

分享一个MySQL 多列索引优化实例代码

由于爬虫抓取的数据不断增多,这两天在不断对数据库以及查询语句进行优化,其中一个表结构如下:
CREATE TABLE `newspaper_article` ( `id` varchar(50) NOT NULL COMMENT '编号', `title` varchar(190) NOT NULL COMMENT '标题', `author` varchar(255) DEFAULT NULL COMMENT '作者', `date` date NULL DEFAULT NULL COMMENT '发表时间', `content` longtext COMMENT '正文', `status` tinyint(4) DEFAULT '0', PRIMARY KEY (`id`), KEY `idx_status_date` (`status`,`date`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='文章表';
根据业务需要,添加了 idx_status_date 索引,在执行下面这个 SQL 时特别耗时:
SELECT id, title, status, date FROM article WHERE status > -2 AND date = '2016-01-07';
根据观察,每天新增的数据大概在2500条以内,本以为这里指定了具体某天的日期 '2016-01-07' ,实际需要扫描的数据量应该在2500条以内才对,但实际并非如此:
实际共扫描了185589条数据,远远高于预估的2500条,且实际执行时间都将近3秒钟:

这是为什么呢?
解决方案
将 idx_status_date (status, date) 改为 idx_status (status) 后,查看 MySQL 执行计划:

可以看到将多列索引改为单列索引后,执行计划要扫描的数据总量没有任何变化。结合多列索引遵循最左前缀原则,推测上面的查询语句只使用了 idx_status_date 最左边的 status 的索引。
翻了下《高性能MySQL》找到了下面这段话,证实了我的想法:
如果查询中有某个列的范围查询,则其右边所有列都无法使用索引优化查找。例如有查询
WHERE last_name = 'Smith' AND first_name LIKE 'J%' AND dob = '1976-12-23',这个查询只能使用索引的前两列,因为这里LIKE是一个范围条件(但是服务器可以把其余列用于其他目的)。如果范围查询列值的数量有限,那么可以通过使用多个等于条件来代替范围条件。
因此,这里解决思路有两种:
可以通过使用多个等于条件来代替范围条件
修改
idx_status_date (status, date)为索引idx_date_status (date, status),并新建一个idx_status索引,即可达到同样的效果。
优化后的执行计划:

实际执行结果:
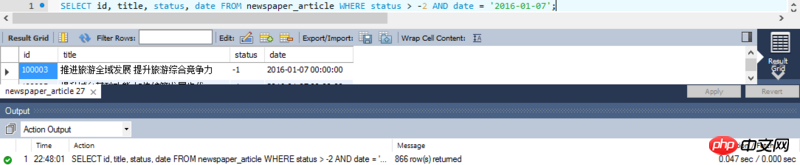
总结
当人们谈论索引的时候,如果没有特别指明类型,那么多半说的是 B-Tree 索引,它使用 B-Tree 数据结构来存储数据。我们使用术语“B-Tree”,是因为 MySQL 在 CREATE TABLE 和其他语句中也使用该关键字。不过,底层的存储引擎也可能使用不同的存储结构。InnoDB使用的是B+Tree。
假如有如下数据表:
CREATE TABLE People ( last_name varchar(50) not null, first_name varchar(50) not null, dob date not null, gender enum('m', 'f') not null, key(last_name, first_name, dob) );
B-Tree 索引对如下类型的查询有效
全值匹配
全值匹配指的是和索引中的所有列进行匹配,例如上表的索引可用于查找姓名为 Cuba Allen 、出生于 1960-01-01 的人。匹配最左前缀
上表中的索引可用于查找所有姓为 Allen 的人,即只使用索引的第一列。匹配列前缀
只匹配某一列的值的开头部分。例如上表的索引可用于查找所有以 J 开头的姓的人。这里也只使用了索引的第一列。匹配范围值
例如上表中的索引可用于查找姓在 Allen 和 Barrymore 之间的人。这里也只使用了索引的第一列。精确匹配某一列并范围匹配另外一列
上表的索引也可用于查找所有姓为 Allen ,并且名字是字母 K 开头(比如 Kim 、 Karl 等)的人。即第一列 last_name 全匹配,第二列 first_name 范围匹配。只访问索引的查询
B-Tree 通常可以支持“只访问索引的查询”,即查询只需要访问索引,而无须访问数据行。
B-Tree 索引的一些限制
如果不是按照索引的最左列开始查找,则无法使用索引。例如上表的索引无法用于查找名字为 Bill 的人,也无法查找某个特定生日的人,因为这两列都不是最左数据列。类似地,也无法查找姓氏以某个字母结尾的人。
不能跳过索引中列。也就是说,上表的索引无法用于查找姓氏为 Smith 并且在某个特定日期出生的人。如果不指定名(first_name),则 MySQL 只能使用索引的第一列。
如果查询中有某个列的范围查询,则其右边所有列都无法使用索引优化查找。例如有查询
WHERE last_name = 'Smith' AND first_name LIKE 'J%' AND dob = '1976-12-23',这个查询只能使用索引的前两列,因为这里LIKE是一个范围条件(但是服务器可以把其余列用于其他目的)。如果范围查询列值的数量有限,那么可以通过使用多个等于条件来代替范围条件。
Atas ialah kandungan terperinci 分享一个MySQL 多列索引优化实例代码. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1393
1393
 52
37
110
52
37
110

 Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Anda boleh membuka phpmyadmin melalui langkah -langkah berikut: 1. Log masuk ke panel kawalan laman web; 2. Cari dan klik ikon phpmyadmin; 3. Masukkan kelayakan MySQL; 4. Klik "Login".
 MySQL: Pengenalan kepada pangkalan data paling popular di dunia
Apr 12, 2025 am 12:18 AM
MySQL: Pengenalan kepada pangkalan data paling popular di dunia
Apr 12, 2025 am 12:18 AM
MySQL adalah sistem pengurusan pangkalan data relasi sumber terbuka, terutamanya digunakan untuk menyimpan dan mengambil data dengan cepat dan boleh dipercayai. Prinsip kerjanya termasuk permintaan pelanggan, resolusi pertanyaan, pelaksanaan pertanyaan dan hasil pulangan. Contoh penggunaan termasuk membuat jadual, memasukkan dan menanyakan data, dan ciri -ciri canggih seperti Operasi Join. Kesalahan umum melibatkan sintaks SQL, jenis data, dan keizinan, dan cadangan pengoptimuman termasuk penggunaan indeks, pertanyaan yang dioptimumkan, dan pembahagian jadual.
 Cara menggunakan redis berulir tunggal
Apr 10, 2025 pm 07:12 PM
Cara menggunakan redis berulir tunggal
Apr 10, 2025 pm 07:12 PM
Redis menggunakan satu seni bina berulir untuk memberikan prestasi tinggi, kesederhanaan, dan konsistensi. Ia menggunakan I/O multiplexing, gelung acara, I/O yang tidak menyekat, dan memori bersama untuk meningkatkan keserasian, tetapi dengan batasan batasan konkurensi, satu titik kegagalan, dan tidak sesuai untuk beban kerja yang berintensifkan.
 Tempat Mysql: Pangkalan Data dan Pengaturcaraan
Apr 13, 2025 am 12:18 AM
Tempat Mysql: Pangkalan Data dan Pengaturcaraan
Apr 13, 2025 am 12:18 AM
Kedudukan MySQL dalam pangkalan data dan pengaturcaraan sangat penting. Ia adalah sistem pengurusan pangkalan data sumber terbuka yang digunakan secara meluas dalam pelbagai senario aplikasi. 1) MySQL menyediakan fungsi penyimpanan data, organisasi dan pengambilan data yang cekap, sistem sokongan web, mudah alih dan perusahaan. 2) Ia menggunakan seni bina pelanggan-pelayan, menyokong pelbagai enjin penyimpanan dan pengoptimuman indeks. 3) Penggunaan asas termasuk membuat jadual dan memasukkan data, dan penggunaan lanjutan melibatkan pelbagai meja dan pertanyaan kompleks. 4) Soalan -soalan yang sering ditanya seperti kesilapan sintaks SQL dan isu -isu prestasi boleh disahpepijat melalui arahan jelas dan log pertanyaan perlahan. 5) Kaedah pengoptimuman prestasi termasuk penggunaan indeks rasional, pertanyaan yang dioptimumkan dan penggunaan cache. Amalan terbaik termasuk menggunakan urus niaga dan preparedStatemen
 Mengapa menggunakan mysql? Faedah dan kelebihan
Apr 12, 2025 am 12:17 AM
Mengapa menggunakan mysql? Faedah dan kelebihan
Apr 12, 2025 am 12:17 AM
MySQL dipilih untuk prestasi, kebolehpercayaan, kemudahan penggunaan, dan sokongan komuniti. 1.MYSQL Menyediakan fungsi penyimpanan dan pengambilan data yang cekap, menyokong pelbagai jenis data dan operasi pertanyaan lanjutan. 2. Mengamalkan seni bina pelanggan-pelayan dan enjin penyimpanan berganda untuk menyokong urus niaga dan pengoptimuman pertanyaan. 3. Mudah digunakan, menyokong pelbagai sistem operasi dan bahasa pengaturcaraan. 4. Mempunyai sokongan komuniti yang kuat dan menyediakan sumber dan penyelesaian yang kaya.
 Cara menyambung ke pangkalan data Apache
Apr 13, 2025 pm 01:03 PM
Cara menyambung ke pangkalan data Apache
Apr 13, 2025 pm 01:03 PM
Apache menyambung ke pangkalan data memerlukan langkah -langkah berikut: Pasang pemacu pangkalan data. Konfigurasikan fail web.xml untuk membuat kolam sambungan. Buat sumber data JDBC dan tentukan tetapan sambungan. Gunakan API JDBC untuk mengakses pangkalan data dari kod Java, termasuk mendapatkan sambungan, membuat kenyataan, parameter mengikat, melaksanakan pertanyaan atau kemas kini, dan hasil pemprosesan.
 Cara Memulakan MySQL oleh Docker
Apr 15, 2025 pm 12:09 PM
Cara Memulakan MySQL oleh Docker
Apr 15, 2025 pm 12:09 PM
Proses memulakan MySQL di Docker terdiri daripada langkah -langkah berikut: Tarik imej MySQL untuk membuat dan memulakan bekas, tetapkan kata laluan pengguna root, dan memetakan sambungan pengesahan port Buat pangkalan data dan pengguna memberikan semua kebenaran ke pangkalan data
 CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
Memasang MySQL pada CentOS melibatkan langkah -langkah berikut: Menambah sumber MySQL YUM yang sesuai. Jalankan YUM Pasang Perintah MySQL-Server untuk memasang pelayan MySQL. Gunakan perintah mysql_secure_installation untuk membuat tetapan keselamatan, seperti menetapkan kata laluan pengguna root. Sesuaikan fail konfigurasi MySQL seperti yang diperlukan. Tune parameter MySQL dan mengoptimumkan pangkalan data untuk prestasi.
