

理解什么是Node.js?

理解Node.js
为了理解Node.js是如何工作的,首先你需要理解一些使得Javascript适用于服务器端开发的关键特性。Javascript是一门简单而又灵活的语言,这种灵活性让它能够经受住时间的考验。函数、闭包等特性使Javascript成为一门适合Web开发的理想语言。
有一种偏见认为Javascript是不可靠的,然而事实并非如此。人们对Javascript的偏见来源于DOM,DOM是浏览器厂商提供的用于Javascript与浏览器交互的API,不同浏览器厂商实现的DOM存在差异。然而,Javascript本身是一门定义清晰的语言,可以在不同的浏览器及Node.js中运行。本节,我会先介绍一些Javascript的基础以及Node.js是如何使用Javascript提供了一个性能优异的Web开发平台。
变量
Javascript使用var关键字定义变量。例如下面的代码创建了一个名为foo的变量,并在命令行中输出。(可以通过node variable.js在命令行中执行下面的代码文件。)
代码文件 variable.js
var foo = 123;console.log(foo); // 123
Javascript运行环境(浏览器或者Node.js)通常会定义一些我们可以使用的全局变量,例如console对象,console对象包含一个成员函数log,log函数能够接受任意数量的参数并输出它们。我们接下来会遇到更多的全局对象,你将会发现,Javascript具有一个优秀的编程语言应该包含的大部分特性。
数值
Javascript支持常见的算数操作符(+,-,*,/,%)。例如下列代码:
var foo = 3; var bar = 5; console.log(foo+1); //4 console.log(foo / bar); //0.6 console.log(foo * bar); //15 console.log(foo - bar); //-2 console.log(foo % 2); //取余:1
布尔值
布尔值包括true和false。你可以给变量赋值为true或false,并对其进行布尔操作。例如下列代码:
var foo = true; console.log(foo); //true//常见的布尔操作符号: &&,||, ! console.log(true && true); //true console.log(true && false); /false console.log(true || false); //true console.log(false || false); //false console.log(!true); //false console.log(!false); //true
数组
在Javascript中,我们可以通过[]创建数组。数组对象包含很多有用的函数,例如下列代码所示:
var foo = []; foo.push(1); //添加到数组末尾 console.log(foo); // [1] foo.unshift(2); //添加到数组头部 console.log(foo); // [2, 1]//数组起始位置从0开始 console.log(foo[0]); // 2
对象字面量
Javascript中通常使用对象字面量{}创建对象,例如下列代码所示:
var foo = {};
console.log(foo); // {}
foo.bar = 123;
console.log(foo); // {bar: 123}上面的代码在运行时添加对象属性,我们也可以在创建对象时定义对象属性:
var foo = { bar: 123
};
console.log(foo); // {bar: 123}对象字面量中可以嵌套其它对象字面量,例如下列代码所示:
var foo = {
bar: 123,
bas: {
bas1: 'some string',
bas2: 345
}
};
console.log(foo);当然,对象字面量中也可以包含数组:
var foo = { bar: 123, bas: [1,2,3]
};
console.log(foo);数组当中也可以包含对象字面量:
var foo = { bar: 123, bas: [{ qux: 1
},
{ qux: 2
},
{ qux: 3
}]
};
console.log(foo.bar); //123
console.log(foo.bas[0].qux); // 1
console.log(foo.bas[2].qux); // 2函数
Javascript的函数非常强大,我们接下来将通过一系列的例子来逐渐了解它。
通常情况下的Javascript函数结构如下所示:
function functionName(){ //函数体
}Javascript的所有函数都有返回值。在没有显式声明返回语句的情况下,函数会返回undefined。例如下面代码所示:
function foo(){return 123;}console.log(foo); // 123function bar(){ }console.log(bar()); // undefined立即执行函数
我们在定义函数以后立即执行它,通过括号()包裹并调用函数。如下列代码所示:
(function foo(){
console.log('foo was executed!');
})();出现立即执行函数的原因是为了创建新的变量作用域。if、else、while不会创建新的变量作用域,如下列代码所示:
