

解决CBO的SQL优化问题(图文详解)

本次分享大纲:
CBO优化器存在哪些坑
CBO优化器坑的解决之道
加强SQL审核,将性能问题扼杀于襁褓之中
分享现场FAQ
CBO( Cost Based Optimizer)优化器是目前Oracle广泛使用的优化器,其使用统计信息、查询转换等计算各种可能的访问路径成本,并生成多种备选执行计划,最终Oracle会选择成本最低的作为最优执行计划。与“远古”时代的RBO(Rule Based Optimizer)相比,显然更加符合数据库实际情况,能够适应更多的应用场景。但是,由于其自身非常复杂,CBO并未解决的实际问题以及存在的BUG非常多,在日常优化过程中,你可能会遇到一些,不管怎么收集统计信息,都无法走正确执行计划的情形,这时候,你可能踩坑CBO了。
本次分享,主要以日常常见优化器问题作为引子,一起探讨CBO的那些坑的解决之道。
一、CBO优化器存在哪些坑
先来看一下,CBO优化器的组件:
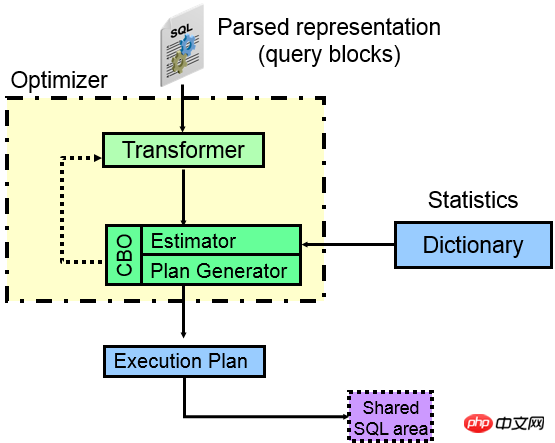
从上图可以看出,一条SQL进入ORACLE中,实际上经过解析会将各部分进行分离,每个分离的部分独立成为一个查询块(query blocks),比如子查询会成为一个查询块,外部查询又是一个查询块,那么ORACLE优化器要做的工作就是各查询块内部走什么样的访问路径更好(走索引、全表、分区?),其次就是各查询块之间应该走什么样的JOIN方式以及JOIN顺序,最终计算出那种执行计划更好。
优化器的核心就是查询转换器、成本估算器以及执行计划生成器。
Transformer(查询转换器):
从图上可以看出,优化器的第一核心装置就是查询转换器,查询转换器的主要作用就是研究各种查询块之间的关系,并从语法上甚至语义上给予SQL等价重写,重写后的SQL更容易被核心装置成本估算器和执行计划生成器处理,从而利用统计信息生成最优执行计划。
查询转换器在优化器中有两种方式:启发式查询转换(基于规则)和基于COST的查询转换。 启发式查询转换的一般是比较简单的语句,基于成本的一般比较复杂,也就是说,符合基于规则的ORACLE不管什么情况下都会进行查询转换,不符合的ORACLE可能考虑基于成本的查询转换。启发式查询转换历史悠久,问题较少,一般查询转换过的效率比不经过查询转换的要高,而基于成本的查询转换,因其与CBO优化器紧密关联,在10G引入,内部非常复杂,所以BUG也比较多,在日常优化过程中,各种疑难SQL,往往就出现在查询转换失败中,因为查询转换一旦失败,Oracle就不能将原始SQL转换成结构更良好的SQL(更易于被优化器处理),显然可选择的执行路径就要少很多,比如子查询不能UNNEST,那么,往往就是灾难的开始。其实,查询转换中Oracle做的最多的就是将各种查询转换成JOIN方式,这样就可以利用各种高效的JOIN方法了,比如HASH JOIN。
查询转换共有30种以上的方式,下面列出一些常见启发式和基于COST的查询转换。
启发式查询转换(一系列的RULE):
很多启发式查询转换在RBO情况下就已经存在。常见的有:
Simple View merge (简单视图合并)、SU (Subquery unnest 子查询展开)、OJPPD (old style Join predicate push-down 旧的连接谓词推入方式)、FPD (Filter push-down 过滤谓词推入)、OR Expansion (OR扩展)、OBYE(Order by Elimination 排序消除)、JE (Join Elimination 连接消除或连接中的表消除)、Transitive Predicate (谓词传递)等技术。
基于COST的查询转换(通过COST计算):
针对复杂的语句进行基于COST的查询转换,常见的有:
CVM (Complex view Merging 复杂视图合并)、JPPD (Join predicate push-down 关联谓词推入)、DP (Distinct placement)、GBP(Group by placement)等技术。
通过一系列查询转换技术,将原始SQL转为优化器更容易理解和分析的SQL,从而能够使用更多的谓词、连接条件等,达到获得最佳计划的目的。查询转换的过程,可以通过10053获取详细信息。查询转换是否能够成功和版本、优化器限制、隐含参数、补丁等有关。
随便在MOS上搜索一下查询转换,就会出现一堆BUG:
竟然还是Wrong result(错误的结果),遇到这种BUG不是性能问题了,而是严重的数据正确性问题,当然,在MOS里随便可以找到一堆这样的BUG,但是,在实际应用中,我相信,你可能碰到的较少,如果有一天,你看到一条SQL查询的结果可能不对,那你也得大胆质疑,对于Oracle这种庞然大物来说,遇到问题,质疑是非常正确的思考方式,这种Wrong result问题,在数据库大版本升级过程中可能见到,主要有两类问题:
原来结果正确,现在结果错误。--遇到新版本BUG
现在结果正确,原来结果错误。--新版本修复了老版本BUG
第一种情况很正常,第二种情况也可能存在,我就看到过一客户质疑升级后的结果不正确,结果经过查证之后,竟然是老版本执行计划就是错的,新版本执行计划是正确的,也就是错误了很多年,都没有发现,结果升级后是正确的,却以为是错了。
遇到错误结果,如果不是非核心功能,真的可能被深埋很多年。
Estimator( 估算器):
很显然,估算器会利用统计信息(表、索引、列、分区等)来估算对应执行计划操作中的选择性,从而计算出对应操作的cardinality,生成对应操作的COST,并最终计算整个计划的COST。对于估算器来说,很重要的就是其估算模型的准确性以及统计信息存储的准确性,估算的模型越科学,统计信息能反应实际的数据分布情况,能够覆盖更多的特殊数据,那么生成的COST则更加准确。
然而,这是不可能的情况,估算器模型以及统计信息中存在诸多问题,比如针对字符串计算选择性,ORACLE内部会将字符串转换为RAW类型,在将RAW类型转换成数字,然后左起ROUND 15位,这样会出现可能字符串相差很大的,由于转换成数字后超过15位,那么内部转换后可能结果相近,最终导致计算的选择性不准确。
Plan Generator( 计划生成器):
计划生成器也就是分析各种访问路径、JOIN方法、JOIN顺序,从而生产不同执行计划。那么如果这个部分出现问题,也就是对应的部分可能算法不够完善或者存在限制。比如JOIN的表很多,那么各种访问顺序的选择成几何级数增长,ORACLE内部有限制值,也就是事实不可能全部计算一遍。
比如HASH JOIN算法是普遍做大数据处理的首选算法,但是由于HASH JOIN天生存在一种限制:HASH碰撞,一旦遇到HASH碰撞,必然导致效率大减。
CBO优化器存在很多限制,详细可以参考MOS:Limitations of the Oracle Cost Based Optimizer (文档 ID 212809.1)。
二、CBO优化器坑的解决之道
本部分主要分享下日常常见优化器问题案例,有的问题不仅限于CBO优化器,由于CBO是目前广泛使用的优化器,因此,一律纳入CBO问题。
1 FILTER性能杀手问题
FILTER操作是执行计划中常见的操作,这种操作有两种情况:
只有一个子节点,那么就是简单过滤操作。
有多个子节点,那么就是类似NESTED LOOPS操作,只不过与NESTED LOOPS差别在于,FILTER内部会构建HASH表,对于重复匹配的,不会再次进行循环查找,而是利用已有结果,提高效率。但是一旦重复匹配的较少,循环次数多,那么,FILTER操作将是严重影响性能的操作,可能你的SQL几天都执行不完了。
下面看看各种情况下的FILTER操作:
单子节点:
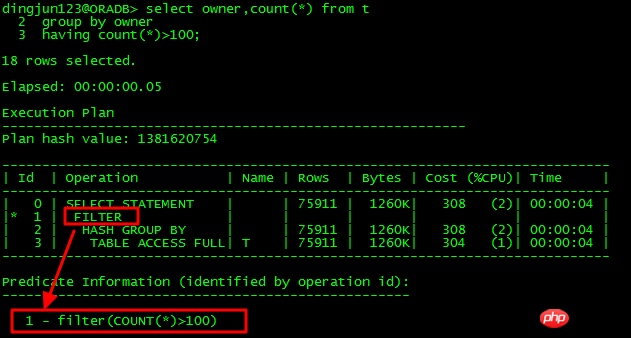
很显然ID=1的FILTER操作只有一个子节点ID=2,这种情况下的FILTER操作也就是单纯的过滤操作。
多子节点:
FILTER多子节点往往就是性能杀手,主要出现在子查询无法UNNEST查询转换,经常遇到的情况就是NOT IN子查询、子查询和OR连用、复杂子查询等情况。
(1)NOT IN子查询中的FILTER
先来看下NOT IN情况:
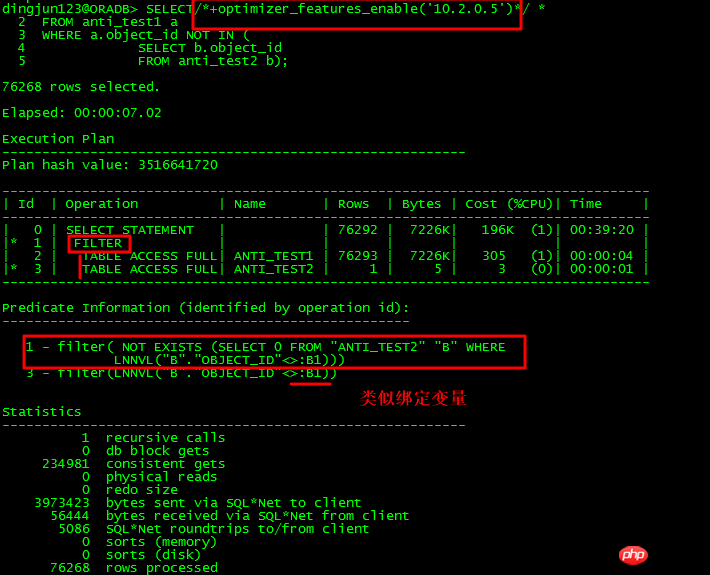
针对上面的NOT IN子查询,如果子查询object_id有NULL存在,则整个查询都不会有结果,在11g之前,如果主表和子表的object_id未同时有NOT NULL约束,或都未加IS NOT NULL限制,则ORACLE会走FILTER。11g有新的ANTI NA(NULL AWARE)优化,可以对子查询进行UNNEST,从而提高效率。
对于未UNNEST的子查询,走了FILTER,有至少2个子节点,执行计划还有个特点就是Predicate谓词部分有:B1这种类似绑定变量的东西,内部操作走类似NESTED LOOPS操作。
11g有NULL AWARE专门针对NOT IN问题进行优化,如下所示:
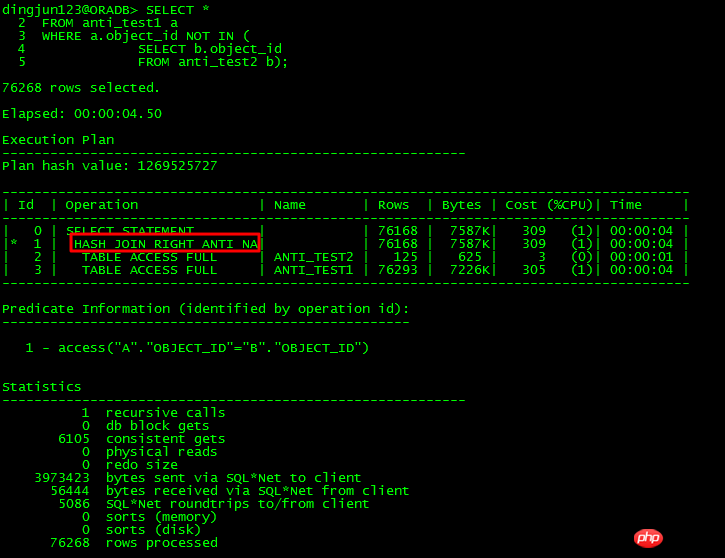
通过NULL AWARE操作,对无法UNNEST的NOT IN子查询可以转换成JOIN形式,这样效率就大幅度提升了。如果在11g之前,遇到NOT IN无法UNNEST,那该怎么做呢?
将NOT IN部分的匹配条件,针对本例就是ANTI_TEST1.object_id和ANTI_TEST2.object_id均设为NOT NULL约束。
不改NOT NULL约束,则需要两个object_id均增加IS NOT NULL条件。
改为NOT EXISTS。
改为ANTI JOIN形式。
以上四种方式,大部分情况下均能达到让优化器走JOIN的目的。
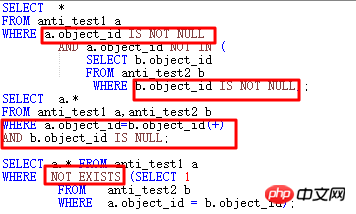
以上写法执行计划都是一样的,如下所示:
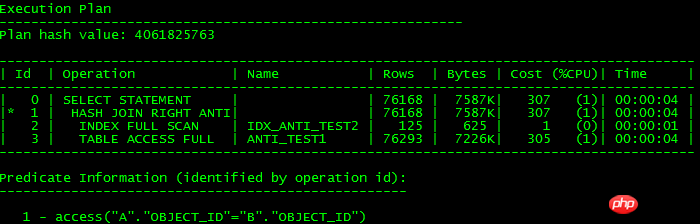
说白了,unnest subquery就是转换成JOIN形式,如果能转换成JOIN就可以利用高效JOIN特性来提高操作效率,不能转换就走FILTER,可能影响效率,11g的NULL AWARE从执行计划里可以看出,还是有点区别,没有走INDEX FULL SCAN扫描,因为没有条件让ORACLE知道object_id可能存在NULL,所以也就走不了索引了。
OK,现在来说一个数据库升级过程中碰到的案例,背景是11.2.0.2升级到11.2.0.4后下面SQL出现性能问题:
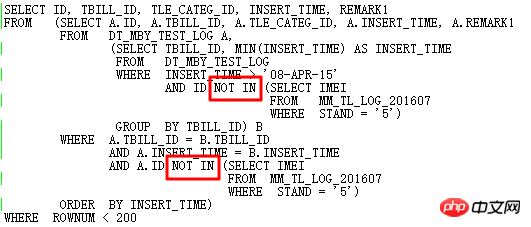
执行计划如下:
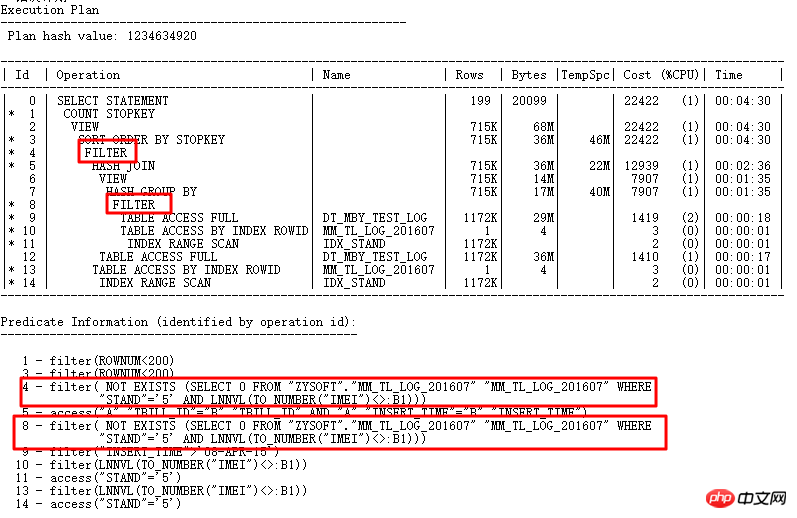
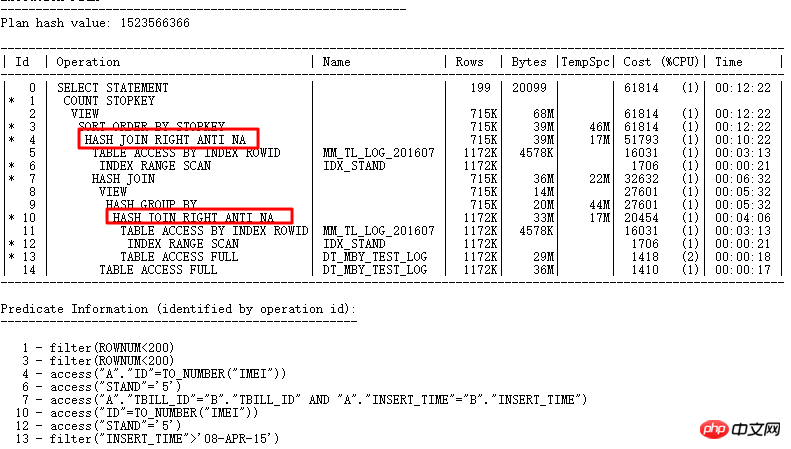
这里的ID=4和ID=8两个FILTER均有2个子节点,很显然是NOT IN子查询无法UNNEST导致的。上面说了在11g ORACLE CBO可以将NOT IN转换成NULL AWARE ANTI JOIN,并且在11.2.0.2上是可以转换的,到11.2.0.4上就不行了。两个FILTER操作的危害到底有多大呢,可以通过查询实际执行计划来看:
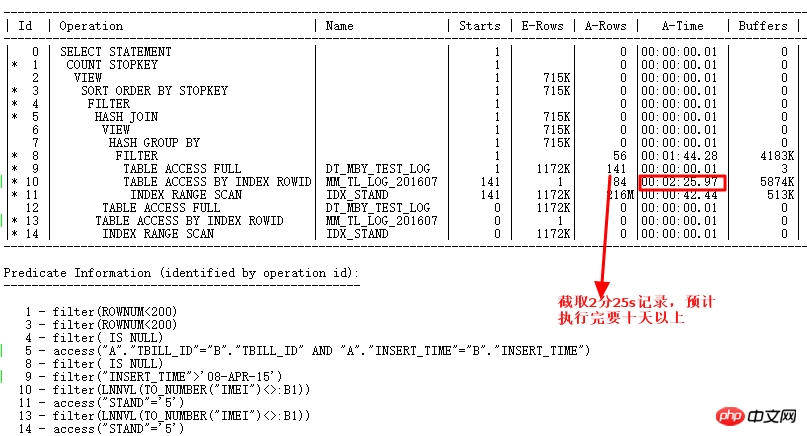
使用ALTER SESSION SET STATISTICS_LEVEL=ALL;截取2分25s的记录查看实际情况,ID=9步骤的CARD=141行就需要2分25s,实际此步骤有:27w行
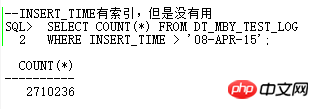
也就是这条SQL要运行10天以上了,简直太恐怖了。
针对此问题的分析如下:
查询和NULL AWARE ANTI JOIN相关的隐含参数是否有效
收集统计信息是否有效
是否是新版本BUG或者升级中修改了参数导致的
针对第一种情况:

