

Python爬虫之音频数据实例

一:前言
本次爬取的是喜马拉雅的热门栏目下全部电台的每个频道的信息和频道中的每个音频数据的各种信息,然后把爬取的数据保存到mongodb以备后续使用。这次数据量在70万左右。音频数据包括音频下载地址,频道信息,简介等等,非常多。
昨天进行了人生中第一次面试,对方是一家人工智能大数据公司,我准备在这大二的暑假去实习,他们就要求有爬取过音频数据,所以我就来分析一下喜马拉雅的音频数据爬下来。目前我还在等待三面中,或者是通知最终面试消息。 (因为能得到一定肯定,不管成功与否都很开心)
二:运行环境
IDE:Pycharm 2017
Python3.6
pymongo 3.4.0
requests 2.14.2
lxml 3.7.2
BeautifulSoup 4.5.3
三:实例分析
1.首先进入这次爬取的主页面 ,可以看到每页12个频道,每个频道下面有很多的音频,有的频道中还有很多分页。抓取计划:循环84个页面,对每个页面解析后抓取每个频道的名称,图片链接,频道链接保存到mongodb。
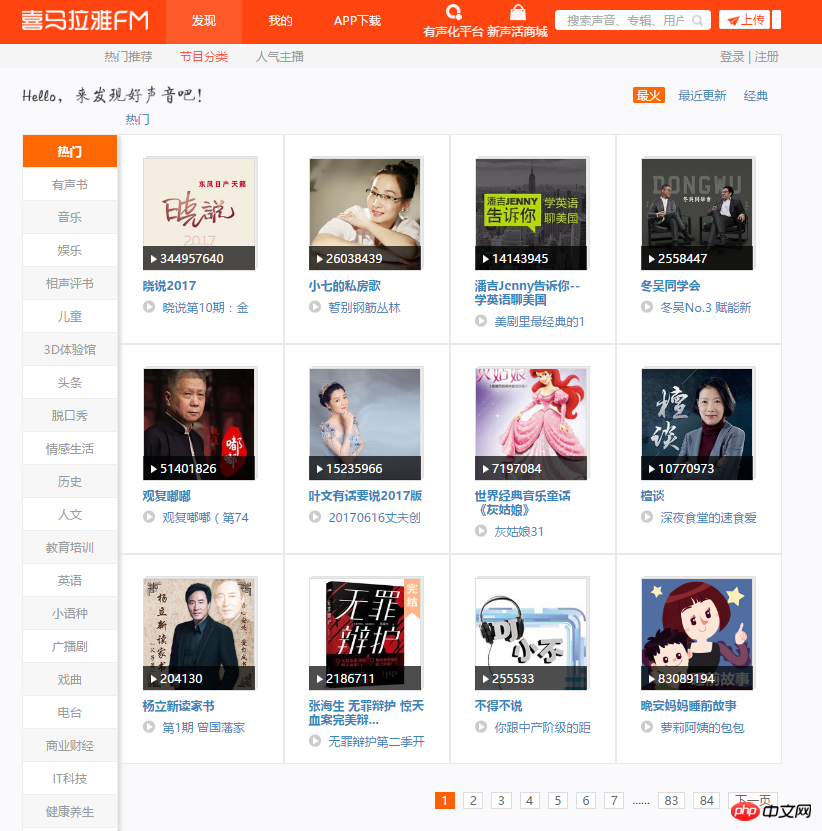
2.打开开发者模式,分析页面,很快就可以得到想要的数据的位置。下面的代码就实现了抓取全部热门频道的信息,就可以保存到mongodb中。
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]for start_url in start_urls:html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')for item in soup.find_all(class_="albumfaceOutter"):content = {'href': item.a['href'],'title': item.img['alt'],'img_url': item.img['src']
}
print(content)
3.下面就是开始获取每个频道中的全部音频数据了,前面通过解析页面获取到了美国频道的链接。比如我们进入 这个链接后分析页面结构。可以看出每个音频都有特定的ID,这个ID可以在一个div中的属性中获取。使用split()和int()来转换为单独的ID。
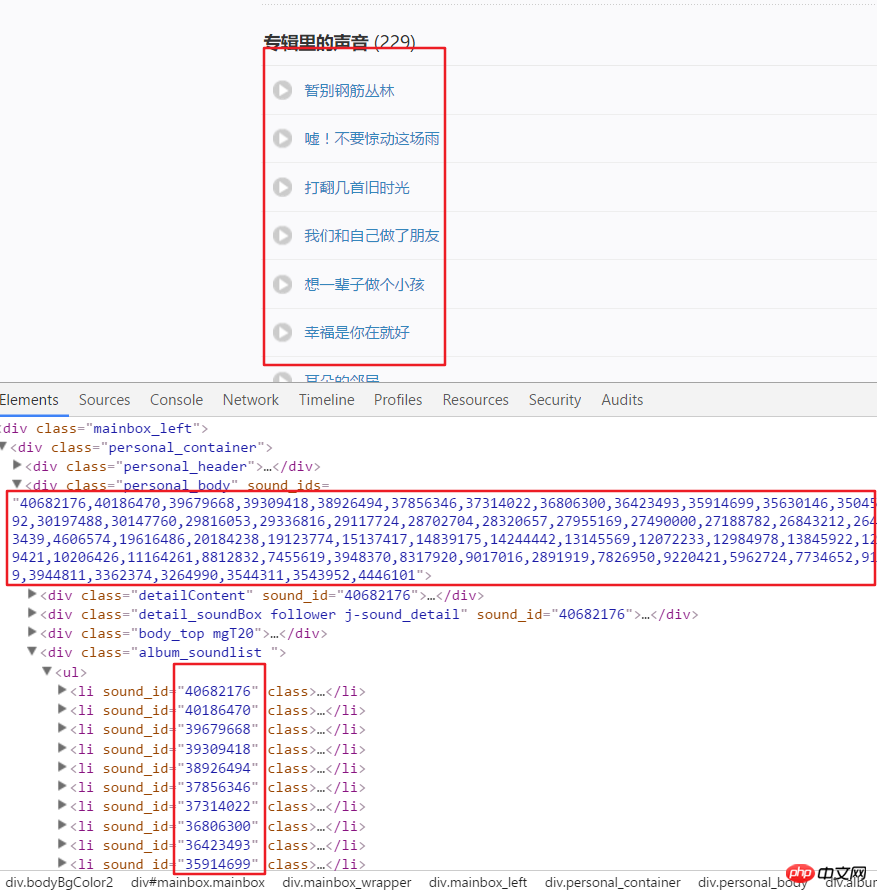
4.接着点击一个音频链接,进入开发者模式后刷新页面然后点击XHR,再点击一个json链接可以看到这个就包括这个音频的全部详细信息。
