

python清洗字符串的实例详解

这篇文章主要介绍了python数据清洗之字符串处理的相关资料,需要的朋友可以参考下
前言
数据清洗是一项复杂且繁琐(kubi)的工作,同时也是整个数据分析过程中最为重要的环节。有人说一个分析项目80%的时间都是在清洗数据,这听起来有些匪夷所思,但在实际的工作中确实如此。数据清洗的目的有两个,第一是通过清洗让数据可用。第二是让数据变的更适合进行后续的分析工作。换句话说就是有”脏”数据要洗,干净的数据也要洗。
在数据分析中,特别是文本分析中,字符处理需要耗费极大的精力,因而了解字符处理对于数据分析而言,也是一项很重要的能力。
字符串处理方法
首先我们先了解下都有哪些基础方法
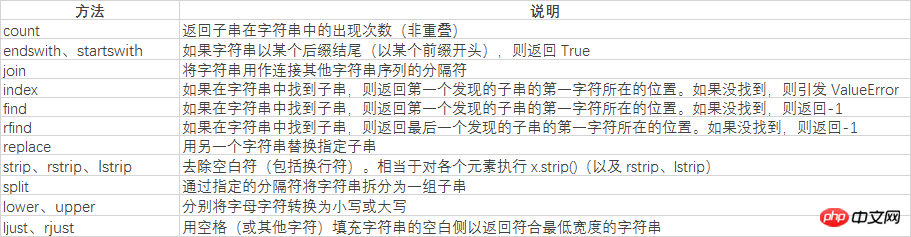
首先我们了解下字符串的拆分split方法
str='i like apple,i like bananer' print(str.split(','))
对字符str用逗号进行拆分的结果:
['i like apple', 'i like bananer']
print(str.split(' '))
根据空格拆分的结果:
['i', 'like', 'apple,i', 'like', 'bananer']
print(str.index(',')) print(str.find(','))
两个查找结果都为:
12
找不到的情况下index返回错误,find返回-1
print(str.count('i'))
结果为:
4
connt用于统计目标字符串的频率
print(str.replace(',', ' ').split(' '))
结果为:
['i', 'like', 'apple', 'i', 'like', 'bananer']
这里replace把逗号替换为空格后,在用空格对字符串进行分割,刚好能把每个单词取出来。
除了常规的方法以外,更强大的字符处理工具费正则表达式莫属了。
正则表达式
在使用正则表达式前我们还要先了解下,正则表达式中的诸多方法。

下面我来看下个方法的使用,首先了解下match和search方法的区别
str = "Cats are smarter than dogs" pattern=re.compile(r'(.*) are (.*?) .*') result=re.match(pattern,str) for i in range(len(result.groups())+1): print(result.group(i))
结果为:
Cats are smarter than dogs
Cats
smarter
这种形式的pettern匹配规则下,match和search方法的的返回结果是一样的
此时如果把pattern改为
pattern=re.compile(r'are (.*?) .*')
match则返回none,search返回结果为:
are smarter than dogs
smarter
接下来我们了解下其他方法的使用
str = "138-9592-5592 # number" pattern=re.compile(r'#.*$') number=re.sub(pattern,'',str) print(number)
结果为:
138-9592-5592
以上是通过把#号后面的内容替换为空实现提取号码的目的。
我们还可以进一步对号码的横杆进行替换
print(re.sub(r'-*','',number))
结果为:
13895925592
我们还可以用find的方法把找到的字符串打印出来
str = "138-9592-5592 # number" pattern=re.compile(r'5') print(pattern.findall(str))
结果为:
['5', '5', '5']
正则表达式的整体内容比较多,需要我们对匹配的字符串的规则有足够的了解,下面是具体的匹配规则。

矢量化字符串函数
清理待分析的散乱数据时,常常需要做一些字符串规整化工作。
data = pd.Series({'li': '120@qq.com','wang':'5632@qq.com',
'chen': '8622@xinlang.com','zhao':np.nan,'sun':'5243@gmail.com'})
print(data)结果为:

可以通过规整合的一些方法对数据做初步的判断,比如用contains 判断每个数据中是否含有关键词
print(data.str.contains('@'))
结果为:

也可以对字符串进行分拆,把需要的字符串提取出来
data = pd.Series({'li': '120@qq.com','wang':'5632@qq.com',
'chen': '8622@xinlang.com','zhao':np.nan,'sun':'5243@gmail.com'})
pattern=re.compile(r'(\d*)@([a-z]+)\.([a-z]{2,4})')
result=data.str.match(pattern) #这里用fillall的方法也可以result=data.str.findall(pattern)
print(result)结果为:
chen [(8622, xinlang, com)]
li [(120, qq, com)]
sun [(5243, gmail, com)]
wang [(5632, qq, com)]
zhao NaN
dtype: object
此时加入我们需要提取邮箱前面的名称
print(result.str.get(0))
结果为:

或者需要邮箱所属的域名
print(result.str.get(1))
结果为:

当然也可以用切片的方式进行提取,不过提取的数据准确性不高
data = pd.Series({'li': '120@qq.com','wang':'5632@qq.com',
'chen': '8622@xinlang.com','zhao':np.nan,'sun':'5243@gmail.com'})
print(data.str[:6])结果为:

最后我们了解下矢量化的字符串方法

总结
【相关推荐】
1. Python免费视频教程
3. Python基础入门教程
Atas ialah kandungan terperinci python清洗字符串的实例详解. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1386
1386
 52
52