参数是TRUE,显然没有问题。
针对第二种情况:
收集统计信息发现无效。
那么此时,只能寄希望于第三种情况:可能是BUG或者升级过程中修改了其它参数影响了无法走NULL AWARE ANTI JOIN。ORACLE BUG和参数那么多,那么我们怎么快速找到问题根源导致是哪个BUG或者参数导致的呢?这里给大家分享一个神器SQLT,全称(SQLTXPLAIN),这是ORACLE内部性能部门开发的工具,可以在MOS上下载,功能非常强劲。
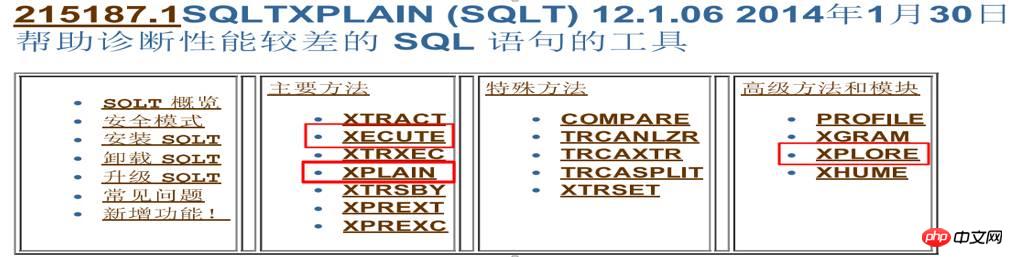
回归正题,现在要找出是不是新版本BUG或者修改了某个参数导致问题产生, 那么就要用到SQLT的高级方法:XPLORE。 XPLORE会针对ORACLE中的各种参数不停打开、关闭,来输出执行计划,最终我们可以通过生成的报告,找到匹配的执行计划来判断是BUG问题还是参数设置问题。

