

python实现网络段子页爬虫案例

网上的Python教程大都是2.X版本的,python2.X和python3.X相比较改动比较大,好多库的用法不太一样,我安装的是python3.X,我们来看看详细的例子
0x01
春节闲着没事(是有多闲),就写了个简单的程序,来爬点笑话看,顺带记录下写程序的过程。第一次接触爬虫是看了这么一个帖子,一个逗逼,爬取煎蛋网上妹子的照片,简直不要太方便。于是乎就自己照猫画虎,抓了点图片。
科技启迪未来,身为一个程序员,怎么能干这种事呢,还是爬点笑话比较有益于身心健康。

0x02
在我们撸起袖子开始搞之前,先来普及点理论知识。
简单地说,我们要把网页上特定位置的内容,扒拉下来,具体怎么扒拉,我们得先分析这个网页,看那块内容是我们需要的。比如,这次爬取的是捧腹网上的笑话,打开 捧腹网段子页我们可以看到一大堆笑话,我们的目的就是获取这些内容。看完回来冷静一下,你这样一直笑,我们没办法写代码。在 chrome 中,我们打开 审查元素 然后一级一级的展开 HTML 标签,或者点击那个小鼠标,定位我们所需要的元素。
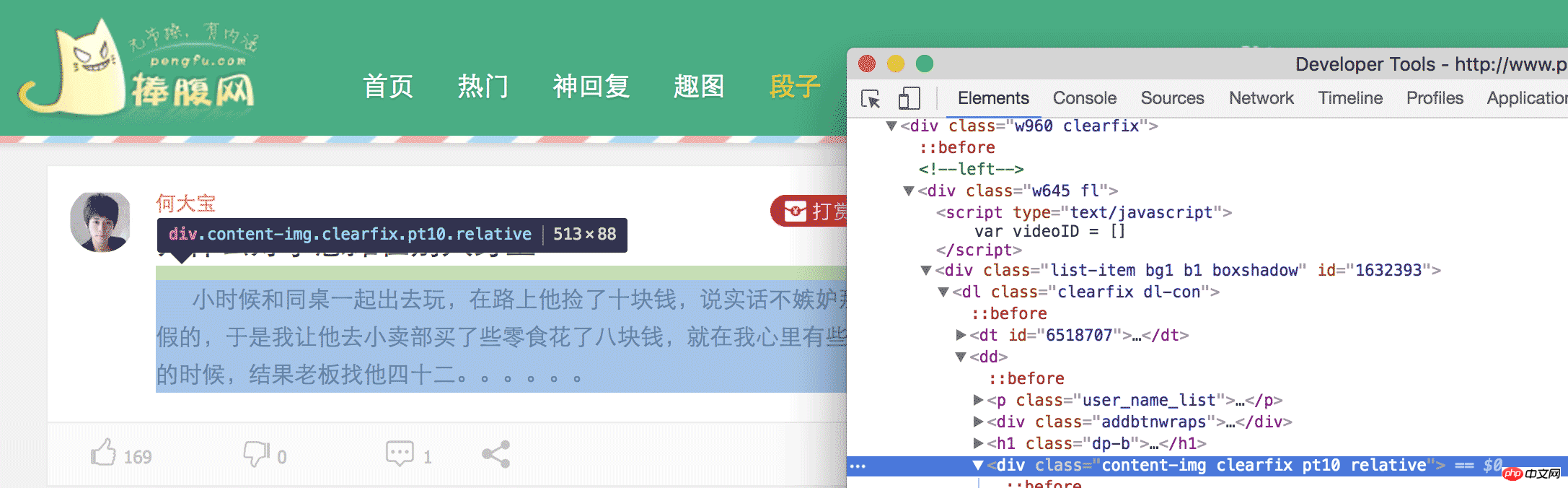
最后可以发现
中的内容就是我们所需要的笑话,在看第二条笑话,也是这样。于是乎,我们就可以把这个网页中所有的
找到,然后把里边的内容提取出来,就完成了。
0x03
好了,现在我们知道我们的目的了,就可以撸起袖子开始干了。这里我用的 python3,关于 python2 和 python3 的选用,大家可以自行决定,功能都可以实现,只是有些许不同。但还是建议用 python3。
我们要扒拉下我们需要的内容,首先我们得把这个网页扒拉下来,怎么扒拉呢,这里我们要用到一个库,叫 urllib,我们用这个库提供的方法,来获取整个网页。
首先,我们导入 urllib
代码如下:
import urllib.request as request
然后,我们就可以使用 request 来获取网页了,
代码如下:
return request.urlopen(url).read()
人生苦短,我用 python,一行代码,下载网页,你说,还有什么理由不用 python。
下载完网页后,我们就得解析这个网页了来获取我们所需要的元素。为了解析元素,我们需要使用另外一个工具,叫做 Beautiful Soup,使用它,可以快速解析 HTML 和 XML并获取我们所需要的元素。
代码如下:
soup = BeautifulSoup(getHTML("http://www.pengfu.com/xiaohua_1.html"))用 BeautifulSoup 来解析网页也就一句话,但当你运行代码的时候,会出现这么一个警告,提示要指定一个解析器,不然,可能会在其他平台或者系统上报错。
代码如下:
/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/bs4/init.py:181: UserWarning: No parser was explicitly specified, so I'm using the best available HTML parser for this system ("lxml"). This usually isn't a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently.
