

多页面爬虫在nodejs中的示例代码分析

本篇文章主要介绍了基于nodejs 的多页面爬虫 ,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧
前言
前端时间再回顾了一下node.js,于是顺势做了一个爬虫来加深自己对node的理解。
主要用的到是request,cheerio,async三个模块
request
用于请求地址和快速下载图片流。
cheerio
为服务器特别定制的,快速、灵活、实施的jQuery核心实现.
便于解析html代码。
async
异步调用,防止堵塞。
核心思路
用request 发送一个请求。获取html代码,取得其中的img标签和a标签。
通过获取的a表情进行递归调用。不断获取img地址和a地址,继续递归
获取img地址通过request(photo).pipe(fs.createWriteStream(dir + “/” + filename));进行快速下载。
function requestall(url) {
request({
uri: url,
headers: setting.header
}, function (error, response, body) {
if (error) {
console.log(error);
} else {
console.log(response.statusCode);
if (!error && response.statusCode == 200) {
var $ = cheerio.load(body);
var photos = [];
$('img').each(function () {
// 判断地址是否存在
if ($(this).attr('src')) {
var src = $(this).attr('src');
var end = src.substr(-4, 4).toLowerCase();
if (end == '.jpg' || end == '.png' || end == '.jpeg') {
if (IsURL(src)) {
photos.push(src);
}
}
}
});
downloadImg(photos, dir, setting.download_v);
// 递归爬虫
$('a').each(function () {
var murl = $(this).attr('href');
if (IsURL(murl)) {
setTimeout(function () {
fetchre(murl);
}, timeout);
timeout += setting.ajax_timeout;
} else {
setTimeout(function () {
fetchre("http://www.ivsky.com/" + murl);
}, timeout);
timeout += setting.ajax_timeout;
}
})
}
}
});
}防坑
1.在request通过图片地址下载时,绑定error事件防止爬虫异常的中断。
2.通过async的mapLimit限制并发。
3.加入请求报头,防止ip被屏蔽。
4.获取一些图片和超链接地址,可能是相对路径(待考虑解决是否有通过方法)。
function downloadImg(photos, dir, asyncNum) {
console.log("即将异步并发下载图片,当前并发数为:" + asyncNum);
async.mapLimit(photos, asyncNum, function (photo, callback) {
var filename = (new Date().getTime()) + photo.substr(-4, 4);
if (filename) {
console.log('正在下载' + photo);
// 默认
// fs.createWriteStream(dir + "/" + filename)
// 防止pipe错误
request(photo)
.on('error', function (err) {
console.log(err);
})
.pipe(fs.createWriteStream(dir + "/" + filename));
console.log('下载完成');
callback(null, filename);
}
}, function (err, result) {
if (err) {
console.log(err);
} else {
console.log(" all right ! ");
console.log(result);
}
})
}测试:
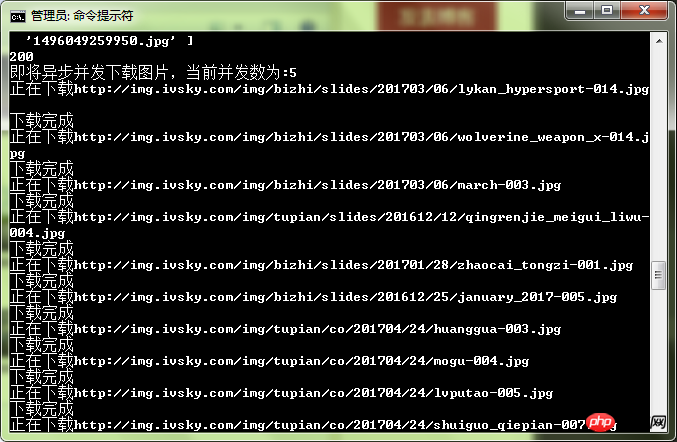
可以感觉到速度还是比较快的。
Atas ialah kandungan terperinci 多页面爬虫在nodejs中的示例代码分析. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1386
1386
 52
52

