

离线数据分析流程介绍
3. 离线数据分析流程介绍
注:本环节主要感受数据分析系统的宏观概念及处理流程,初步理解hadoop等框架在其中的应用环节,不用过于关注代码细节
一个应用广泛的数据分析系统:“web日志数据挖掘”
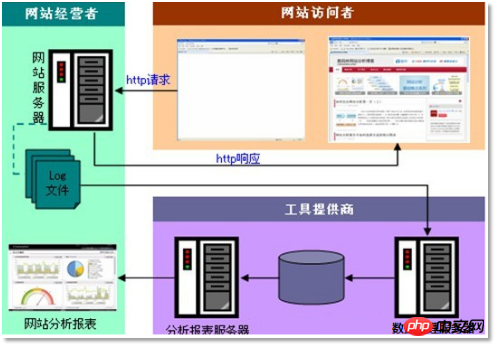
3.1 需求分析
3.1.1 案例名称
“网站或APP点击流日志数据挖掘系统”。
3.1.2 案例需求描述
“Web点击流日志”包含着网站运营很重要的信息,通过日志分析,我们可以知道网站的访问量,哪个网页访问人数最多,哪个网页最有价值,广告转化率、访客的来源信息,访客的终端信息等。
3.1.3 数据来源
本案例的数据主要由用户的点击行为记录
获取方式:在页面预埋一段js程序,为页面上想要监听的标签绑定事件,只要用户点击或移动到标签,即可触发ajax请求到后台servlet程序,用log4j记录下事件信息,从而在web服务器(nginx、tomcat等)上形成不断增长的日志文件。
形如:
58.215.204.118 - - [18/Sep/2013:06:51:35 +0000] "GET /wp-includes/js/jquery/jquery.js?ver=1.10.2 HTTP/1.1" 304 0 "http://blog.fens.me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0" |
3.2 数据处理流程
3.2.1 流程图解析
本案例跟典型的BI系统极其类似,整体流程如下:

但是,由于本案例的前提是处理海量数据,因而,流程中各环节所使用的技术则跟传统BI完全不同,后续课程都会一一讲解:
1) 数据采集:定制开发采集程序,或使用开源框架FLUME
2) 数据预处理:定制开发mapreduce程序运行于hadoop集群
3) 数据仓库技术:基于hadoop之上的Hive
4) 数据导出:基于hadoop的sqoop数据导入导出工具
5) 数据可视化:定制开发web程序或使用kettle等产品
6) 整个过程的流程调度:hadoop生态圈中的oozie工具或其他类似开源产品
3.2.2 项目技术架构图

3.2.3 项目相关截图(感性认识,欣赏即可)
a) Mapreudce程序运行

b) 在Hive中查询数据

c) 将统计结果导入mysql
./sqoop export --connect jdbc:mysql://localhost:3306/weblogdb --username root --password root --table t_display_xx --export-dir /user/hive/warehouse/uv/dt=2014-08-03 |
3.3 项目最终效果
经过完整的数据处理流程后,会周期性输出各类统计指标的报表,在生产实践中,最终需要将这些报表数据以可视化的形式展现出来,本案例采用web程序来实现数据可视化
效果如下所示:

Atas ialah kandungan terperinci 离线数据分析流程介绍. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Baca fail CSV dan lakukan analisis data menggunakan panda
Jan 09, 2024 am 09:26 AM
Baca fail CSV dan lakukan analisis data menggunakan panda
Jan 09, 2024 am 09:26 AM
Pandas ialah alat analisis data yang berkuasa yang boleh membaca dan memproses pelbagai jenis fail data dengan mudah. Antaranya, fail CSV ialah salah satu daripada format fail data yang paling biasa dan biasa digunakan. Artikel ini akan memperkenalkan cara menggunakan Panda untuk membaca fail CSV dan melakukan analisis data serta memberikan contoh kod khusus. 1. Import perpustakaan yang diperlukan Mula-mula, kita perlu mengimport perpustakaan Pandas dan perpustakaan lain yang berkaitan yang mungkin diperlukan, seperti yang ditunjukkan di bawah: importpandasaspd 2. Baca fail CSV menggunakan Pan
 Bagaimana untuk membuka berbilang akaun Toutiao? Apakah proses untuk memohon akaun Toutiao?
Mar 22, 2024 am 11:00 AM
Bagaimana untuk membuka berbilang akaun Toutiao? Apakah proses untuk memohon akaun Toutiao?
Mar 22, 2024 am 11:00 AM
Dengan populariti Internet mudah alih, Toutiao telah menjadi salah satu platform maklumat berita paling popular di negara saya. Ramai pengguna berharap untuk mempunyai berbilang akaun pada platform Toutiao untuk memenuhi keperluan yang berbeza. Jadi, bagaimana untuk membuka berbilang akaun Toutiao? Artikel ini akan memperkenalkan secara terperinci kaedah dan proses permohonan membuka berbilang akaun Toutiao. 1. Bagaimana untuk membuka berbilang akaun Toutiao? Kaedah membuka berbilang akaun Toutiao adalah seperti berikut: Pada platform Toutiao, pengguna boleh mendaftar akaun melalui nombor telefon mudah alih yang berbeza. Setiap nombor telefon mudah alih hanya boleh mendaftar satu akaun Toutiao, yang bermaksud pengguna boleh menggunakan berbilang nombor telefon mudah alih untuk mendaftar berbilang akaun. 2. Pendaftaran e-mel: Gunakan alamat e-mel yang berbeza untuk mendaftar akaun Toutiao. Sama seperti pendaftaran nombor telefon mudah alih, setiap alamat e-mel juga boleh mendaftar akaun Toutiao. 3. Log masuk dengan akaun pihak ketiga
 Memperkenalkan kaedah penalaan bunyi Win 11 terkini
Jan 08, 2024 pm 06:41 PM
Memperkenalkan kaedah penalaan bunyi Win 11 terkini
Jan 08, 2024 pm 06:41 PM
Selepas mengemas kini kepada win11 terkini, ramai pengguna mendapati bahawa bunyi sistem mereka telah berubah sedikit, tetapi mereka tidak tahu bagaimana untuk menyesuaikannya Jadi hari ini laman web ini membawakan anda pengenalan kepada kaedah pelarasan bunyi win11 terkini untuk komputer anda. Ia tidak sukar untuk dikendalikan dan pilihannya pelbagai, datang dan muat turun dan cuba. Cara melaraskan bunyi sistem komputer terkini Windows 11 1. Mula-mula, klik kanan ikon bunyi di sudut kanan bawah desktop dan pilih "Tetapan Main Semula". 2. Kemudian masukkan tetapan dan klik "Speaker" dalam bar main balik. 3. Kemudian klik "Properties" di bahagian bawah sebelah kanan. 4. Klik bar pilihan "Tingkatkan" dalam sifat. 5. Pada masa ini, jika √ di hadapan "Lumpuhkan semua kesan bunyi" ditandakan, batalkannya. 6. Selepas itu, anda boleh memilih kesan bunyi di bawah untuk ditetapkan dan klik
 Adakah sauh tidur Douyin menguntungkan? Apakah prosedur khusus untuk penstriman langsung tidur?
Mar 21, 2024 pm 04:41 PM
Adakah sauh tidur Douyin menguntungkan? Apakah prosedur khusus untuk penstriman langsung tidur?
Mar 21, 2024 pm 04:41 PM
Dalam masyarakat yang serba pantas hari ini, masalah kualiti tidur melanda semakin ramai orang. Untuk meningkatkan kualiti tidur pengguna, sekumpulan sauh tidur khas telah muncul di platform Douyin. Mereka berinteraksi dengan pengguna melalui siaran langsung, berkongsi petua tidur dan menyediakan muzik dan bunyi yang menenangkan untuk membantu penonton tidur dengan tenang. Jadi, adakah sauh tidur ini menguntungkan? Artikel ini akan memberi tumpuan kepada isu ini. 1. Adakah sauh tidur Douyin menguntungkan? Douyin sleep anchor memang boleh mendapat keuntungan tertentu. Pertama, mereka boleh menerima hadiah dan pemindahan melalui fungsi pemberian tip dalam bilik siaran langsung, dan faedah ini bergantung pada bilangan peminat dan kepuasan penonton mereka. Kedua, platform Douyin akan memberikan sauh bahagian tertentu berdasarkan bilangan tontonan, suka, perkongsian dan data lain siaran langsung. Beberapa sauh tidur juga akan