The code that caused this warning is on line 64 of the file joke.py. To get rid of this warning, change code that looks like this:
BeautifulSoup([your markup])
to this:
BeautifulSoup([your markup], "lxml")
markup_type=markup_type))解析器的种类 和 不同解析器之间的区别 官方文档有详细的说明,目前来说,还是用 lxml 解析比较靠谱。
修改之后
代码如下:
soup = BeautifulSoup(getHTML("http://www.pengfu.com/xiaohua_1.html", 'lxml'))这样,就没有上述警告了。
代码如下:
p_array = soup.find_all('p', {'class':"content-img clearfix pt10 relative"})利用 find_all 函数,来找到所有 class = content-img clearfix pt10 relative 的 p 标签 然后遍历这个数组
代码如下:
for x in p_array: content = x.string
这样,我们就取到了目的 p 的内容。至此,我们已经达到了我们的目的,爬到了我们的笑话。
但当以同样的方式去爬取糗百的时候,会报这样一个错误
代码如下:
raise RemoteDisconnected("Remote end closed connection without" http.client.RemoteDisconnected: Remote end closed connection without response说远端无响应,关闭了链接,看了下网络也没有问题,这是什么情况导致的呢?莫非是我姿势不对?
打开 charles 抓包,果然也没反应。唉,这就奇怪了,好好的一个网站,怎么浏览器可以访问,python 无法访问呢,是不是 UA 的问题呢?看了下 charles,发现,利用 urllib 发起的请求,UA 默认是 Python-urllib/3.5 而在 chrome 中访问 UA 则是 User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36,那会不会是因为服务器根据 UA 来判断拒绝了 python 爬虫。我们来伪装下试试看行不行
代码如下:
def getHTML(url):
head
ers = {'User-Agent': 'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
req = request.Request(url, headers=headers)
return request.urlopen(req).read()这样就把 python 伪装成 chrome 去获取糗百的网页,可以顺利的得到数据。
至此,利用 python 爬取糗百和捧腹网的笑话已经结束,我们只需要分析相应的网页,找到我们感兴趣的元素,利用 python 强大的功能,就可以达到我们的目的,不管是 XXOO 的图,还是内涵段子,都可以一键搞定,不说了,我去找点妹子图看看。
# -*- coding: utf-8 -*-
import sys
import urllib.request as request
from bs4 import BeautifulSoup
def getHTML(url):
headers = {'User-Agent': 'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
req = request.Request(url, headers=headers)
return request.urlopen(req).read()
def get_pengfu_results(url):
soup = BeautifulSoup(getHTML(url), 'lxml')
return soup.find_all('p', {'class':"content-img clearfix pt10 relative"})
def get_pengfu_joke():
for x in range(1, 2):
url = 'http://www.pengfu.com/xiaohua_%d.html' % x
for x in get_pengfu_results(url):
content = x.string
try:
string = content.lstrip()
print(string + '\n\n')
except:
continue
return
def get_qiubai_results(url):
soup = BeautifulSoup(getHTML(url), 'lxml')
contents = soup.find_all('p', {'class':'content'})
restlus = []
for x in contents:
str = x.find('span').getText('\n','<br/>')
restlus.append(str)
return restlus
def get_qiubai_joke():
for x in range(1, 2):
url = 'http://www.qiushibaike.com/8hr/page/%d/?s=4952526' % x
for x in get_qiubai_results(url):
print(x + '\n\n')
return
if name == 'main':
get_pengfu_joke()
get_qiubai_joke()【相关推荐】
1. Python免费视频教程
3. Python基础入门手册
Atas ialah kandungan terperinci python实现网络段子页爬虫案例. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 PHP dan Python: Paradigma yang berbeza dijelaskan
Apr 18, 2025 am 12:26 AM
PHP dan Python: Paradigma yang berbeza dijelaskan
Apr 18, 2025 am 12:26 AM
PHP terutamanya pengaturcaraan prosedur, tetapi juga menyokong pengaturcaraan berorientasikan objek (OOP); Python menyokong pelbagai paradigma, termasuk pengaturcaraan OOP, fungsional dan prosedur. PHP sesuai untuk pembangunan web, dan Python sesuai untuk pelbagai aplikasi seperti analisis data dan pembelajaran mesin.
 Python vs JavaScript: Keluk Pembelajaran dan Kemudahan Penggunaan
Apr 16, 2025 am 12:12 AM
Python vs JavaScript: Keluk Pembelajaran dan Kemudahan Penggunaan
Apr 16, 2025 am 12:12 AM
Python lebih sesuai untuk pemula, dengan lengkung pembelajaran yang lancar dan sintaks ringkas; JavaScript sesuai untuk pembangunan front-end, dengan lengkung pembelajaran yang curam dan sintaks yang fleksibel. 1. Sintaks Python adalah intuitif dan sesuai untuk sains data dan pembangunan back-end. 2. JavaScript adalah fleksibel dan digunakan secara meluas dalam pengaturcaraan depan dan pelayan.