使用很简单,参考readme.txt将需要测试的SQL单独编辑一个文件,一般,我们测试都使用XPLAIN方法,调用EXPLAIN PLAN FOR进行测试,这样保证测试效率。
SQLT 找出问题根源:

最终通过SQLT XPLORE找出问题根源在于新版本关闭了_optimier_squ_bottomup参数(和子查询相关)。从这点上也可以看出来,很多查询转换能够成功,不光是一个参数起作用,可能多个参数共同作用。因此,关闭默认参数,除非有强大的理由,否则,不可轻易修改其默认值。至此,此问题在SQLT的帮助下,快速得以解决,如果不使用SQLT,那么解决问题的过程显然更为曲折,一般情况下,估计是让开发先修改SQL了。
思考一下,原来的SQL是不是还可以更优化呢?
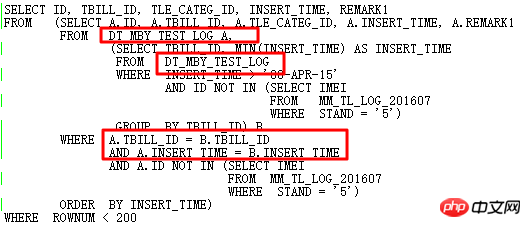
很显然,如果要进一步优化,要彻底对SQL进行重写,通过观察,2个子查询部分有相同点,经过分析语义:查找表DT_MBY_TEST_LOG在指定INSERT_TIME范围内的,按照每个TBILL_ID取最小的INSERT_TIME,并且ID不在子查询中,然后结果按照INSERT_TIME排序,最后取TOP 199。
原SQL使用自连接、两个子查询,冗余繁杂。自然想到用分析函数进行改写,避免自连接,从而提高效率。改写后的SQL如下:
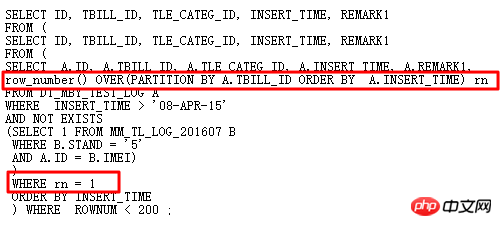
执行计划:
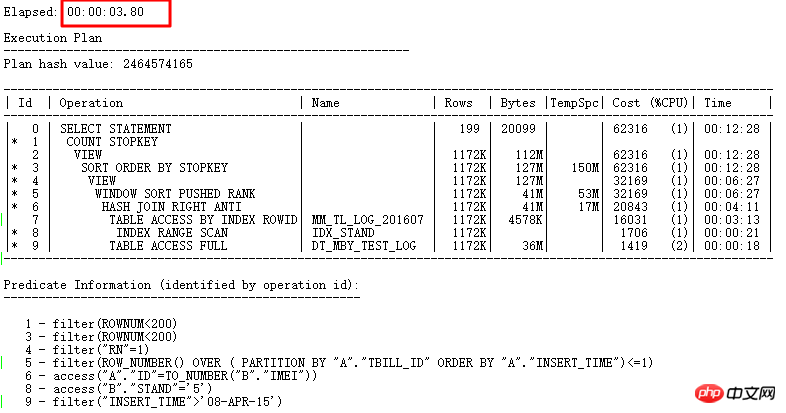
至此,这条SQL从原来的走FILTER需要耗时10天,到找出问题根源可以走NULL AWARE ANTI JOIN需要耗时7秒多,最后通过彻底改写耗时3.8s。
(2) OR子查询中的FILTER
再来看下常见的OR与子查询连用情况,在实际优化过程中,遇到OR与子查询连用,一般都不能unnest subquery了,可能会导致严重性能问题,OR与子查询连用有两种可能:
condition or subquery
subquery内部包含or,如in (select … from tab where condition1 or condition 2)
还是通过一个具体案例,分享下对于OR子查询优化的处理方式,在某库11g R2中碰到如下SQL,几个小时都没有执行完:

先来看下执行计划:
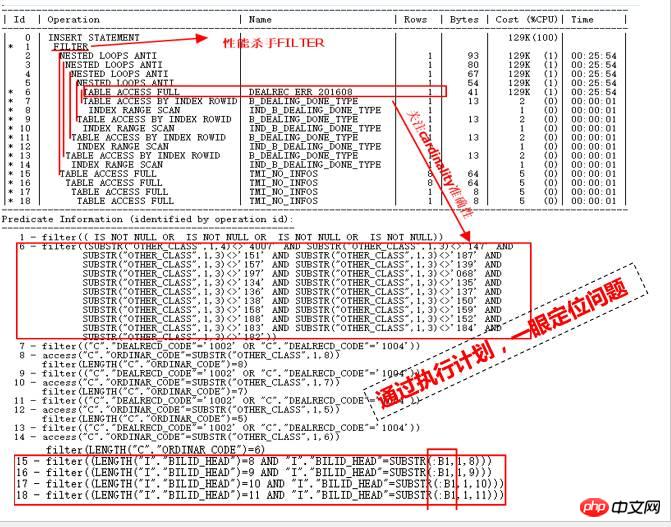
怎么通过看到这个执行计划,一眼定位性能慢的原因呢?主要通过下列几点来分析定位:
执行计划中的Rows,也就是每个步骤返回的cardinality很少,都是几行,在分析表也不是太大,那么怎么可能导致运行几个小时都执行不完呢?很大原因可能就在于统计信息不准,导致CBO优化器估算错误,错误的统计信息导致错误的执行计划,这是第一点。
看ID=15到18部分,它们是ID=1 FILTER操作的第二子节点,第一子节点是ID=2部分,很显然,如果ID=2部分估算的cardinality错误,实际情况很大的话,那么对ID=15到18部分四个表全扫描次数将会巨大,那么也就导致灾难产生。
很显然,ID=2部分的一堆NESTED LOOPS也是很可疑的,找到ID=2操作的入口在ID=6部分,全表扫描DEALREC_ERR_201608,估算返回1行,很显然,这是导致NESTED LOOPS操作的根源,因此,需要检验其准确性。
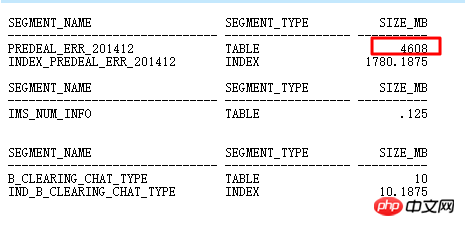
主表DEALREC_ERR_201608在ID=6查询条件中经查要返回2000w行,计划中估算只有1行,因此,会导致NESTED LOOPS次数实际执行千万次,导致效率低下,应该走HASH JOIN,需要更新统计信息。
另外ID=1是FILTER,它的子节点是ID=2和ID=15、16、17、18,同样的ID 15-18也被驱动千万次。
找出问题根源后,逐步解决。首先要解决ID=6部分针对DEALREC_ERR_201608表按照查询条件substr(other_class, 1, 3) NOT IN (‘147’,‘151’, …)获得的cardinality的准确性,也就是要收集统计信息。
然而发现使用size auto,size repeat,对other_class收集直方图均无效果,执行计划中对other_class的查询条件返回行估算还是1(实际2000w行)。

再次执行后的执行计划如下:
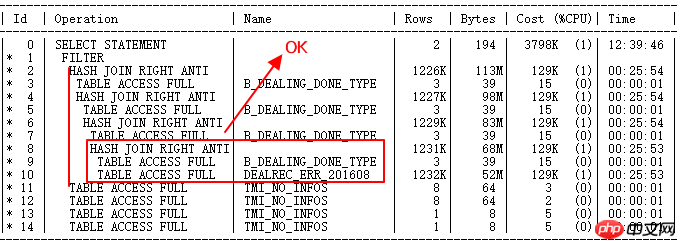
DEALREC_ERR_201608与B_DEALING_DONE_TYPE原来走NL的现在正确走HASH JOIN。Build table是小结果集,probe table是ERR表大结果集,正确。
但是ID=2与ID=11到14,也就是与TMI_NO_INFOS的OR子查询,还是FILTER,驱动数千万次子节点查询,下一步优化要解决的问题。
性能从12小时到2小时。
现在要解决的就是FILTER问题,对子查询有OR条件的,简单条件如果能够查询转换,一般会转为一个union all view后再进行semi join、anti join(转换成union all view,如果谓词类型不同,则SQL可能会报错)。对于这种复杂的,优化器就无法查询转换了,因此,改写是唯一可行的方法。分析SQL,原来查询的是同一张表,而且条件类似,只是取的长度不同,那么就好办了!