var foo = 123;if(true){ var foo = 456;
}console.log(foo); // 456在Javascrit中,我们通过函数创建新的变量作用域,例如使用立即执行函数:
var foo = 123;if(true){
(function(){ var foo = 456;
})();
}console.log(foo); // 123在上面的代码中,我们没有给函数命名,这被称为匿名函数。
匿名函数
没有名字的函数被称为匿名函数。在Javascript中,我们可以把函数赋值给变量,如果准备将函数当作变量使用,就不需要给函数命名。下面给出了两种等价的写法:
var foo1 = function nameFunction(){ console.log('foo1');
}
foo1(); // foo1var foo2 = function(){ console.log('foo2');
}
foo2(); // foo2f据说如果一门编程语言能够把函数当作变量来对待,它就是一门优秀的编程语言,Javascript做到了这一点。
高阶函数
由于Javascript允许我们将函数赋值给变量,所以我们可以将函数作为参数传递给其它函数。将函数作为参数的函数被称为高阶函数。setTimeout就是常见的高阶函数。
setTimeout(function(){console.log('2000 milliseconds have passed since this demo started');
}, 2000);如果在Node.js中运行上面的代码,会看到命令窗口2秒钟后输出信息。在上面的代码中,我们传递了一个匿名函数作为setTimeout的第一个参数。我们也可以传递一个普通的函数:
function foo(){ console.log('2000 milliseconds have passed since this demo started');
}
setTimeout(foo, 200);现在,我们已经了解了对象字面量和函数,接下来我们会了解闭包的概念。
闭包
闭包是能够访问其它函数内部变量的函数。如果在函数内部定义另一个函数,内部函数能够访问外部函数的变量,这就是闭包的常见形式。我们会通过一些例子来解释。
在下面的代码中,你可以看到内部函数能够访问外部函数的变量:
function outerFunction(arg){ var variableInOuterFunction = arg; function bar(){console.log(variableInOuterFunction);
}
bar();
}
outerFunction('hello closure!'); // hello closure!令人惊喜的是:内部函数在外部函数返回之后依然可以访问外部函数作用域中的变量。这是因为,变量仍然被绑定于内部函数,不依赖于外部函数。例如:
function outerFunction(arg){ var variableInOuterFunction = arg; return function(){console.log(variableInOuterFunction);
}
}var innerFunction = outerFunction('hello closure!');
innerFunction(); // hello closure!现在,我们已经了解了闭包,接下来,我们会探究一下使Javascript成为一门适合服务器端编程的语言的原因。
Node.js性能
Node.js致力于开发高性能应用程序。接下来的部分,我们会介绍大规模I/O问题,并分别展示传统方式及Node.js是如何解决这个问题的。
大规模I/O问题
大多数Web应用通过硬盘或者网络(例如查询另一台机器的数据库)获取数据,从硬盘或网络获取数据的速度远远慢于CPU的处理周期。当收到一个HTTP请求以后,我们需要从数据库获取数据,请求会一直等待直到获取数据完成。这些创建的连接和还未结束的请求会消耗服务器的资源(内存和CPU)。为了使同一台Web服务器能够处理大规模请求,我们需要解决大规模I/O问题。
每一个请求创建一个进程
传统的Web服务器为每一个请求创建一个新的进程,这是一种对内存和CPU开销都很昂贵的操作。PHP最开始就是采用的这种方法。在等待响应期间,进程仍然会消耗资源,并且进程的创建更慢。所以现代Web应用大多使用线程池的方法。
线程池
现代Web服务器使用线程池来处理每个请求。线程和进程相比,更加轻量级。在创建线程池以后,我们就不再需要为开始或结束进程而付出额外代价。当收到一个请求,我们为它分配一个线程。然而,线程池仍然会浪费一些资源。
单线程模式
我们知道为请求分别创建进程或者线程会导致系统资源浪费。与之相对,Node.js采取了单线程来处理请求。单线程服务器的性能优于线程池服务器的理念并不是Node.js首创,Nginx也是基于这种理念。Nginx是一种单线程服务器,能够处理极大数量的并发请求。
Javascript是单线程的,如果你有一个耗时操作(例如网络请求),就必须使用回调。下面的代码使用setTimeout模拟了一个耗时操作,可以用Node.js执行。
function longRunningOperation(callback){
setTimeout(callback, 3000);
}function UserClicked(){ console.log('starting a long operation');
longRunningOperation(function(){ console.log('ending a long operation');