 Perbezaan antara nodejs dan vuejs
Apr 21, 2024 am 04:17 AM
Perbezaan antara nodejs dan vuejs
Apr 21, 2024 am 04:17 AM
Node.js ialah masa jalan JavaScript bahagian pelayan, manakala Vue.js ialah rangka kerja JavaScript sisi klien untuk mencipta antara muka pengguna interaktif. Node.js digunakan untuk pembangunan bahagian pelayan, seperti pembangunan API perkhidmatan belakang dan pemprosesan data, manakala Vue.js digunakan untuk pembangunan sisi klien, seperti aplikasi satu halaman dan antara muka pengguna yang responsif.
 Adakah nodejs rangka kerja bahagian belakang?
Apr 21, 2024 am 05:09 AM
Adakah nodejs rangka kerja bahagian belakang?
Apr 21, 2024 am 05:09 AM
Node.js boleh digunakan sebagai rangka kerja bahagian belakang kerana ia menawarkan ciri seperti prestasi tinggi, kebolehskalaan, sokongan merentas platform, ekosistem yang kaya dan kemudahan pembangunan.
 Bagaimana untuk menyambungkan nodejs ke pangkalan data mysql
Apr 21, 2024 am 06:13 AM
Bagaimana untuk menyambungkan nodejs ke pangkalan data mysql
Apr 21, 2024 am 06:13 AM
Untuk menyambung ke pangkalan data MySQL, anda perlu mengikuti langkah berikut: Pasang pemacu mysql2. Gunakan mysql2.createConnection() untuk mencipta objek sambungan yang mengandungi alamat hos, port, nama pengguna, kata laluan dan nama pangkalan data. Gunakan connection.query() untuk melaksanakan pertanyaan. Akhir sekali gunakan connection.end() untuk menamatkan sambungan.
 Apakah perbezaan antara fail npm dan npm.cmd dalam direktori pemasangan nodejs?
Apr 21, 2024 am 05:18 AM
Apakah perbezaan antara fail npm dan npm.cmd dalam direktori pemasangan nodejs?
Apr 21, 2024 am 05:18 AM
Terdapat dua fail berkaitan npm dalam direktori pemasangan Node.js: npm dan npm.cmd Perbezaannya adalah seperti berikut: sambungan berbeza: npm ialah fail boleh laku dan npm.cmd ialah pintasan tetingkap arahan. Pengguna Windows: npm.cmd boleh digunakan daripada command prompt, npm hanya boleh dijalankan dari baris arahan. Keserasian: npm.cmd adalah khusus untuk sistem Windows, npm tersedia merentas platform. Cadangan penggunaan: Pengguna Windows menggunakan npm.cmd, sistem pengendalian lain menggunakan npm.
 Apakah pembolehubah global dalam nodejs
Apr 21, 2024 am 04:54 AM
Apakah pembolehubah global dalam nodejs
Apr 21, 2024 am 04:54 AM
Pembolehubah global berikut wujud dalam Node.js: Objek global: modul Teras global: proses, konsol, memerlukan pembolehubah persekitaran Runtime: __dirname, __filename, __line, __column Constants: undefined, null, NaN, Infinity, -Infinity
 Adakah terdapat perbezaan besar antara nodejs dan java?
Apr 21, 2024 am 06:12 AM
Adakah terdapat perbezaan besar antara nodejs dan java?
Apr 21, 2024 am 06:12 AM
Perbezaan utama antara Node.js dan Java ialah reka bentuk dan ciri: Didorong peristiwa vs. didorong benang: Node.js dipacu peristiwa dan Java dipacu benang. Satu-benang vs. berbilang benang: Node.js menggunakan gelung acara satu-benang dan Java menggunakan seni bina berbilang benang. Persekitaran masa jalan: Node.js berjalan pada enjin JavaScript V8, manakala Java berjalan pada JVM. Sintaks: Node.js menggunakan sintaks JavaScript, manakala Java menggunakan sintaks Java. Tujuan: Node.js sesuai untuk tugas intensif I/O, manakala Java sesuai untuk aplikasi perusahaan besar.
 Adakah nodejs bahasa pembangunan bahagian belakang?
Apr 21, 2024 am 05:09 AM
Adakah nodejs bahasa pembangunan bahagian belakang?
Apr 21, 2024 am 05:09 AM
Ya, Node.js ialah bahasa pembangunan bahagian belakang. Ia digunakan untuk pembangunan bahagian belakang, termasuk mengendalikan logik perniagaan sebelah pelayan, mengurus sambungan pangkalan data dan menyediakan API.
 Bagaimana untuk menggunakan projek nodejs ke pelayan
Apr 21, 2024 am 04:40 AM
Bagaimana untuk menggunakan projek nodejs ke pelayan
Apr 21, 2024 am 04:40 AM
Langkah-langkah penggunaan pelayan untuk projek Node.js: Sediakan persekitaran penggunaan: dapatkan akses pelayan, pasang Node.js, sediakan repositori Git. Bina aplikasi: Gunakan npm run build untuk menjana kod dan kebergantungan yang boleh digunakan. Muat naik kod ke pelayan: melalui Git atau Protokol Pemindahan Fail. Pasang kebergantungan: SSH ke dalam pelayan dan gunakan pemasangan npm untuk memasang kebergantungan aplikasi. Mulakan aplikasi: Gunakan arahan seperti node index.js untuk memulakan aplikasi, atau gunakan pengurus proses seperti pm2. Konfigurasikan proksi terbalik (pilihan): Gunakan proksi terbalik seperti Nginx atau Apache untuk menghalakan trafik ke aplikasi anda
