

这篇文章主要给大家介绍了关于python爬虫入门之利用requests构建知乎API的相关资料,文中通过示例代码介绍的非常详细,对大家具有一定的参考学习价值,需要的朋友们下面来一起看看吧。
前言
在爬虫系列文章 优雅的HTTP库requests 中介绍了 requests 的使用方式,这一次我们用 requests 构建一个知乎 API,功能包括:私信发送、文章点赞、用户关注等,因为任何涉及用户操作的功能都需要登录后才操作,所以在阅读这篇文章前建议先了解Python模拟知乎登录 。现在假设你已经知道如何用 requests 模拟知乎登录了。
思路分析
发送私信的过程就是浏览器向服务器发送一个 HTTP 请求,请求报文包括请求 URL、请求头 Header、还有请求体 Body,只要把这些信息弄清楚,那么就很容易用 requests 来模拟浏览器发送私信了。
打开 Chrome 浏览器,随便找一个用户,点击发送私信,追踪一下私信的网络请求过程。
先看下请求头信息

请求头 Header 中有 cookies 登录信息,此外还有一个 authorization 字段,该字段是用于用户认证的,同时这个字段也存在 cookies 中(为了防止 cookie 信息泄露,我打了马赛克), requests 请求时这些信息都必须携带上。
再来看看请求的URL和请求体

请求URL是 www.zhihu.com/api/v4/messages ,请求方法是 POST,请求体
{"type":"common","content":"你好,我是pythoner","receiver_hash":"1da75b85900e00adb072e91c56fd9149"}请求体是一个 json 字符串,type 和 content 很好理解,但 receiver_hash 是什么并不知道,需要进一步确定,不过你应该猜得出这是类似于用户 id 的字段。
那么现在问题来了,如何通过用户主页的URL找到用户的 id 呢?为了完整的模拟私信的整个流程,我特地注册了一个知乎小号。
如果你手头没有多余的手机号,可以用 Google 搜「receive sms online」,网上很多提供免费在线接收短信的手机号码,我注册的小号主页:https://www.zhihu.com/people/xiaoxiaodouzi
先尝试关注小号,然后在我关注的列表中找到该小号,把鼠标移到小号的头像处时,发现有一个 HTTP 网络请求。
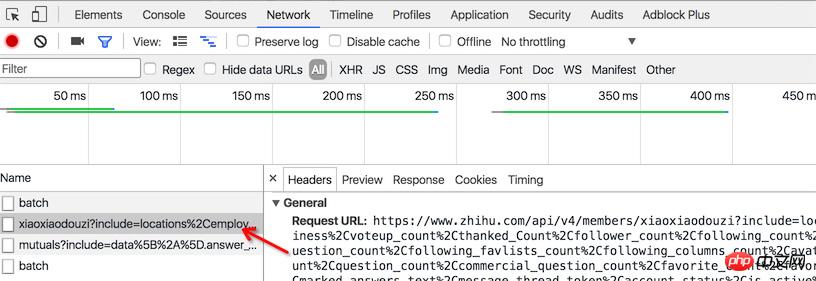
请求 url 是 www.zhihu.com/api/v4/members/xiaoxiaodouzi ,这个URL的后面部分「xiaoxiaodouzi」对应小号主页URL的后面部分,这部分我们称之为 url_token。
接口的返回数据是该用户的个人公开信息。
{
...
"id":"1da75b85900e00adb072e91c56fd9149",
"favorite_count":0,
"voteup_count":0,
"commercial_question_count":0,
"url_token":"xiaoxiaodouzi",
"type":"people",
"avatar_url":"https://pic1.zhimg.com/v2-ca13758626bd7367febde704c66249ec_is.jpg",
"is_active":1492224390,
"name":"\u6211\u662f\u5c0f\u53f7",
"url":"http://www.zhihu.com/api/v4/people/1da75b85900e00adb072e91c56fd9149",
"gender":-1
...
}我们可以很清楚的看到有个id的字段,跟我们之前猜测的一样,私信里面的 receiver_hash 字段就是用户的id。
代码实现
到此我们把私信功能的思路理清楚了,代码实现就是水到渠成的事情了。
用户信息
为了得到私信接口需要的 receiver_hash 字典,我们先要获取用户信息,该信息里面含有用于的id值。
@need_login def user(self, url_token): """ 获取用户信息, :param url_token: url_token 是用户主页url中后面部分 例如: https://www.zhihu.com/people/xiaoxiaodouzi url_token 是 xiaoxiaodouzi :return:dict """ response = self._session.get(URL.profile(url_token)) return response.json()
发送私信
@need_login
def send_message(self, user_id, content):
"""
给指定的用户发私信
:param user_id: 用户ID
:param content: 私信内容
"""
data = {"type": "common", "content": content, "receiver_hash": user_id}
response = self._session.post(URL.message(), json=data)
data = response.json()
if data.get("error"):
self.logger.info("私信发送失败, %s" % data.get("error").get("message"))
else:
self.logger.info("发送成功")
return data上面两个方法放在一个叫Zhihu的类里面,我只列出了关键代码,涉及到的 @need_login 是一个用户认证的装饰器,表示该方法需要登录后才能操作。细心的你可能发现,每个请求中我并没有显示地指定 Header 字段,那时因为我把它放在 init.py 方法中初始化了。
def init(self):
self._session = requests.session()
self._session.verify = False
self._session.headers = {"Host": "www.zhihu.com",
"Referer": "https://www.zhihu.com/",
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36'
' (KHTML, like Gecko) Chrome/56.0.2924.87',
}
self._session.cookies = cookiejar.LWPCookieJar(filename=cookie_filename)
try:
self._session.cookies.load(ignore_discard=True)
except:
pass调用执行
from zhihu import Zhihu
if name == 'main':
zhihu = Zhihu()
profile = zhihu.user("xiaoxiaodouzi")
_id = profile.get("id")
zhihu.send_message(_id, "你好,这是来自Python之禅的问候")执行完成后,小号成功收到我发送的私信。

最后,我们可以按照类似的思路把关注用户,点赞等功能实现了。
【相关推荐】
2. python爬虫入门(4)--详解HTML文本的解析库BeautifulSoup
3. python爬虫入门(2)--HTTP库requests
Atas ialah kandungan terperinci python爬虫入门(3)--利用requests构建知乎API. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