})
}
UserClicked();让我们模拟一下Web请求:
function longRunningOperation(callback){
setTimeout(callback, 3000);
}function webRequest(request){ console.log('starting a long operation for request:', request.id);
longRunningOperation(function(){console.log('ending a long operation for request:', request.id);
});
}
webRequest({id: 1});
webRequest({id: 2});
//输出
//starting a long operation for request: 1//starting a long operation for request: 2//ending a long operation for request: 1//ending a long operation for request: 2更多的Node.js细节
Node.js的核心是一个event loop。event loop使得任何用户图形界面应用程序可以在任何操作系统中工作。当事件被触发时(例如:用户点击鼠标),操作系统调用程序的某个函数,程序执行函数中的代码。之后,程序准备响应已经在队列中的事件或尚未出现的事件。
线程饥饿
通常,在GUI程序中,当由一个事件调用的函数执行期间,其它事件不会被处理。因此,当你在相关函数中执行耗时操作时,GUI会变得无响应。这种CPU资源的短缺被成为饥饿。
Node.js基于和GUI应用程序相同的event loop原则。因此,它也会面临饥饿的问题。为了帮助更好的理解,我们通过几个例子来说明:
console.time('timer');
setTimeout(function(){ console.timeEnd('timer'); //timer: 1002.615ms
}, 1000)运行这段代码,与我们期望的相同,终端显示的数字在1000ms左右。
接下来我们想写一段耗时更长的代码,例如一个未经优化的计算Fibonacci数列的方法:
console.time('timeit');function fibonacci(n){ if(n<2){return 1;
}else{return fibonacci(n-2) + fibonacci(n-1);
}
}
fibonacci(44);console.timeEnd('timeit'); //我的电脑耗时 11863.331ms,每台电脑会有差异现在我们可以模拟Node.js的线程饥饿。setTimeout用于在指定的时间以后调用函数,如果我们在函数调用以前,执行一个耗时方法,由于耗时方法占用CPU和Javascript线程,setTimeout指定的函数无法被及时调用,只能等待耗时方法运行结束以后被调用。例如下面的代码:
function fibonacci(n){ if(n<2){return 1;
}else{return fibonacci(n-2) + fibonacci(n-1);
}
}console.time('timer');
setTimeout(function(){ console.timeEnd('timer'); // 输出时间会大于 1000ms
}, 1000)
fibonacci(44);所以,如果你面临CPU密集型场景,Node.js并不是最佳选择,但也很难找到其它合适的平台。但是Node.js非常适用于I/O密集型场景。
数据密集型应用
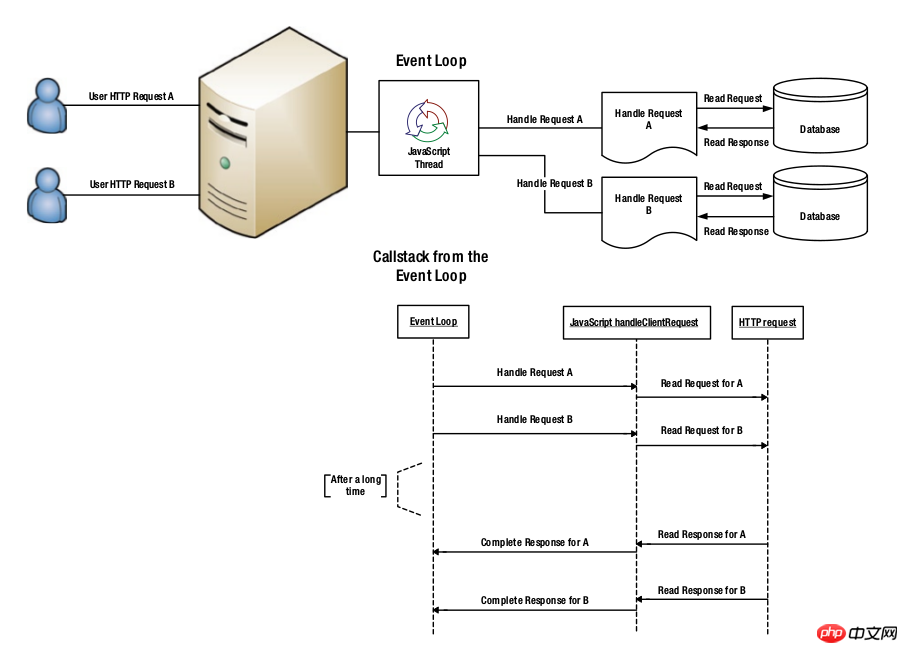
Node.js适用于I/O密集型。单线程机制意味着Node.js作为Web服务器会占用更少的内存,能够支持更多的请求。与执行代码相比,从数据库获取数据需要花费更多的时间。下图展示了传统的线程池模型的服务器是如何处理用户请求的:

Node.js服务器处理请求的方式如下图。因为所有的工作都在单线程内完成,所以消耗更少的内存,同时因为不需要切换线程,所以CPU负载更小。
V8 Javascript引擎
Node.js中的所有Javascript通过V8 Javascript引擎执行。V8产生于谷歌Chrome项目,V8在Chrome中用于运行Javascript。V8不仅速度更快,而且很容易被集成到其它项目。
更多的Javascript
精通Javascript使得Node.js开发者不仅能够写出更加容易维护的项目,而且能够利用到Javascript生态链的优势。
默认值
Javascript变量的默认值是undefined。如下列代码所示:
var foo;console.log(foo); //undefined
变量不存在的属性也会返回undefined
var foo = {bar: 123};
console.log(foo.bar); // 123
console.log(foo.bas); // undefined全等
需要注意Javascript当中 ==与===的区别。==会对变量进行类型转换,===不会。推荐的用法是总是使用===。
console.log(5 == '5'); // true console.log(5 === '5'); // false
null
null是一个特殊的Javascript对象,用于表示空对象。而undefined用于表示变量不存在或未初始化。我们不需要给变量赋值为undefined,因为undefined是变量的默认值。