 Memilih antara php dan python: panduan
Apr 18, 2025 am 12:24 AM
Memilih antara php dan python: panduan
Apr 18, 2025 am 12:24 AM
PHP sesuai untuk pembangunan web dan prototaip pesat, dan Python sesuai untuk sains data dan pembelajaran mesin. 1.Php digunakan untuk pembangunan web dinamik, dengan sintaks mudah dan sesuai untuk pembangunan pesat. 2. Python mempunyai sintaks ringkas, sesuai untuk pelbagai bidang, dan mempunyai ekosistem perpustakaan yang kuat.
 Boleh kod vs dijalankan di Windows 8
Apr 15, 2025 pm 07:24 PM
Boleh kod vs dijalankan di Windows 8
Apr 15, 2025 pm 07:24 PM
Kod VS boleh dijalankan pada Windows 8, tetapi pengalaman mungkin tidak hebat. Mula -mula pastikan sistem telah dikemas kini ke patch terkini, kemudian muat turun pakej pemasangan kod VS yang sepadan dengan seni bina sistem dan pasangnya seperti yang diminta. Selepas pemasangan, sedar bahawa beberapa sambungan mungkin tidak sesuai dengan Windows 8 dan perlu mencari sambungan alternatif atau menggunakan sistem Windows yang lebih baru dalam mesin maya. Pasang sambungan yang diperlukan untuk memeriksa sama ada ia berfungsi dengan betul. Walaupun kod VS boleh dilaksanakan pada Windows 8, disyorkan untuk menaik taraf ke sistem Windows yang lebih baru untuk pengalaman dan keselamatan pembangunan yang lebih baik.
 Bolehkah kod studio visual digunakan dalam python
Apr 15, 2025 pm 08:18 PM
Bolehkah kod studio visual digunakan dalam python
Apr 15, 2025 pm 08:18 PM
Kod VS boleh digunakan untuk menulis Python dan menyediakan banyak ciri yang menjadikannya alat yang ideal untuk membangunkan aplikasi python. Ia membolehkan pengguna untuk: memasang sambungan python untuk mendapatkan fungsi seperti penyempurnaan kod, penonjolan sintaks, dan debugging. Gunakan debugger untuk mengesan kod langkah demi langkah, cari dan selesaikan kesilapan. Mengintegrasikan Git untuk Kawalan Versi. Gunakan alat pemformatan kod untuk mengekalkan konsistensi kod. Gunakan alat linting untuk melihat masalah yang berpotensi lebih awal.
 PHP dan Python: menyelam mendalam ke dalam sejarah mereka
Apr 18, 2025 am 12:25 AM
PHP dan Python: menyelam mendalam ke dalam sejarah mereka
Apr 18, 2025 am 12:25 AM
PHP berasal pada tahun 1994 dan dibangunkan oleh Rasmuslerdorf. Ia pada asalnya digunakan untuk mengesan pelawat laman web dan secara beransur-ansur berkembang menjadi bahasa skrip sisi pelayan dan digunakan secara meluas dalam pembangunan web. Python telah dibangunkan oleh Guidovan Rossum pada akhir 1980 -an dan pertama kali dikeluarkan pada tahun 1991. Ia menekankan kebolehbacaan dan kesederhanaan kod, dan sesuai untuk pengkomputeran saintifik, analisis data dan bidang lain.
 Cara menjalankan program di terminal vscode
Apr 15, 2025 pm 06:42 PM
Cara menjalankan program di terminal vscode
Apr 15, 2025 pm 06:42 PM
Dalam kod VS, anda boleh menjalankan program di terminal melalui langkah -langkah berikut: Sediakan kod dan buka terminal bersepadu untuk memastikan bahawa direktori kod selaras dengan direktori kerja terminal. Pilih arahan Run mengikut bahasa pengaturcaraan (seperti python python your_file_name.py) untuk memeriksa sama ada ia berjalan dengan jayanya dan menyelesaikan kesilapan. Gunakan debugger untuk meningkatkan kecekapan debug.
 Adakah sambungan vscode berniat jahat?
Apr 15, 2025 pm 07:57 PM
Adakah sambungan vscode berniat jahat?
Apr 15, 2025 pm 07:57 PM
Sambungan kod VS menimbulkan risiko yang berniat jahat, seperti menyembunyikan kod jahat, mengeksploitasi kelemahan, dan melancap sebagai sambungan yang sah. Kaedah untuk mengenal pasti sambungan yang berniat jahat termasuk: memeriksa penerbit, membaca komen, memeriksa kod, dan memasang dengan berhati -hati. Langkah -langkah keselamatan juga termasuk: kesedaran keselamatan, tabiat yang baik, kemas kini tetap dan perisian antivirus.
