个keys,设置keys是为了在数据连接以后区分每一个原始a1中的数据。
例:a1=[b['a'],b['c']]
result=pd.concat(a1,axis=1,keys=['1','2'])
2.Append 将一行或多行数据连接到一个DataFrame上
a.append(a[2:],ignore_index=True)
表示将a中的第三行以后的数据全部添加到a中,若不指定ignore_index参数,则会把添加的数据的index保留下来,若ignore_index=Ture则会对所有的行重新自动建立索引。
3.merge类似于SQL中的join
设a1,a2为两个dataframe,二者中存在相同的键值,两个对象连接的方式有下面几种:
(1)内连接,pd.merge(a1, a2, on='key')
(2)左连接,pd.merge(a1, a2, on='key', how='left')
(3)右连接,pd.merge(a1, a2, on='key', how='right')
(4)外连接, pd.merge(a1, a2, on='key', how='outer')
至于四者的具体差别,具体学习参考sql中相应的语法。
六、分组(groupby)
用pd.date_range函数生成连续指定天数的的日期
pd.date_range('20000101',periods=10)
def shuju():
data={
'date':pd.date_range('20000101',periods=10),
'gender':np.random.randint(0,2,size=10),
'height':np.random.randint(40,50,size=10),
'weight':np.random.randint(150,180,size=10)
}
a=DataFrame(data)
print(a)
date gender height weight
0 2000-01-01 0 47 165
1 2000-01-02 0 46 179
2 2000-01-03 1 48 172
3 2000-01-04 0 45 173
4 2000-01-05 1 47 151
5 2000-01-06 0 45 172
6 2000-01-07 0 48 167
7 2000-01-08 0 45 157
8 2000-01-09 1 42 157
9 2000-01-10 1 42 164
用a.groupby('gender').sum()得到的结果为: #注意在python中groupby(''xx)后要加sum(),不然显示
不了数据对象。
gender height weight
0 256 989
1 170 643此外用a.groupby('gender').size()可以对各个gender下的数目进行计数。
所以可以看到groupby的作用相当于:
按gender对gender进行分类,对应为数字的列会自动求和,而为字符串类型的列则不显示;当然也可以同时groupby(['x1','x2',...])多个字段,其作用与上面类似。
七、Categorical按某一列重新编码分类
如六中要对a中的gender进行重新编码分类,将对应的0,1转化为male,female,过程如下:
a['gender1']=a['gender'].astype('category')
a['gender1'].cat.categories=['male','female'] #即将0,1先转化为category类型再进行编码。
print(a)得到的结果为:
date gender height weight gender1
0 2000-01-01 1 40 163 female
1 2000-01-02 0 44 177 male
2 2000-01-03 1 40 167 female
3 2000-01-04 0 41 161 male
4 2000-01-05 0 48 177 male
5 2000-01-06 1 46 179 female
6 2000-01-07 1 42 154 female
7 2000-01-08 1 43 170 female
8 2000-01-09 0 46 158 male
9 2000-01-10 1 44 168 female所以可以看出重新编码后的编码会自动增加到dataframe最后作为一列。
八、相关操作
描述性统计:
1.a.mean() 默认对每一列的数据求平均值;若加上参数a.mean(1)则对每一行求平均值;
2.统计某一列x中各个值出现的次数:a['x'].value_counts();