透露模块模式
透露模块模式的关键在于Javascript对闭包的支持以及能够返回任意对象的能力。如下列代码所示:
function printableMessage(){ var message = 'hello'; function setMessage(newMessage){if(!newMessage) throw new Error('cannot set empty message');
message = newMessage;
} function getMessage(){return message;
} function printMessage(){
console.log(message);
} return {
setMessage: setMessage,
getMessage: getMessage,
printMessage: printMessage
};
}var awesome1 = printableMessage();
awesome1.printMessage(); //hellovar awesome2 = printableMessage();
awesome2.setMessage('hi');
awesome2.printMessage(); // hi
awesome1.printMessage(); //hello理解this
this总是指向调用函数的对象。例如:
var foo = { bar: 123, bas: function(){console.log('inside this.bar is: ', this.bar);
}
}console.log('foo.bar is:', foo.bar); //foo.bar is: 123
foo.bas(); //inside this.bar is: 123由于函数bas被foo对象调用,所以this指向foo。如果是纯粹的函数调用,则this指向全局变量。例如:
function foo(){ console.log('is this called from globals? : ', this === global); //true
}
foo();如果我们在浏览器中执行上面的代码,全局变量global会变为window。
如果函数的调用对象改变,this的指向也会改变:
var foo = { bar: 123
};function bas(){ if(this === global){console.log('called from global');
} if(this === foo){console.log('called from foo');
}
}//指向global
bas(); //called from global//指向foo
foo.bas = bas;
foo.bas(); //called from foo如果通过new操作符调用函数,函数内的this会指向由new创建的对象。
function foo(){ this.foo = 123;
console.log('Is this global? : ', this == global);
}
foo(); // Is this global? : true
console.log(global.foo); //123var newFoo = new foo(); //Is this glocal ? : false
console.log(newFoo.foo); //123通过上面代码,我们可以看到,在通过new调用函数时,函数内的this指向发生改变。
理解原型
Javascript通过new操作符及原型属性可以模仿面向对象的语言。每个Javascript对象都有一个被称为原型的内部链接指向其他对象。
当我们调用一个对象的属性,例如:foo.bar,Javascript会检查foo对象是否存在bar属性,如果不存在,Javascript会检查bar属性是否存在于foo._proto_,以此类推,直到对象不存在_proto_。如果在任何层级发现属性的值,则立即返回,否则,返回undefined。
var foo ={};
foo._proto_.bar = 123;
console.log(foo.bar); //123当我们通过new操作符创建对象时,对象的_proto_会被赋值为函数的prototype属性,例如:
function foo(){};
foo.prototype.bar = 123;var bas = new foo();console.log(bas._proto_ === foo.prototype); //trueconsole.log(bas.bar);函数的所有实例共享相同的prototype
function foo(){};
foo.prototype.bar = 123;
var bas = new foo();
var qux = new foo();
console.log(bas.bar); //123
console.log(qux.bar); //123
foo.prototype.bar = 456;
console.log(bas.bar); //456
console.log(qux.bar); //456只有当属性不存在时,才会访问原型,如果属性存在,则不会访问原型。
function foo(){};
foo.prototype.bar = 123;var bas = new foo();var qux = new foo();