 PHP dan Python: Contoh dan perbandingan kod
Apr 15, 2025 am 12:07 AM
PHP dan Python: Contoh dan perbandingan kod
Apr 15, 2025 am 12:07 AM
PHP dan Python mempunyai kelebihan dan kekurangan mereka sendiri, dan pilihannya bergantung kepada keperluan projek dan keutamaan peribadi. 1.PHP sesuai untuk pembangunan pesat dan penyelenggaraan aplikasi web berskala besar. 2. Python menguasai bidang sains data dan pembelajaran mesin.
 Python vs JavaScript: Komuniti, Perpustakaan, dan Sumber
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: Komuniti, Perpustakaan, dan Sumber
Apr 15, 2025 am 12:16 AM
Python dan JavaScript mempunyai kelebihan dan kekurangan mereka sendiri dari segi komuniti, perpustakaan dan sumber. 1) Komuniti Python mesra dan sesuai untuk pemula, tetapi sumber pembangunan depan tidak kaya dengan JavaScript. 2) Python berkuasa dalam bidang sains data dan perpustakaan pembelajaran mesin, sementara JavaScript lebih baik dalam perpustakaan pembangunan dan kerangka pembangunan depan. 3) Kedua -duanya mempunyai sumber pembelajaran yang kaya, tetapi Python sesuai untuk memulakan dengan dokumen rasmi, sementara JavaScript lebih baik dengan MDNWebDocs. Pilihan harus berdasarkan keperluan projek dan kepentingan peribadi.
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 Cara menjalankan program di terminal vscode
Apr 15, 2025 pm 06:42 PM
Cara menjalankan program di terminal vscode
Apr 15, 2025 pm 06:42 PM
Dalam kod VS, anda boleh menjalankan program di terminal melalui langkah -langkah berikut: Sediakan kod dan buka terminal bersepadu untuk memastikan bahawa direktori kod selaras dengan direktori kerja terminal. Pilih arahan Run mengikut bahasa pengaturcaraan (seperti python python your_file_name.py) untuk memeriksa sama ada ia berjalan dengan jayanya dan menyelesaikan kesilapan. Gunakan debugger untuk meningkatkan kecekapan debug.
 Python: Automasi, skrip, dan pengurusan tugas
Apr 16, 2025 am 12:14 AM
Python: Automasi, skrip, dan pengurusan tugas
Apr 16, 2025 am 12:14 AM
Python cemerlang dalam automasi, skrip, dan pengurusan tugas. 1) Automasi: Sandaran fail direalisasikan melalui perpustakaan standard seperti OS dan Shutil. 2) Penulisan Skrip: Gunakan Perpustakaan Psutil untuk memantau sumber sistem. 3) Pengurusan Tugas: Gunakan perpustakaan jadual untuk menjadualkan tugas. Kemudahan penggunaan Python dan sokongan perpustakaan yang kaya menjadikannya alat pilihan di kawasan ini.
 Apa itu vscode untuk apa vscode?
Apr 15, 2025 pm 06:45 PM
Apa itu vscode untuk apa vscode?
Apr 15, 2025 pm 06:45 PM
VS Kod adalah nama penuh Visual Studio Code, yang merupakan editor kod dan persekitaran pembangunan yang dibangunkan oleh Microsoft. Ia menyokong pelbagai bahasa pengaturcaraan dan menyediakan penonjolan sintaks, penyiapan automatik kod, coretan kod dan arahan pintar untuk meningkatkan kecekapan pembangunan. Melalui ekosistem lanjutan yang kaya, pengguna boleh menambah sambungan kepada keperluan dan bahasa tertentu, seperti debuggers, alat pemformatan kod, dan integrasi Git. VS Kod juga termasuk debugger intuitif yang membantu dengan cepat mencari dan menyelesaikan pepijat dalam kod anda.
 Boleh kod vs dijalankan di Windows 8
Apr 15, 2025 pm 07:24 PM
Boleh kod vs dijalankan di Windows 8
Apr 15, 2025 pm 07:24 PM
Kod VS boleh dijalankan pada Windows 8, tetapi pengalaman mungkin tidak hebat. Mula -mula pastikan sistem telah dikemas kini ke patch terkini, kemudian muat turun pakej pemasangan kod VS yang sepadan dengan seni bina sistem dan pasangnya seperti yang diminta. Selepas pemasangan, sedar bahawa beberapa sambungan mungkin tidak sesuai dengan Windows 8 dan perlu mencari sambungan alternatif atau menggunakan sistem Windows yang lebih baru dalam mesin maya. Pasang sambungan yang diperlukan untuk memeriksa sama ada ia berfungsi dengan betul. Walaupun kod VS boleh dilaksanakan pada Windows 8, disyorkan untuk menaik taraf ke sistem Windows yang lebih baru untuk pengalaman dan keselamatan pembangunan yang lebih baik.
 Bolehkah kod studio visual digunakan dalam python
Apr 15, 2025 pm 08:18 PM
Bolehkah kod studio visual digunakan dalam python
Apr 15, 2025 pm 08:18 PM
Kod VS boleh digunakan untuk menulis Python dan menyediakan banyak ciri yang menjadikannya alat yang ideal untuk membangunkan aplikasi python. Ia membolehkan pengguna untuk: memasang sambungan python untuk mendapatkan fungsi seperti penyempurnaan kod, penonjolan sintaks, dan debugging. Gunakan debugger untuk mengesan kod langkah demi langkah, cari dan selesaikan kesilapan. Mengintegrasikan Git untuk Kawalan Versi. Gunakan alat pemformatan kod untuk mengekalkan konsistensi kod. Gunakan alat linting untuk melihat masalah yang berpotensi lebih awal.