3.对数据应用函数
a.apply(lambda x:x.max()-x.min())
表示返回所有列中最大值-最小值的差。
4.字符串相关操作
a['gender1'].str.lower() 将gender1中所有的英文大写转化为小写,注意dataframe没有str属性,只有series有,所以要选取a中的gender1字段。
九、时间序列
在六中用pd.date_range('xxxx',periods=xx,freq='D/M/Y....')函数生成连续指定天数的的日期列表。
例如pd.date_range('20000101',periods=10),其中periods表示持续频数;
pd.date_range('20000201','20000210',freq='D')也可以不指定频数,只指定起始日期。
此外如果不指定freq,则默认从起始日期开始,频率为day。其他频率表示如下:
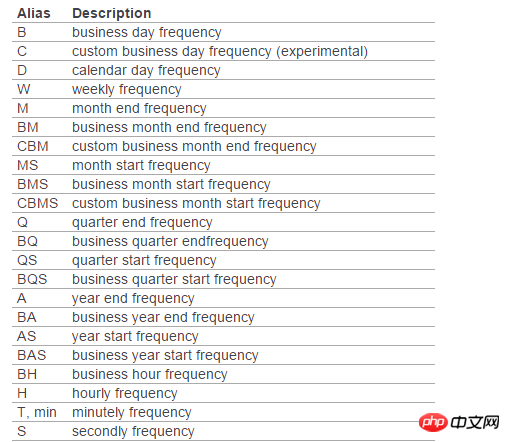
1.png
十、画图(plot)
在pycharm中首先要:import matplotlib.pyplot as plt
a=Series(np.random.randn(1000),index=pd.date_range('20100101',periods=1000))
b=a.cumsum()
b.plot()
plt.show() #最后一定要加这个plt.show(),不然不会显示出图来。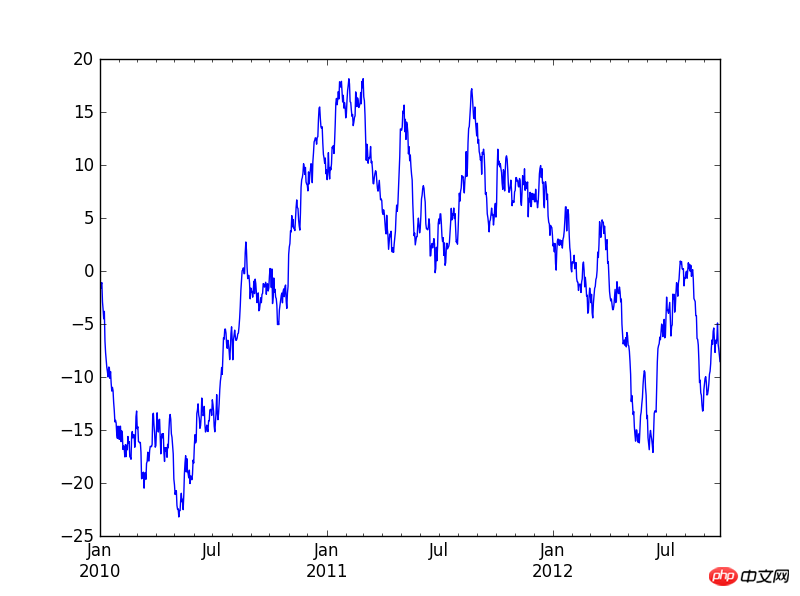
2.PNG
也可以使用下面的代码来生成多条时间序列图:
a=DataFrame(np.random.randn(1000,4),index=pd.date_range('20100101',periods=1000),columns=list('ABCD'))
b=a.cumsum()
b.plot()
plt.show()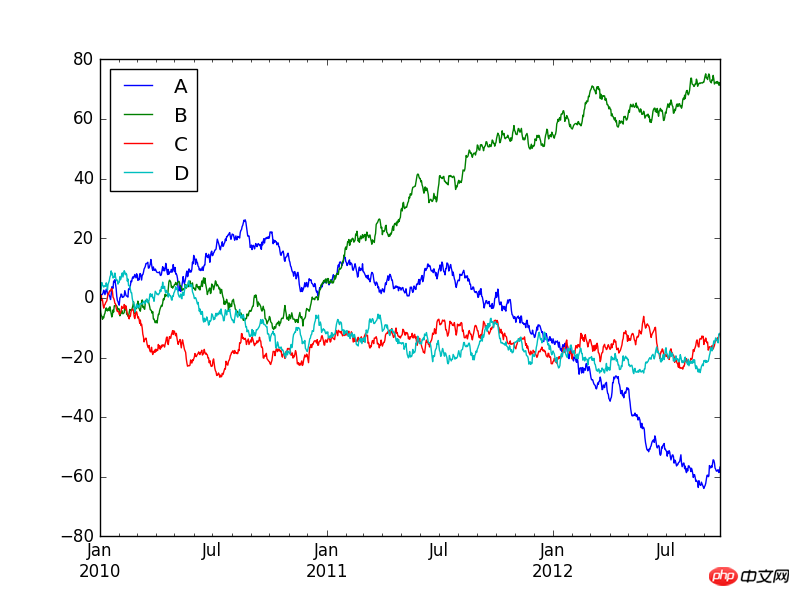
3.png
十一、导入和导出文件
写入和读取excel文件
虽然写入excel表时有两种写入xls和csv,但建议少使用csv,不然在表中调整数据格式时,保存时一直询问你是否保存新格式,很麻烦。而在读取数据时,如果指定了哪一张sheet,则在pycharm又会出现格式不对齐。
还有将数据写入表格中时,excel会自动给你在表格最前面增加一个字段,对数据行进行编号。
a.to_excel(r'C:\\Users\\guohuaiqi\\Desktop\\2.xls',sheet_name='Sheet1') a=pd.read_excel(r'C:\\Users\\guohuaiqi\\Desktop\\2.xls','Sheet1',na_values=['NA']) 注意sheet_name后面的Sheet1中的首字母大写;读取数据时,可以指定读取哪一张表中的数据,而 且对缺失值补上NA。 最后再附上写入和读取csv格式的代码: a.to_csv(r'C:\\Users\\guohuaiqi\\Desktop\\1.csv',sheet_name='Sheet1') a=pd.read_csv(r'C:\\Users\\guohuaiqi\\Desktop\\1.csv',na_values=['NA'])
Atas ialah kandungan terperinci pandas库介绍之DataFrame基本操作. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1379
1379
 52
52

 PHP dan Python: Contoh dan perbandingan kod
Apr 15, 2025 am 12:07 AM
PHP dan Python: Contoh dan perbandingan kod
Apr 15, 2025 am 12:07 AM
PHP dan Python mempunyai kelebihan dan kekurangan mereka sendiri, dan pilihannya bergantung kepada keperluan projek dan keutamaan peribadi. 1.PHP sesuai untuk pembangunan pesat dan penyelenggaraan aplikasi web berskala besar. 2. Python menguasai bidang sains data dan pembelajaran mesin.