bas.bar = 456;console.log(bas.bar);//456console.log(qux.bar); //123上面的代码表明,如果修改了bas.bar, bas._proto_.bar就不再被访问。
错误处理
Javascript的异常处理机制类似其它语言,通过throw关键字抛出异常,通过catch关键字捕获异常。例如:
try{
console.log('About to throw an error'); throw new Error('Error thrown');
}
catch(e){
console.log('I will only execute if an error is thrown');
console.log('Error caught: ', e.message);
}finally{
console.log('I will execute irrespective of an error thrown');
}总结
本章,我们介绍了一些Node.js及Javascript的重要概念,知道了Node.js适用于开发数据密集型应用程序。下章我们将开始介绍如何使用Node.js开发应用程序。
Atas ialah kandungan terperinci 理解什么是Node.js?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1385
1385
 52
52

 Tutorial cara menggunakan Dewu
Mar 21, 2024 pm 01:40 PM
Tutorial cara menggunakan Dewu
Mar 21, 2024 pm 01:40 PM
Dewu APP pada masa ini merupakan perisian beli-belah jenama yang sangat popular, tetapi kebanyakan pengguna tidak tahu cara menggunakan fungsi dalam APP Dewu Panduan tutorial penggunaan yang paling terperinci Seterusnya, editor membawakan Dewuduo kepada pengguna tutorial. Pengguna yang berminat boleh datang dan lihat! Tutorial cara menggunakan Dewu [2024-03-20] Cara menggunakan pembelian ansuran Dewu [2024-03-20] Cara mendapatkan kupon Dewu [2024-03-20] Cara mencari perkhidmatan pelanggan manual Dewu [2024-03- 20] Cara menyemak kod pikap Dewu【2024-03-20】Di mana hendak mencari pembelian Dewu【2024-03-20】Cara membuka VIP Dewu【2024-03-20】Cara memohon pemulangan atau pertukaran Dewi
 Pada musim panas, anda mesti cuba menembak pelangi
Jul 21, 2024 pm 05:16 PM
Pada musim panas, anda mesti cuba menembak pelangi
Jul 21, 2024 pm 05:16 PM
Selepas hujan pada musim panas, anda sering dapat melihat pemandangan cuaca istimewa yang indah dan ajaib - pelangi. Ini juga merupakan pemandangan jarang yang boleh ditemui dalam fotografi, dan ia sangat fotogenik. Terdapat beberapa syarat untuk pelangi muncul: pertama, terdapat titisan air yang mencukupi di udara, dan kedua, matahari bersinar pada sudut yang lebih rendah. Oleh itu, adalah paling mudah untuk melihat pelangi pada sebelah petang selepas hujan reda. Walau bagaimanapun, pembentukan pelangi sangat dipengaruhi oleh cuaca, cahaya dan keadaan lain, jadi ia biasanya hanya bertahan untuk jangka masa yang singkat, dan masa tontonan dan penangkapan terbaik adalah lebih pendek. Jadi apabila anda menemui pelangi, bagaimanakah anda boleh merakamnya dengan betul dan mengambil gambar dengan kualiti? 1. Cari pelangi Selain keadaan yang dinyatakan di atas, pelangi biasanya muncul mengikut arah cahaya matahari, iaitu jika matahari bersinar dari barat ke timur, pelangi lebih cenderung muncul di timur.