如何让带OR的子查询执行计划从FILTER变成JOIN。两种方法:
1)改为UNION ALL/UNION
2)语义改写.前面已经使用语义改写,内部转为了类似UNION的操作,如果要继续减少表的访问,则只能彻改写OR条件,避免转换为UNION操作。
再来分析下原始OR条件:
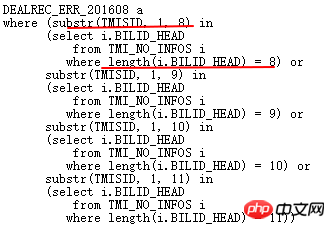
上面含义是ERR表的TMISID截取前8,9,10,11位与TMI_NO_INFOS.BILLID_HEAD匹配,对应匹配BILLID_HEAD长度正好为8,9,10,11。很显然,语义上可以这样改写:
ERR表与TMI_NO_INFOS表关联,ERR.TMISID前8位与ITMI_NO_INFOS.BILLID_HEAD长度在8-11之间的前8位完全匹配,在此前提下,TMISID like ‘BILLID_HEAD %’。
现在就动手彻底改变多个OR子查询,让SQL更加精简,效率更高。改写如下:
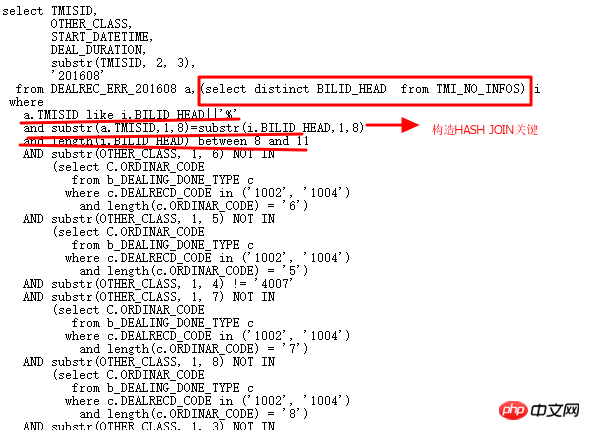
执行计划如下:
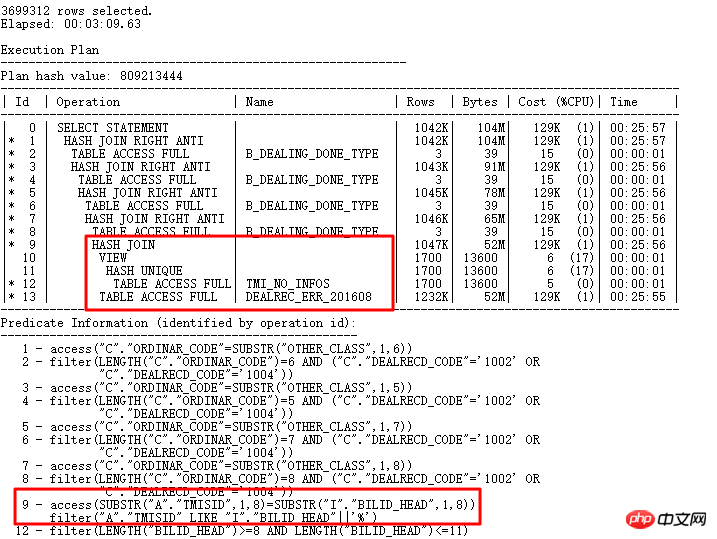
1)现在的执行计划终于变的更短,更易读,通过逻辑改写走了HASH JOIN, 最终一条返回300多万行数据的SQL原先需要12小时运行的SQL,现在3分钟就执行完了。
2) 思考:结构良好,语义清晰的SQL编写,有助于优化器选择更合理的执行计划,所以说,写好SQL也是门技术活。
通过这个案例,希望能给大家一些启发,写SQL如何能够自己充当查询转换器,编写的SQL能够减少表、索引、分区等的访问,能够让ORACLE更易使用一些高效算法进行运算,从而提高SQL执行效率。
其实,OR子查询也不一定就完全不能unnest,只是绝大多数情况下无法unnest而已,请看下例:
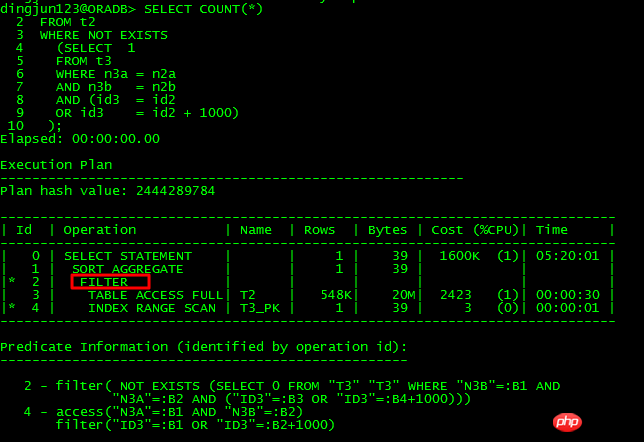
不可unnest的查询:
可以unnest的查询:
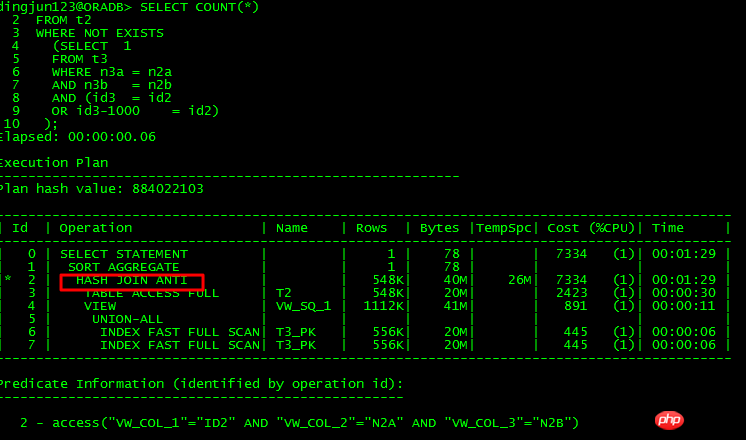
这2条SQL的差别也就是将条件or id3 = id2-1000转换成or id3-1000 = id2,前者不可以unnest,后者可以unnest,通过分析10053可以得知:
不可unnest的出现:
SU: Unnesting query blocks in query block SEL$1 (#1) that are valid to unnest.
Subquery Unnesting on query block SEL$1 (#1)SU: Performing unnesting that does not require costing.
SU: Considering subquery unnest on query block SEL$1 (#1).
SU: Checking validity of unnesting subquery SEL$2 (#2)
SU: SU bypassed: Invalid correlated predicates.
SU: Validity checks failed.
可以unnest的出现:

并且将SQL改写为:

最终CBO先查询T3条件,做个UNION ALL视图,之后与T2关联。从这里来看,对于OR子查询的unnest要求比较严格,从这条语句分析,ORACLE可进行unnest必须要求对主表列不要进行运算操作,优化器自身并未将+1000条件左移,正因为严格,所以大部分情况下,OR子查询也就无法进行unnest了,从而导致各种性能问题。
(3)类FILTER问题
类FILTER问题主要体现在UPDATE关联更新和标量子查询中,虽然此类SQL语句中并未显式出现FILTER关键字,但是内部操作和FILTER操作如出一辙。
先看下UPDATE关联更新:

这里需要更新14999行,执行计划如下:
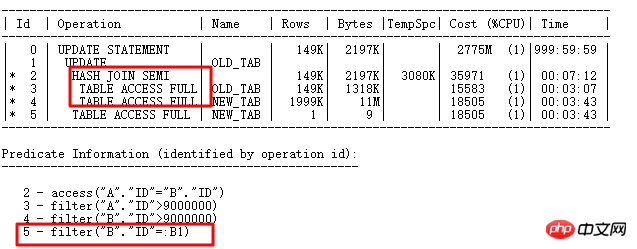
ID=2部分是where exists选择部分,先把需要更新的条件查询出来,之后执行UPDATE关联子查询更新,可以看到ID=5部分出现绑定变量:B1,显然UPDATE操作就类似于原来的FILTER,对于选出的每行与子查询表NEW_TAB关联查询,如果ID列重复值较少,那么子查询执行的次数就会很多,从而影响效率,也就是ID=5的操作要执行很多次。
当然,这里字段ID唯一性很强,可以建立UNIQUE INDEX,普通INDEX灯,这样第5步就可以走索引了。这里为了举例这种UPDATE的优化方式,不建索引,也可以搞定这样的UPDATE:MERGR和UPDATE INLINE VIEW方式。
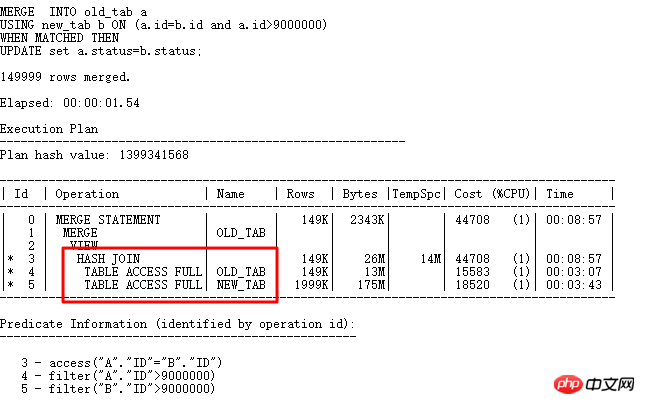
MERGE中直接利用HASH JOIN,避免多次访问操作,从而效率大增,再来看看UPDATE LINE VIEW写法:
UPDATE
(SELECT a.status astatus,
b.status bstatus
FROM old_tab a,
new_tab b
WHERE a.id=b.id
AND a.id >9000000
)
SET astatus=bstatus;
要求b.id是preserved key (唯一索引、唯一约束、主键),11g bypass_ujvc会报错,类似MERGE操作。
再来看看标量子查询,标量子查询往往也是引发严重性能问题的杀手:
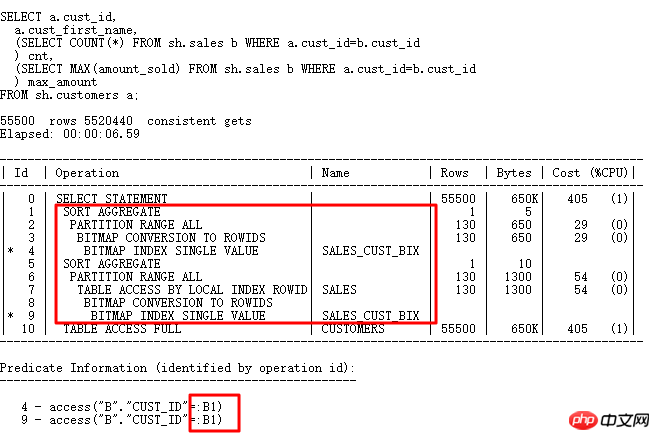
标量子查询的计划和普通计划的执行顺序不同,标量子查询虽然在上面,但是它由下面的CUSTOMERS表结果驱动,每行驱动查询一次标量子查询(有CACHE例外),同样类似FILTER操作。
如果对标量子查询进行优化,一般就是改写SQL,将标量子查询改为外连接形式(在约束和业务满足的情况下也可改写为普通JOIN):