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)html = requests.get(murl, headers=headers1).text
dic = json.loads(html)
5.上面只是对一个频道的主页面解析全部音频信息,但是实际上频道的音频链接是有很多分页的。
html = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')if len(ifanother):num = ifanother[0]
print('本频道资源存在' + num + '个页面')for n in range(1, int(num)):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)# 之后就接解析音频页函数就行,后面有完整代码说明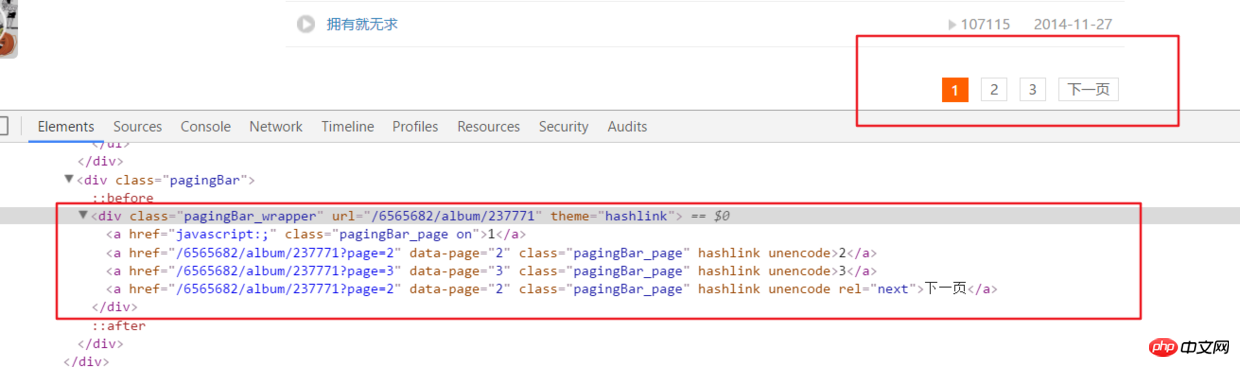
6.全部代码
完整代码地址github.com/rieuse/learnPython
__author__ = '布咯咯_rieuse'import jsonimport randomimport timeimport pymongoimport requestsfrom bs4 import BeautifulSoupfrom lxml import etree
clients = pymongo.MongoClient('localhost')
db = clients["XiMaLaYa"]
col1 = db["album"]
col2 = db["detaile"]
UA_LIST = [] # 很多User-Agent用来随机使用可以防ban,显示不方便不贴出来了
headers1 = {} # 访问网页的headers,这里显示不方便我就不贴出来了
headers2 = {} # 访问网页的headers这里显示不方便我就不贴出来了def get_url():
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]for start_url in start_urls:
html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')for item in soup.find_all(class_="albumfaceOutter"):
content = {'href': item.a['href'],'title': item.img['alt'],'img_url': item.img['src']