 Tutorial tentang cara mematikan bunyi pembayaran di WeChat
Mar 26, 2024 am 08:30 AM
Tutorial tentang cara mematikan bunyi pembayaran di WeChat
Mar 26, 2024 am 08:30 AM
1. Mula-mula buka WeChat. 2. Klik [+] di penjuru kanan sebelah atas. 3. Klik kod QR untuk mengutip bayaran. 4. Klik tiga titik kecil di penjuru kanan sebelah atas. 5. Klik untuk menutup peringatan suara untuk ketibaan pembayaran.
 Apakah perisian photoshopcs5? -Tutorial penggunaan photoshopcs5
Mar 19, 2024 am 09:04 AM
Apakah perisian photoshopcs5? -Tutorial penggunaan photoshopcs5
Mar 19, 2024 am 09:04 AM
PhotoshopCS ialah singkatan daripada Photoshop Creative Suite Ia adalah perisian yang dihasilkan oleh Adobe Ia digunakan secara meluas dalam reka bentuk grafik dan pemprosesan imej Sebagai seorang pelajar baru yang belajar PS, hari ini biarkan editor menerangkan kepada anda apa itu perisian photoshopcs5. . 1. Apakah perisian photoshop cs5? Adobe Photoshop CS5 Extended sesuai untuk profesional dalam bidang filem, video dan multimedia, pereka grafik dan web yang menggunakan 3D dan animasi, dan profesional dalam bidang kejuruteraan dan saintifik. Paparkan imej 3D dan cantumkannya menjadi imej komposit 2D. Edit video dengan mudah
 Pakar mengajar anda! Cara Yang Betul untuk Memotong Gambar Panjang pada Telefon Mudah Alih Huawei
Mar 22, 2024 pm 12:21 PM
Pakar mengajar anda! Cara Yang Betul untuk Memotong Gambar Panjang pada Telefon Mudah Alih Huawei
Mar 22, 2024 pm 12:21 PM
Dengan perkembangan telefon pintar yang berterusan, fungsi telefon bimbit semakin berkuasa, antaranya fungsi mengambil gambar panjang menjadi salah satu fungsi penting yang digunakan oleh ramai pengguna dalam kehidupan seharian. Tangkapan skrin panjang boleh membantu pengguna menyimpan halaman web yang panjang, rekod perbualan atau gambar pada satu masa untuk memudahkan tontonan dan perkongsian. Di antara banyak jenama telefon bimbit, telefon bimbit Huawei juga merupakan salah satu jenama yang sangat dihormati oleh pengguna, dan fungsinya untuk memotong gambar panjang juga sangat dipuji. Artikel ini akan memperkenalkan anda kepada kaedah yang betul untuk mengambil gambar panjang pada telefon mudah alih Huawei, serta beberapa petua pakar untuk membantu anda menggunakan telefon mudah alih Huawei dengan lebih baik.