通过改写之后效率大增,并且使用HASH JOIN算法。下面看一下标量子查询中的CACHE(FILTER和UPDATE关联更新类似),如果关联的列重复值特别多,那么子查询执行次数就会很少,这时候效率会比较好:
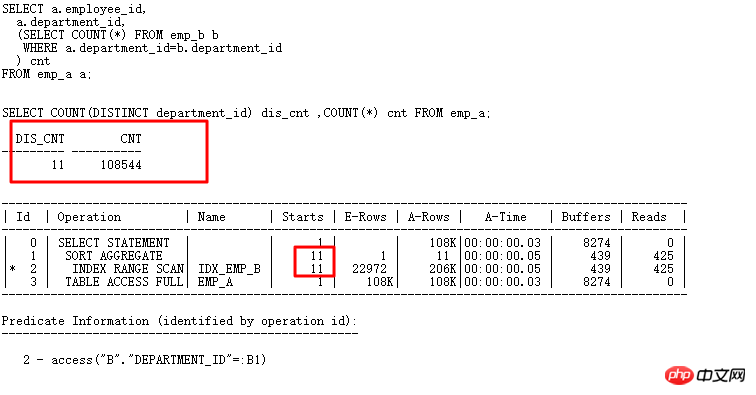
标量子查询和FILTER一样,有CACHE,如上面的emp_a有108K的行,但是重复的department_id只有11,这样只查询只扫描11次,扫描子查询表的次数少了,效率会提升。
针对FILTER性能杀手问题,主要分享这3点,当然,还有很多其它值得注意的地方,这需要我们日常多留心和积累,从而熟悉优化器一些问题的处理方法。
2 TABLE函数8168基数问题
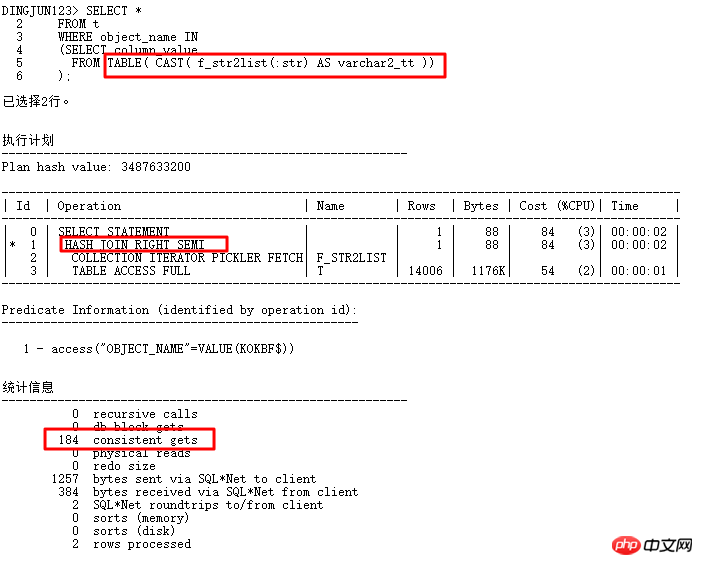
此问题来源于binding in list问题,使用TABLE函数构造传入的逗号分隔的值作为子查询条件,一般前端传入的值都较少,但是实际上走了HASH JOIN操作,无法使用T表索引,一旦执行频率高,必然对系统影响较大,为什么ORACLE不知道TABLE函数传入了很少的值呢?
进一步分析:
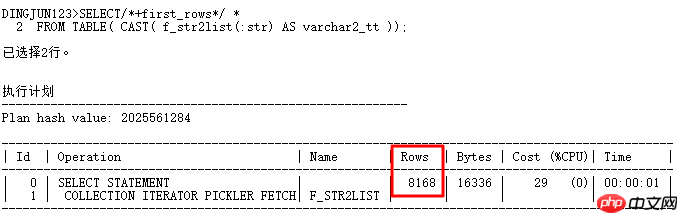
从上面结果看出,TABLE函数的默认行数是8168行(TABLE函数创建的伪表是没有统计信息的),这个值不小了,一般比实际应用中的行数要多的多,经常导致执行计划走hash join,而不是nested loop。怎么改变这种情况呢?当然可以通过hint提示来改变执行计划了,对where in list,常常使用的hint有:
first_rows,index,cardinality,use_nl等。
这里特别介绍下cardinality(table|alias,n) ,这个hint很有用, 它可以让CBO优化器认为表的行数是n,这样就可以改变执行计划了。现在改写上面的查询:
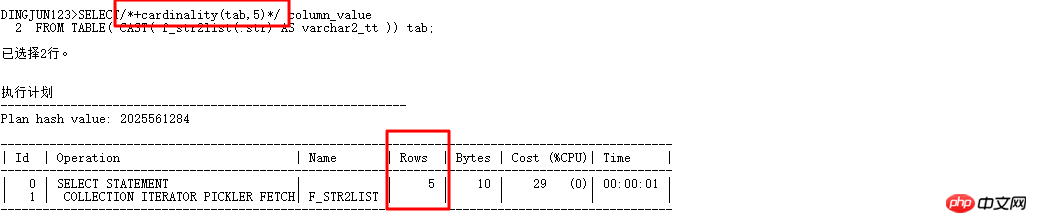
加了cardinality(tab,5)自动走CBO优化器了,优化器把表的基数看成5,前面的where in list查询基数默认为8168的时候走的是hash join,现在有了cardinality,赶紧试试:
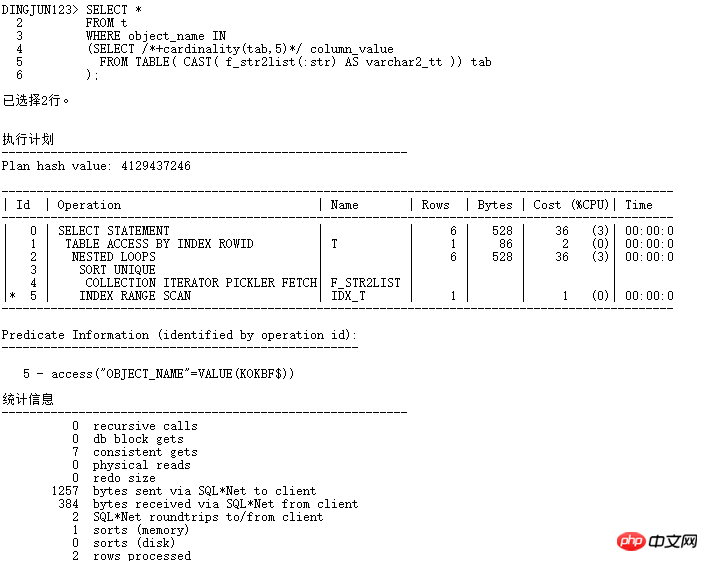
现在走NESTED LOOPS操作,子节点可以走INDEX RANGE SCAN,逻辑读从184变成7,效率提升数十倍。当然,实际应用中,最好不要加hints,可以使用SQL PROFILER绑定。
3 选择性计算不准确问题
Oracle内部计算选择性都是以数字格式计算,因此,遇到字符串类型,会将字符串转换成RAW类型,再将RAW类型转换成数字,并且ROUND到左起15位,这样对于转换后的数字很大,可能原来字符串相差比较大的,内部转换后的数字比较接近,这样就会引起选择性计算不准确问题。如下例:

执行计划如下:
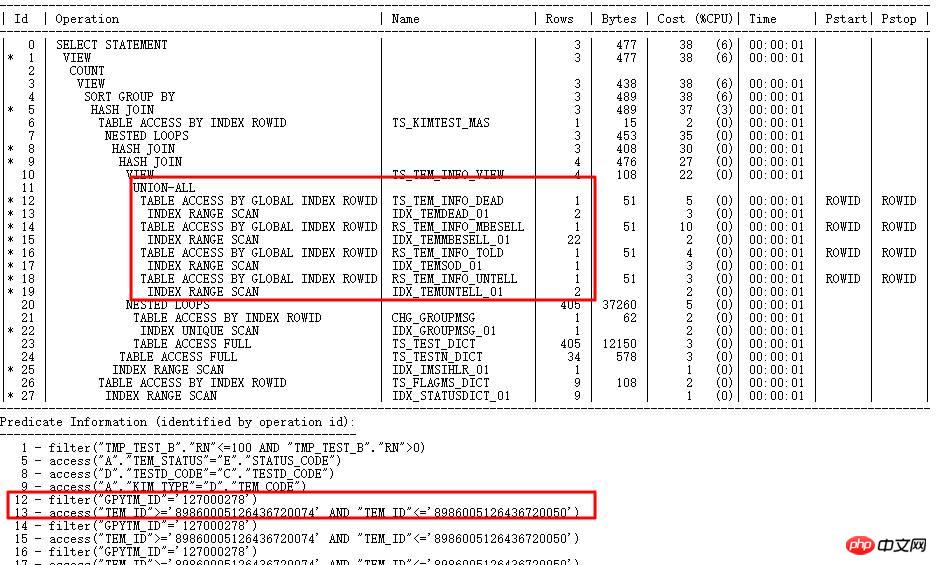
SQL执行计划走TEM_ID索引,需要运行1小时以上,计划中对应步骤cardinality很少(几十级别),实际很大(百万级别),判断统计信息出错。
为什么走错索引?
由于TEM_ID是CHAR字符串类型,长度20,CBO内部计算选择性会先将字符串转为RAW,然后RAW转为数字,左起ROUND 15位。因此,可能字符串值差别大的,转换成数字后值接近(因为超出15位补0),导致选择性计算错误。以TS_TEM_INFO_DEAD中的TEM_ID列为例:

而实际根据条件查询出的行数 29737305。因此,索引走错了。
解决方法:
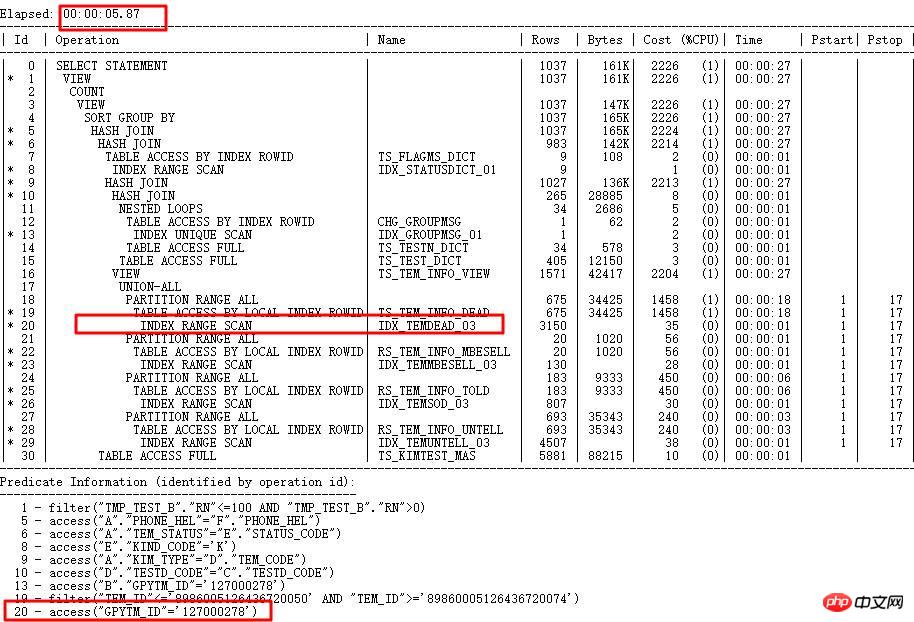
收集TEM_ID列直方图,由于内部算法有一定限制,导致值不同的字符串,内部计算值可能一致,所以收集直方图后,针对字符串值不同,但是转换成数字后相同的,ORACLE会将实际值存储到ENDPOINT_ACTUAL_VALUE中,用于校验,提高执行计划的准确性。走正确索引GPYTM_ID后,运行时间从1小时以上到5s内。
4 新特性引发执行出错问题
每个版本都会引入很多新特性,对于新特性,使用不当可能会引发一些严重问题,常见的比如ACS、cardinality feedback导致执行计划变动频繁,影响效率,子游标过多等,所以,针对新特性需要谨慎使用,包括前面说的11g null aware anti join也存在很多BUG。
今天要分析的案例是10g到11g大版本升级过程中遇到的SQL,在10g中正常运行,但是到11g中却执行出错。 SQL如下:
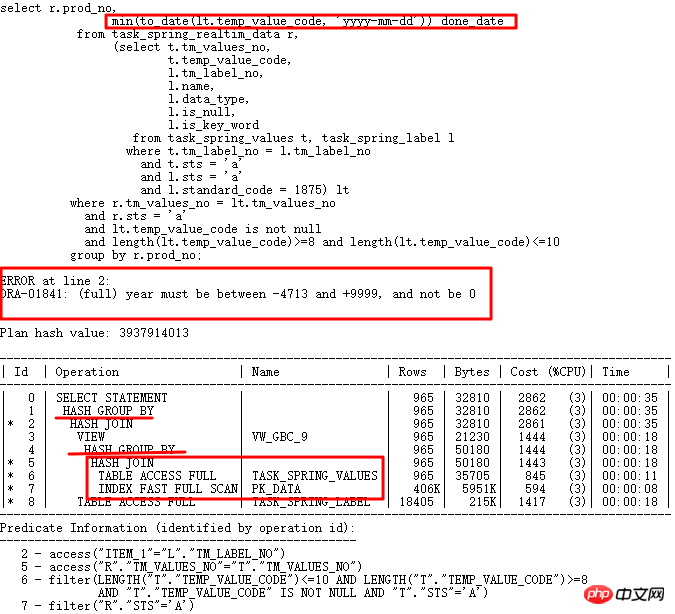
10g正常,升级11g r2后日期转换出错,temp_value_code存多种格式字符串。正确执行计划LT关联查询先执行,之后与外表关联。错误执行计划是TASK_SPRING_VALUES先与外表关联然后分组,作为VIEW再与TASK_SPRING_LABEL关联,再次进行分组,这里有2个GROUP BY操作,与10g执行计划中只有1个GROUP BY操作不同,最终导致报错。
很显然,对于为什么出现两个GROUP BY操作,需要进行研究,首选10053:
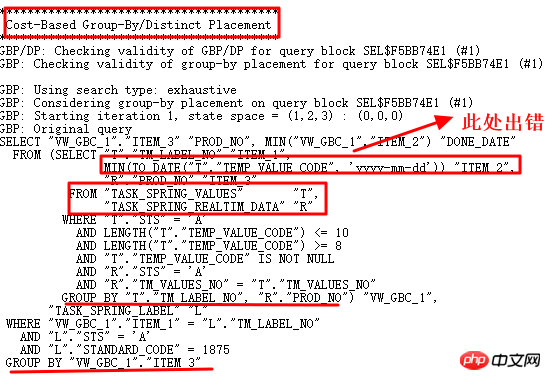
分析按照10053操作,是否找到非日期格式值:
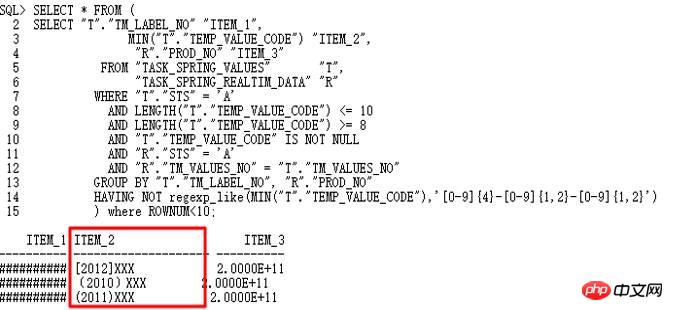
的确找到非yyyy-mm-dd格式字符串,因此,to_date操作失败。通过10053可以看出,这里使用了Group by/Distinct Placement操作,因此,需要找到对应的控制参数,关闭此查询转换。
关闭GBP隐含参数后正确:_optimizer_group_by_placement。正确执行计划如下:
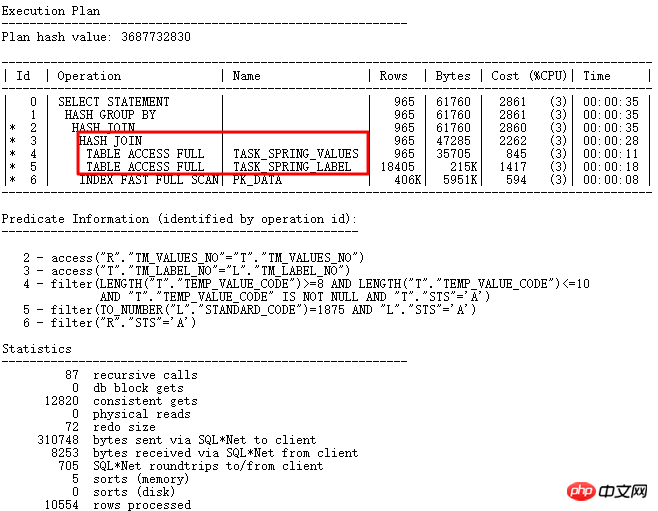
思考: 这个问题的本质在于字段用途设计不合理,其中temp_value_code作为varchar2存储普通字符、数字型字符、日期格式yyyy-mm-dd,程序中有to_number,to_date等转换,非常依赖于执行计划中表连接和条件的先后顺序。所以,良好的设计很重要,特别要保证各关联字段类型的一致性以及字段作用的单一性,符合范式要求。
5 坑爹写法CBO无能为力
结构优良的SQL能够更易被CBO理解,从而更好地进行查询转换操作,从而为后续生成最佳执行计划打下基础,然后实际应用过程中,因为不注重SQL写法,导致CBO也无能为力。下面以分页写法案例作为探讨。
低效分页写法:

原写法最内层根据use_date等条件查询,然后排序,获取rownum并取别名,最外层使用rn规律。问题在哪?
分页写法如果直接<,<=可在排序后直接rownum获取(两层嵌套),如果需要获取区间值,在最外层获取>,>=(三层嵌套)。
此语句获取<=,而使用三层嵌套,导致无法使用分页查询STOPKEY算法,因为rownum会阻止谓词推入,导致执行计划中没有STOPKEY操作。
<=分页只需要2层嵌套,done_date列有索引,根据条件done_date>to_date(‘20150916’,‘YYYYMMDD’)和只获取前20行,可高效利用索引和STOPKEY算法,改写完成后使用索引降序扫描,执行时间从1.72s到0.01s,逻辑IO 从42648到59,具体如下:

高效分页写法应该符合规范,并且能够充分利用索引消除排序。
6 CBO BUG问题
CBO BUG出现比较多的就是在查询转换中,一旦出现BUG,可能查找就比较困难,这时候应该通过分析10053或者通过使用SQLT XPLORE快速找到问题根源。如下例:
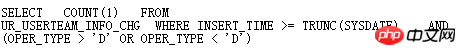
这个表的oper_type有索引,并且条件oper_type>’D’ or oper_type<’D’走索引较好,但是实际上Oracle却走了全表扫描,通过SQLT XPLORE快速分析:
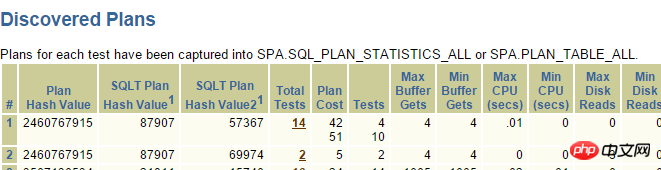
其中上面2个是走索引的执行计划,点进去:
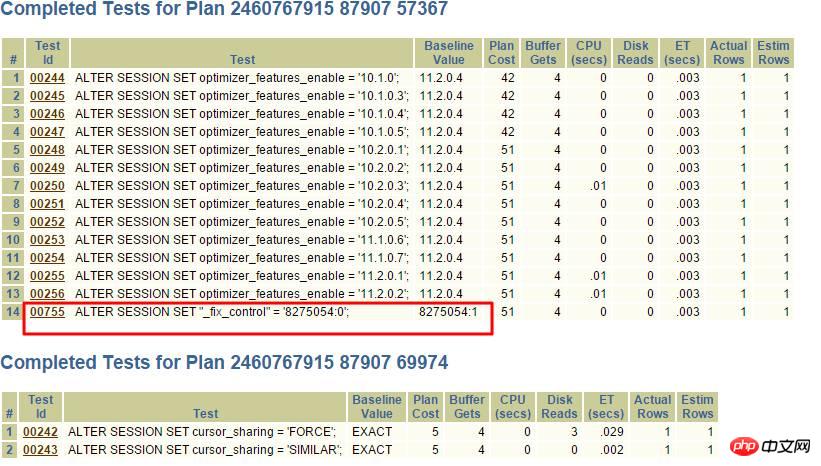
很显然,_fix_control=8275054很可疑,通过查询MOS:

转换成a<>b,很显然使用不了索引了,可以通过关闭此8275054解决。
7 HASH碰撞问题
HASHJOIN是专门用来做大数据处理的高效算法,并且只能用于等值连接条件,针对表build table(hash table)和probe table构建HASH运算,查找满足条件的结果集。
一般格式如下:
HASH JOIN
build table
probe table
这里的build table应该选择通过过滤条件过滤后,结果集尺寸较小的表(size不是rows),然后按照连接条件进行HASH函数运算,把需要的列和HASH函数运算结果存储到hash bucket中,hash bucket自身是链表结构。同样,对于probe table也需要进行hash函数运算,并根据运算结果到build table的hash bucket中去查询,查到满足,查不到丢弃。当然,ORACLE HASH JOIN内部构造还是很复杂的,具体可以参考Jonathan Lewis的CBO原理书。
HASH查找天生存在的问题:
一旦build table的连接条件列选择性不好(也就是重复值特别多),那么某些hash bucket上可能存储大量数据,由于hash bucket自身是链表结构,那么当查询这些hash bucket时,效率会急剧下降,此问题就是HASH运算的经典问题Hash Collision(HASH碰撞)。
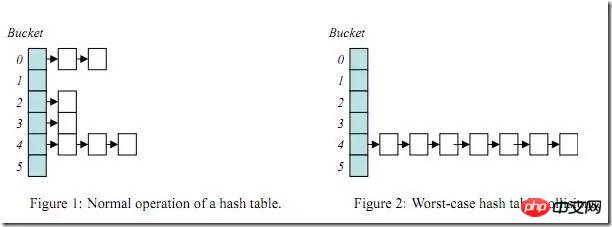
下面用一个小例子来分析下hash碰撞:
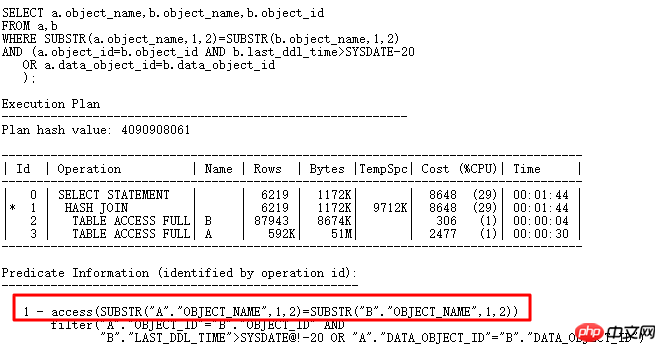
其中 a 表 61w 多条记录, b 表 7w 多条记录,此 SQL 结果返回 8w 多条记录,从执行计划来看,做 HASH JOIN 运算没有什么问题,但是实际此 SQL 执行 10 多分钟都没有执行完,效率非常低下, CPU 使用率突增,远远大于访问两个表的时间。
如果你了解HASHJOIN,这时候,你应当考虑是不是遇到hash collision了,如果很多bucket上存储大量数据,那么对于这样的hash bucket里的数据查找那就类似于nested loops了,必然效率大减。如下进一步分析:

查找一下大于重复数据大于3000条的值,果然有很多,当然剩下数据也有很多比较大,探测HASH JOIN,可以使用EVENT 10104:
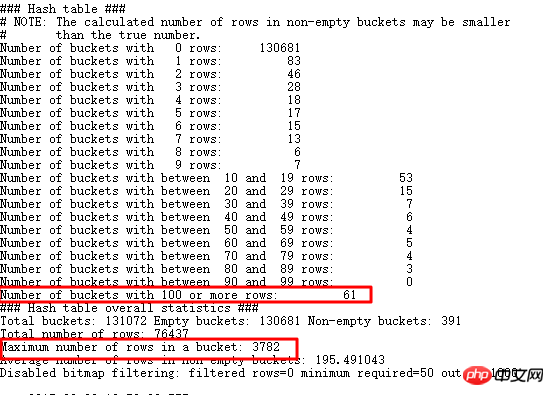
可以看到存储100行+的bucket有61个,而且最多的一个bucket中存储了3782条,也就是和我们查询出来的一致。还是回到原始SQL:
Oralce为什么选择substr(b.object_name,1,2)来构建HASH表呢,如果能将OR展开,原始SQL改为一个UNION ALL形式的,那么HASH表可以采用substr(b.object_name,1,2)和b.object_id以及data_object_id来构建,那么必然唯一性很好,那应该可以解决hash collision问题,改写如下:

现在的SQL执行时间从原来的10几分钟都没有结果,到4s执行完毕,再来看内部构建的HASHTABLE信息:
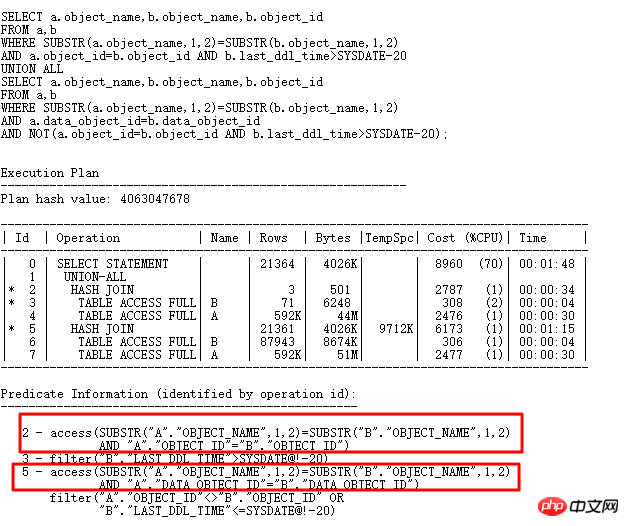
最多的一个bucket中只存储6条数据,那肯定性能比前面好很多了。Hash碰撞的危害很大,实际应用中,可能比较复杂,如果遇到hash碰撞问题,最好的方式就是进行SQL重写,尽量从业务上分析,能不能增加其它选择性比较好的列进行JOIN。
回头来看看,既然我都知道改写成UNION ALL后,就采用2个组合列构建比较好的HASH表,那么 Oracle 为什么不这样做呢?很简单,我这里只是举例刻意这么做的而已,用以说明HASH碰撞的问题,对于这种简单SQL,有选择性更好的列,收集下统计信息,Oracle就可以将的SQL进行OR展开了。
三、加强SQL审核,解决性能问题于襁褓之中
应用系统SQL众多,如果总是作为救火队员角色解决线上问题,显然不能满足当今IT系统高速发展的需求,基于数据库的系统,主要性能问题在于SQL语句,如果能在开发测试阶段就对SQL语句进行审核,找出待优化SQL,并给予智能化提示,快速辅助优化,则可以避免众多线上问题。另外,还可以对线上SQL语句进行持续监控,及时发现性能存在问题的语句,从而达到SQL的全生命周期管理目的。
为此,公司结合多年运维和优化经验,自主研发了SQL审核工具,极大提升SQL审核优化和性能监控处理效率。
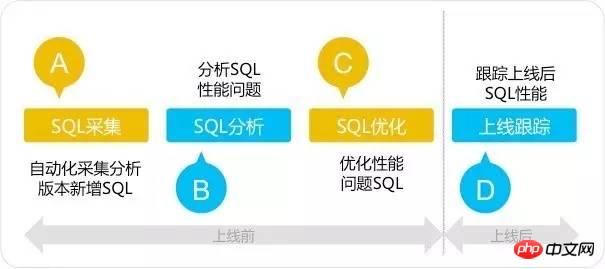
SQL审核工具采用四步法则:SQL采集—SQL分析—SQL优化—上线跟踪,SQL审核四步法区别传统的SQL优化方法,它着眼于系统上线前的SQL分析和优化,重点解决SQL问题于系统上线前,扼杀性能问题于襁褓之中。如下图所示:
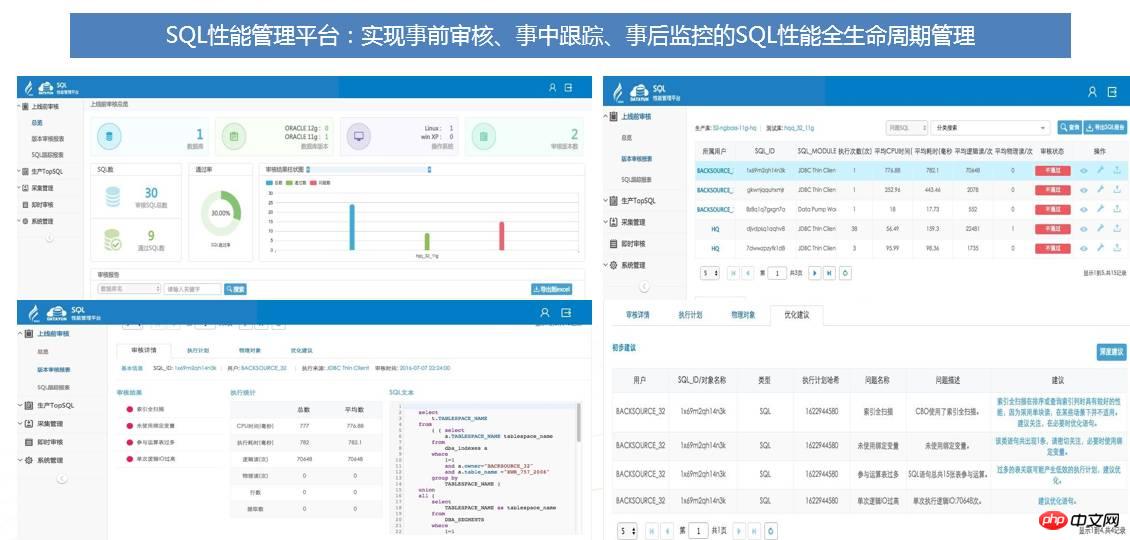
通过SQL性能管理平台可解决下列问题:
事前 : 上线前 SQL 性能审核,扼杀性能问题于襁褓之中;
事中:SQL性能监控处理,及时发现上线后SQL性能发生的变化,在SQL性能变化并且没有引起严重问题时,及时解决;
事后:TOPSQL监控,及时告警处理。
SQL性能管理平台实现了SQL性能的360度全生命周期管控,并且通过各种智能化提示和处理,将绝大多数本来因SQL引发的性能问题,解决在问题发生之前,提高系统稳定度。
下面是SQL审核的一个典型案例:
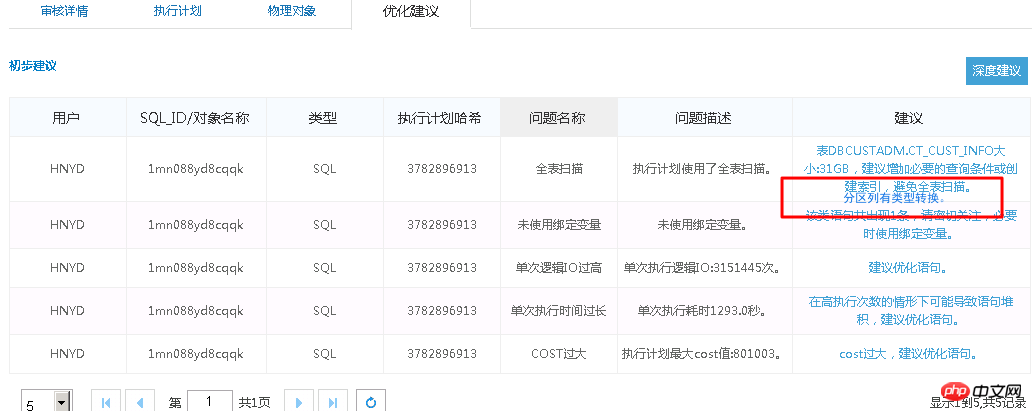
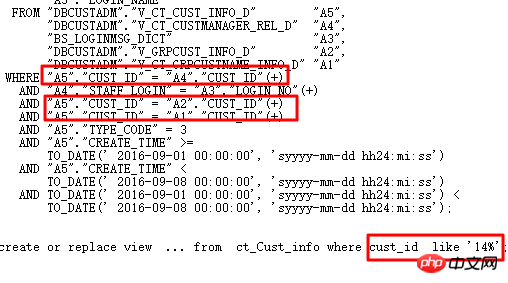
执行计划如下:
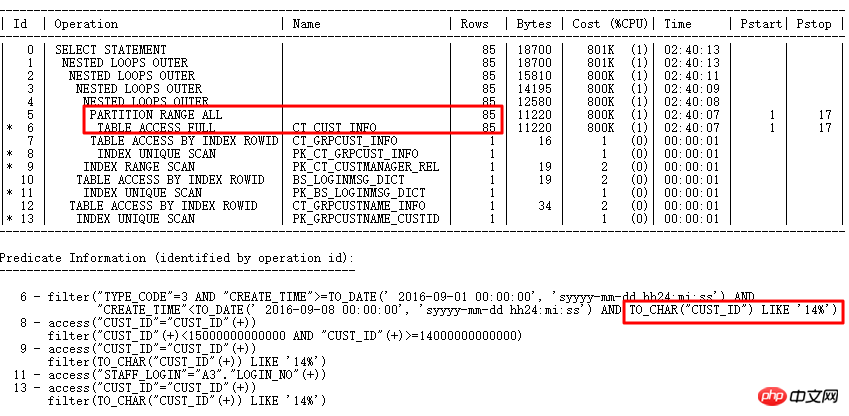
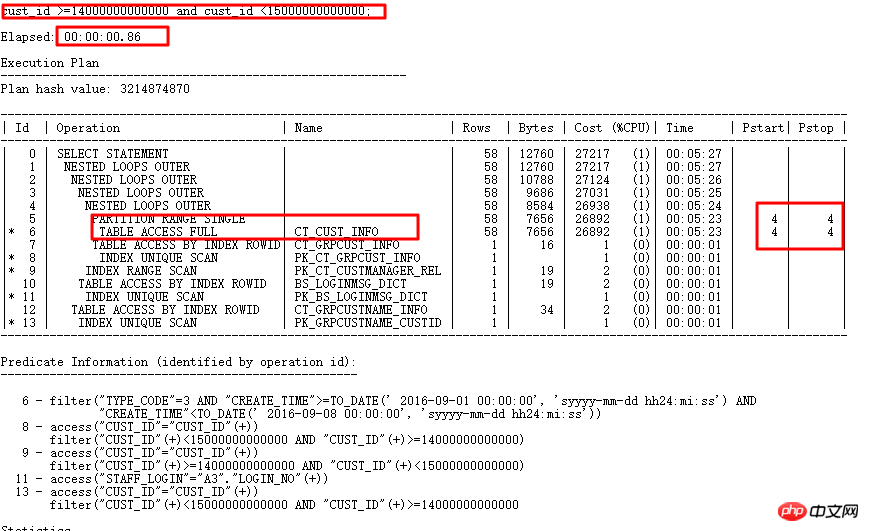
原SQL执行1688s。通过SQL审核智能优化准确找到优化点—分区列有类型转换。 优化后0.86s。
SQL审核是新炬数据库性能管理平台DPM的一个模块,想了解更多关于DPM的信息,可加邹德裕大师(微信:carydy)交流探讨。
今天主要和大家分享了一些Oracle优化器中存在的问题以及常见问题解决方法,当然,优化器问题不仅限于今天分享的,虽然CBO非常强大,并且在12c中有巨大改进,但是,存在的问题也很多,只有平时多积累和观察,掌握一定的方法,在能在遇到问题事后运筹帷幄,决胜千里。
Q&A
Q1: hash join是不是有排序,可以简单说说hash join的原理吗?
A1: ORACLE HASH JOIN自身不需要排序,这是区别SORTMERGE JOIN特点之一。ORACLE HASH JOIN原理比较复杂,可以参考Jonathan Lewis的Cost-Based Oracle Fundamentals的HASH JOIN部分,针对HASHJOIN最重要的是在原理基础上搞清楚什么时候会慢,比如HASH_AREA_SIZE过小,HASH TABLE不能完全放到内存中,那么会发生磁盘HASH运算,再比如上面讲的HASH碰撞发生。
Q2: 什么时候不走索引?
A2: 不走索引情况比较多,首要的原因就是统计信息不准导致的,第二原因就是选择性太低,走索引比走全扫效率更差,还有一个比较常见的就是对索引列进行了运算,导致无法走索引。其它还有很多原因会导致不能走索引,详细参考MOS文档:Diagnosing Why a Query is Not Using an Index (文档 ID 67522.1)。
Atas ialah kandungan terperinci 解决CBO的SQL优化问题(图文详解). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1386
1386
 52
52