 Cara Melatih Model Pytorch di CentOs
Apr 14, 2025 pm 03:03 PM
Cara Melatih Model Pytorch di CentOs
Apr 14, 2025 pm 03:03 PM
Latihan yang cekap model pytorch pada sistem CentOS memerlukan langkah -langkah, dan artikel ini akan memberikan panduan terperinci. 1. Penyediaan Persekitaran: Pemasangan Python dan Ketergantungan: Sistem CentOS biasanya mempamerkan python, tetapi versi mungkin lebih tua. Adalah disyorkan untuk menggunakan YUM atau DNF untuk memasang Python 3 dan menaik taraf PIP: Sudoyumupdatepython3 (atau SudodnfupdatePython3), pip3install-upgradepip. CUDA dan CUDNN (Percepatan GPU): Jika anda menggunakan Nvidiagpu, anda perlu memasang Cudatool
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 Python vs JavaScript: Komuniti, Perpustakaan, dan Sumber
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: Komuniti, Perpustakaan, dan Sumber
Apr 15, 2025 am 12:16 AM
Python dan JavaScript mempunyai kelebihan dan kekurangan mereka sendiri dari segi komuniti, perpustakaan dan sumber. 1) Komuniti Python mesra dan sesuai untuk pemula, tetapi sumber pembangunan depan tidak kaya dengan JavaScript. 2) Python berkuasa dalam bidang sains data dan perpustakaan pembelajaran mesin, sementara JavaScript lebih baik dalam perpustakaan pembangunan dan kerangka pembangunan depan. 3) Kedua -duanya mempunyai sumber pembelajaran yang kaya, tetapi Python sesuai untuk memulakan dengan dokumen rasmi, sementara JavaScript lebih baik dengan MDNWebDocs. Pilihan harus berdasarkan keperluan projek dan kepentingan peribadi.
 Cara Memilih Versi PyTorch Di Bawah Centos
Apr 14, 2025 pm 02:51 PM
Cara Memilih Versi PyTorch Di Bawah Centos
Apr 14, 2025 pm 02:51 PM
Apabila memilih versi pytorch di bawah CentOS, faktor utama berikut perlu dipertimbangkan: 1. Keserasian versi CUDA Sokongan GPU: Jika anda mempunyai NVIDIA GPU dan ingin menggunakan pecutan GPU, anda perlu memilih pytorch yang menyokong versi CUDA yang sepadan. Anda boleh melihat versi CUDA yang disokong dengan menjalankan arahan NVIDIA-SMI. Versi CPU: Jika anda tidak mempunyai GPU atau tidak mahu menggunakan GPU, anda boleh memilih versi CPU PyTorch. 2. Pytorch versi python
 Cara Memasang Nginx di CentOs
Apr 14, 2025 pm 08:06 PM
Cara Memasang Nginx di CentOs
Apr 14, 2025 pm 08:06 PM
CentOS Memasang Nginx memerlukan mengikuti langkah-langkah berikut: memasang kebergantungan seperti alat pembangunan, pcre-devel, dan openssl-devel. Muat turun Pakej Kod Sumber Nginx, unzip dan menyusun dan memasangnya, dan tentukan laluan pemasangan sebagai/usr/local/nginx. Buat pengguna Nginx dan kumpulan pengguna dan tetapkan kebenaran. Ubah suai fail konfigurasi nginx.conf, dan konfigurasikan port pendengaran dan nama domain/alamat IP. Mulakan perkhidmatan Nginx. Kesalahan biasa perlu diberi perhatian, seperti isu ketergantungan, konflik pelabuhan, dan kesilapan fail konfigurasi. Pengoptimuman prestasi perlu diselaraskan mengikut keadaan tertentu, seperti menghidupkan cache dan menyesuaikan bilangan proses pekerja.
 Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Latihan yang diedarkan Pytorch pada sistem CentOS memerlukan langkah -langkah berikut: Pemasangan Pytorch: Premisnya ialah Python dan PIP dipasang dalam sistem CentOS. Bergantung pada versi CUDA anda, dapatkan arahan pemasangan yang sesuai dari laman web rasmi Pytorch. Untuk latihan CPU sahaja, anda boleh menggunakan arahan berikut: PipinstallToRchTorchVisionTorchaudio Jika anda memerlukan sokongan GPU, pastikan versi CUDA dan CUDNN yang sama dipasang dan gunakan versi pytorch yang sepadan untuk pemasangan. Konfigurasi Alam Sekitar Teragih: Latihan yang diedarkan biasanya memerlukan pelbagai mesin atau mesin berbilang mesin tunggal. Tempat