 Panduan Pemula PyCharm: Analisis Komprehensif Fungsi Penggantian
Feb 25, 2024 am 11:15 AM
Panduan Pemula PyCharm: Analisis Komprehensif Fungsi Penggantian
Feb 25, 2024 am 11:15 AM
PyCharm ialah persekitaran pembangunan bersepadu Python yang berkuasa dengan fungsi dan alatan yang kaya yang boleh meningkatkan kecekapan pembangunan dengan ketara. Antaranya, fungsi penggantian merupakan salah satu fungsi yang kerap digunakan dalam proses pembangunan, yang boleh membantu pembangun mengubah suai kod dengan cepat dan meningkatkan kualiti kod. Artikel ini akan memperkenalkan fungsi gantian PyCharm secara terperinci, digabungkan dengan contoh kod khusus, untuk membantu orang baru menguasai dan menggunakan fungsi ini dengan lebih baik. Pengenalan kepada fungsi gantian Fungsi gantian PyCharm boleh membantu pembangun dengan cepat menggantikan teks yang ditentukan dalam kod
 Pengenalan terperinci fungsi Samsung S24ai
Jun 24, 2024 am 11:18 AM
Pengenalan terperinci fungsi Samsung S24ai
Jun 24, 2024 am 11:18 AM
2024 ialah tahun pertama telefon mudah alih AI Semakin banyak telefon mudah alih menyepadukan berbilang fungsi AI Diperkasakan oleh teknologi pintar AI, telefon mudah alih kami boleh digunakan dengan lebih cekap dan mudah. Baru-baru ini, siri Galaxy S24 yang dikeluarkan pada awal tahun ini sekali lagi telah meningkatkan pengalaman AI generatifnya Mari lihat pengenalan fungsi terperinci di bawah. 1. Pemerkasaan AI generatif yang mendalam Siri Samsung Galaxy S24 telah membawa banyak aplikasi pintar melalui pemerkasaan Galaxy AI Fungsi ini disepadukan secara mendalam dengan Samsung One UI6.1, membolehkan pengguna memperoleh pengalaman pintar yang mudah pada bila-bila masa, dengan ketara. meningkatkan prestasi telefon bimbit Kecekapan dan kemudahan penggunaan. Fungsi carian segera yang dipelopori oleh siri Galaxy S24 adalah salah satu sorotan Pengguna hanya perlu menekan dan menahan
 Apa itu Dogecoin
Apr 01, 2024 pm 04:46 PM
Apa itu Dogecoin
Apr 01, 2024 pm 04:46 PM
Dogecoin ialah mata wang kripto yang dicipta berdasarkan meme Internet, tanpa had bekalan tetap, masa transaksi yang cepat, yuran transaksi yang rendah dan komuniti meme yang besar. Penggunaan termasuk transaksi kecil, petua dan sumbangan amal. Walau bagaimanapun, bekalan tanpa had, turun naik pasaran dan statusnya sebagai syiling jenaka juga membawa risiko dan kebimbangan. Apakah Dogecoin? Dogecoin ialah mata wang kripto yang dicipta berdasarkan meme dan jenaka internet. Asal dan Sejarah: Dogecoin dicipta pada Disember 2013 oleh dua jurutera perisian, Billy Markus dan Jackson Palmer. Diilhamkan oleh meme "Doge" yang popular ketika itu, gambar lucu yang memaparkan Shiba Inu dengan bahasa Inggeris yang rosak. Ciri dan Faedah: Bekalan Tanpa Had: Tidak seperti mata wang kripto lain seperti Bitcoin
 Pengenalan kepada kemahiran dan sifat Hua Yishan Heart of the Moon Lu Shu
Mar 23, 2024 pm 05:30 PM
Pengenalan kepada kemahiran dan sifat Hua Yishan Heart of the Moon Lu Shu
Mar 23, 2024 pm 05:30 PM
Di Hua Yishan Heart Moon, Lu Shu ialah seorang selebriti SSR. Dia diletakkan sebagai pendayung belakang tunggal dan mempunyai kadar pukulan kritikal yang sangat mengagumkan. Datang dan lihat pengenalan kepada kemahiran dan sifat Hua Yishan Heart of the Moon Lu Shu. Atribut Selebriti Kemahiran Selebriti 1. Lu Ming Shuzhong Penerangan Kemahiran: Lu Shu dilahirkan di Qiongqihui di Shuzhong Dia telah berlatih seni mempertahankan diri sejak dia masih kecil dan mempunyai kemahiran seni mempertahankan diri yang cemerlang. Menyebabkan kerosakan serangan asas sama dengan 100% kuasa serangan barisan belakang musuh, dan mengurangkan kemarahan sasaran sebanyak 10 mata. Atribut kemahiran: Tahap 2: Kerosakan serangan asas meningkat kepada 105%. Tahap 2: Kerosakan serangan asas dinaikkan kepada 110%, dan kemarahan sasaran dikurangkan sebanyak 15 mata. Tahap 2: Kerosakan serangan asas meningkat kepada 115%. Tahap 2: Kerosakan serangan asas dinaikkan kepada 120%, dan kemarahan sasaran dikurangkan sebanyak 20 mata. Tahap 2: Serangan asas