 Mysql: Konsep mudah untuk pembelajaran mudah
Apr 10, 2025 am 09:29 AM
Mysql: Konsep mudah untuk pembelajaran mudah
Apr 10, 2025 am 09:29 AM
MySQL adalah sistem pengurusan pangkalan data sumber terbuka. 1) Buat Pangkalan Data dan Jadual: Gunakan perintah Createdatabase dan Createtable. 2) Operasi Asas: Masukkan, Kemas kini, Padam dan Pilih. 3) Operasi lanjutan: Sertai, subquery dan pemprosesan transaksi. 4) Kemahiran Debugging: Semak sintaks, jenis data dan keizinan. 5) Cadangan Pengoptimuman: Gunakan indeks, elakkan pilih* dan gunakan transaksi.
 Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Anda boleh membuka phpmyadmin melalui langkah -langkah berikut: 1. Log masuk ke panel kawalan laman web; 2. Cari dan klik ikon phpmyadmin; 3. Masukkan kelayakan MySQL; 4. Klik "Login".
 MySQL: Pengenalan kepada pangkalan data paling popular di dunia
Apr 12, 2025 am 12:18 AM
MySQL: Pengenalan kepada pangkalan data paling popular di dunia
Apr 12, 2025 am 12:18 AM
MySQL adalah sistem pengurusan pangkalan data relasi sumber terbuka, terutamanya digunakan untuk menyimpan dan mengambil data dengan cepat dan boleh dipercayai. Prinsip kerjanya termasuk permintaan pelanggan, resolusi pertanyaan, pelaksanaan pertanyaan dan hasil pulangan. Contoh penggunaan termasuk membuat jadual, memasukkan dan menanyakan data, dan ciri -ciri canggih seperti Operasi Join. Kesalahan umum melibatkan sintaks SQL, jenis data, dan keizinan, dan cadangan pengoptimuman termasuk penggunaan indeks, pertanyaan yang dioptimumkan, dan pembahagian jadual.
 Mengapa menggunakan mysql? Faedah dan kelebihan
Apr 12, 2025 am 12:17 AM
Mengapa menggunakan mysql? Faedah dan kelebihan
Apr 12, 2025 am 12:17 AM
MySQL dipilih untuk prestasi, kebolehpercayaan, kemudahan penggunaan, dan sokongan komuniti. 1.MYSQL Menyediakan fungsi penyimpanan dan pengambilan data yang cekap, menyokong pelbagai jenis data dan operasi pertanyaan lanjutan. 2. Mengamalkan seni bina pelanggan-pelayan dan enjin penyimpanan berganda untuk menyokong urus niaga dan pengoptimuman pertanyaan. 3. Mudah digunakan, menyokong pelbagai sistem operasi dan bahasa pengaturcaraan. 4. Mempunyai sokongan komuniti yang kuat dan menyediakan sumber dan penyelesaian yang kaya.
 Cara menggunakan redis berulir tunggal
Apr 10, 2025 pm 07:12 PM
Cara menggunakan redis berulir tunggal
Apr 10, 2025 pm 07:12 PM
Redis menggunakan satu seni bina berulir untuk memberikan prestasi tinggi, kesederhanaan, dan konsistensi. Ia menggunakan I/O multiplexing, gelung acara, I/O yang tidak menyekat, dan memori bersama untuk meningkatkan keserasian, tetapi dengan batasan batasan konkurensi, satu titik kegagalan, dan tidak sesuai untuk beban kerja yang berintensifkan.
 Beberapa kaedah biasa untuk pengoptimuman SQL
Apr 09, 2025 pm 04:42 PM
Beberapa kaedah biasa untuk pengoptimuman SQL
Apr 09, 2025 pm 04:42 PM
Kaedah pengoptimuman SQL biasa termasuk: Pengoptimuman Indeks: Buat pertanyaan yang diperolehi indeks yang sesuai. Pengoptimuman pertanyaan: Gunakan jenis pertanyaan yang betul, syarat gabungan yang sesuai, dan subqueries dan bukannya gabungan berbilang meja. Pengoptimuman Struktur Data: Pilih struktur jadual yang sesuai, jenis medan dan cuba mengelakkan menggunakan nilai null. Cache pertanyaan: Dayakan cache pertanyaan untuk menyimpan hasil pertanyaan yang sering dilaksanakan. Pengoptimuman Kolam Sambungan: Gunakan kolam sambungan ke sambungan pangkalan data multiplex. Pengoptimuman Transaksi: Elakkan transaksi bersarang, gunakan tahap pengasingan yang sesuai, dan operasi batch. Pengoptimuman Perkakasan: Meningkatkan perkakasan dan gunakan penyimpanan SSD atau NVME. Penyelenggaraan Pangkalan Data: Jalankan tugas penyelenggaraan indeks secara teratur, mengoptimumkan statistik, dan objek yang tidak digunakan. Pertanyaan
 MySQL dan SQL: Kemahiran Penting untuk Pemaju
Apr 10, 2025 am 09:30 AM
MySQL dan SQL: Kemahiran Penting untuk Pemaju
Apr 10, 2025 am 09:30 AM
MySQL dan SQL adalah kemahiran penting untuk pemaju. 1.MYSQL adalah sistem pengurusan pangkalan data sumber terbuka, dan SQL adalah bahasa standard yang digunakan untuk mengurus dan mengendalikan pangkalan data. 2.MYSQL menyokong pelbagai enjin penyimpanan melalui penyimpanan data yang cekap dan fungsi pengambilan semula, dan SQL melengkapkan operasi data yang kompleks melalui pernyataan mudah. 3. Contoh penggunaan termasuk pertanyaan asas dan pertanyaan lanjutan, seperti penapisan dan penyortiran mengikut keadaan. 4. Kesilapan umum termasuk kesilapan sintaks dan isu -isu prestasi, yang boleh dioptimumkan dengan memeriksa penyataan SQL dan menggunakan perintah menjelaskan. 5. Teknik pengoptimuman prestasi termasuk menggunakan indeks, mengelakkan pengimbasan jadual penuh, mengoptimumkan operasi menyertai dan meningkatkan kebolehbacaan kod.
 Tempat Mysql: Pangkalan Data dan Pengaturcaraan
Apr 13, 2025 am 12:18 AM
Tempat Mysql: Pangkalan Data dan Pengaturcaraan
Apr 13, 2025 am 12:18 AM
Kedudukan MySQL dalam pangkalan data dan pengaturcaraan sangat penting. Ia adalah sistem pengurusan pangkalan data sumber terbuka yang digunakan secara meluas dalam pelbagai senario aplikasi. 1) MySQL menyediakan fungsi penyimpanan data, organisasi dan pengambilan data yang cekap, sistem sokongan web, mudah alih dan perusahaan. 2) Ia menggunakan seni bina pelanggan-pelayan, menyokong pelbagai enjin penyimpanan dan pengoptimuman indeks. 3) Penggunaan asas termasuk membuat jadual dan memasukkan data, dan penggunaan lanjutan melibatkan pelbagai meja dan pertanyaan kompleks. 4) Soalan -soalan yang sering ditanya seperti kesilapan sintaks SQL dan isu -isu prestasi boleh disahpepijat melalui arahan jelas dan log pertanyaan perlahan. 5) Kaedah pengoptimuman prestasi termasuk penggunaan indeks rasional, pertanyaan yang dioptimumkan dan penggunaan cache. Amalan terbaik termasuk menggunakan urus niaga dan preparedStatemen