 Mari belajar cara memasukkan nombor akar dalam Word bersama-sama
Mar 19, 2024 pm 08:52 PM
Mari belajar cara memasukkan nombor akar dalam Word bersama-sama
Mar 19, 2024 pm 08:52 PM
Semasa mengedit kandungan teks dalam Word, anda kadangkala perlu memasukkan simbol formula. Sesetengah lelaki tidak tahu cara memasukkan nombor akar dalam Word, jadi Xiaomian meminta saya untuk berkongsi dengan rakan saya tutorial tentang cara memasukkan nombor akar dalam Word. Semoga membantu kawan-kawan. Mula-mula, buka perisian Word pada komputer anda, kemudian buka fail yang ingin anda edit, dan gerakkan kursor ke lokasi yang anda perlukan untuk memasukkan tanda akar, rujuk contoh gambar di bawah. 2. Pilih [Sisipkan], dan kemudian pilih [Formula] dalam simbol. Seperti yang ditunjukkan dalam bulatan merah dalam gambar di bawah: 3. Kemudian pilih [Insert New Formula] di bawah. Seperti yang ditunjukkan dalam bulatan merah dalam gambar di bawah: 4. Pilih [Radical], dan kemudian pilih radikal yang sesuai. Seperti yang ditunjukkan dalam bulatan merah dalam gambar di bawah:
 Tutorial PHP: Bagaimana untuk menukar jenis int kepada rentetan
Mar 27, 2024 pm 06:03 PM
Tutorial PHP: Bagaimana untuk menukar jenis int kepada rentetan
Mar 27, 2024 pm 06:03 PM
Tutorial PHP: Cara Menukar Jenis Int kepada Rentetan Dalam PHP, menukar data integer kepada rentetan adalah operasi biasa. Tutorial ini akan memperkenalkan cara menggunakan fungsi terbina dalam PHP untuk menukar jenis int kepada rentetan, sambil memberikan contoh kod khusus. Gunakan cast: Dalam PHP, anda boleh menggunakan cast untuk menukar data integer kepada rentetan. Kaedah ini sangat mudah Anda hanya perlu menambah (rentetan) sebelum data integer untuk menukarnya menjadi rentetan. Di bawah ialah kod contoh mudah
 Tutorial peningkatan sistem Hongmeng telefon bimbit Honor
Mar 23, 2024 pm 12:45 PM
Tutorial peningkatan sistem Hongmeng telefon bimbit Honor
Mar 23, 2024 pm 12:45 PM
Telefon mudah alih Honor sentiasa digemari oleh pengguna kerana prestasi cemerlang dan sistem yang stabil. Baru-baru ini, telefon bimbit Honor telah mengeluarkan sistem Hongmeng baharu, yang telah menarik perhatian dan jangkaan ramai pengguna. Sistem Hongmeng dikenali sebagai sistem yang "menyatukan dunia". Ia mempunyai pengalaman operasi yang lebih lancar dan keselamatan yang lebih tinggi, membolehkan pengguna mengalami dunia telefon pintar yang serba baharu. Ramai pengguna telah menyatakan bahawa mereka ingin menaik taraf sistem telefon bimbit Honor mereka kepada sistem Hongmeng Jadi, mari kita lihat tutorial naik taraf sistem Hongmeng telefon bimbit Honor. pertama, saya