}
col1.insert(content)
print('写入一个频道' + item.a['href'])
print(content)
another(item.a['href'])
time.sleep(1)def another(url):
html = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')if len(ifanother):
num = ifanother[0]
print('本频道资源存在' + num + '个页面')for n in range(1, int(num)):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)
get_m4a(url2)
get_m4a(url)def get_m4a(url):
time.sleep(1)
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)
html = requests.get(murl, headers=headers1).text
dic = json.loads(html)
col2.insert(dic)
print(murl + '中的数据已被成功插入mongodb')if __name__ == '__main__':
get_url()7.如果改成异步的形式可以快一点,只需要修改成下面这样就行了。我试了每分钟要比普通的多获取近100条数据。这个源代码也在github中。
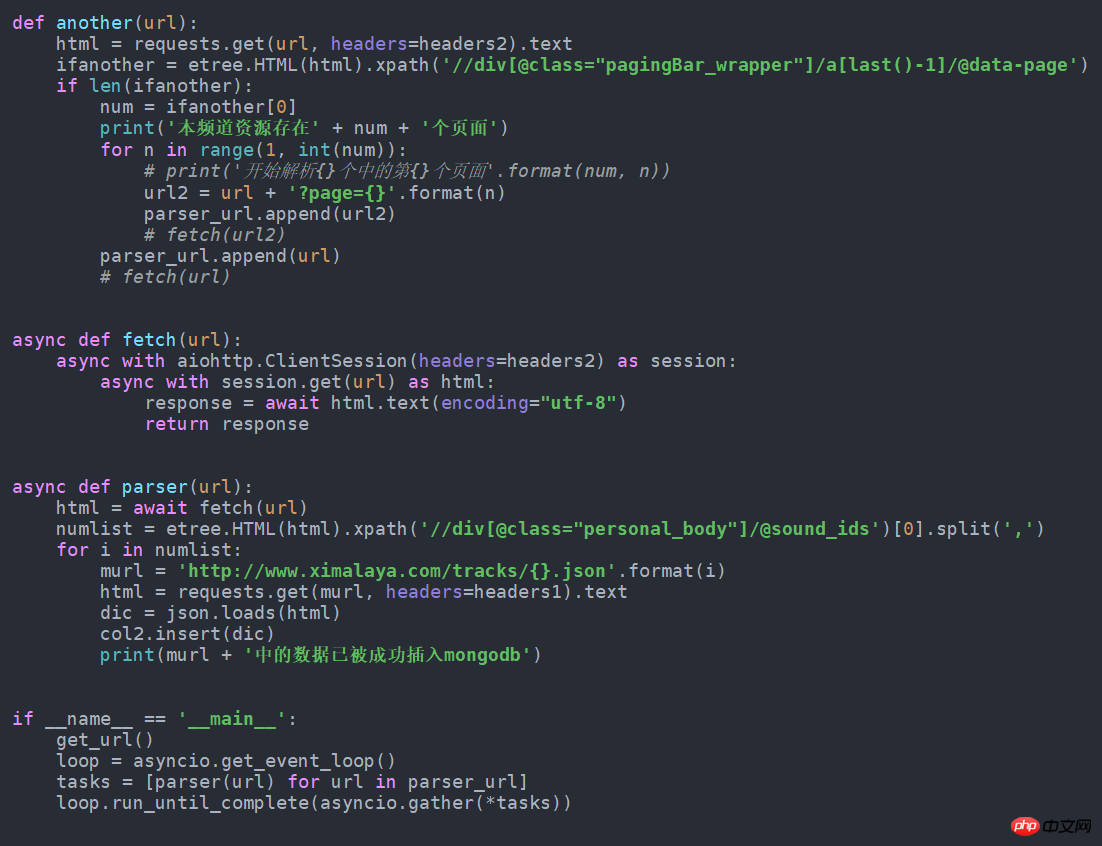
Atas ialah kandungan terperinci Python爬虫之音频数据实例. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1389
1389
 52
52

 Boleh kod vs dijalankan di Windows 8
Apr 15, 2025 pm 07:24 PM
Boleh kod vs dijalankan di Windows 8
Apr 15, 2025 pm 07:24 PM
Kod VS boleh dijalankan pada Windows 8, tetapi pengalaman mungkin tidak hebat. Mula -mula pastikan sistem telah dikemas kini ke patch terkini, kemudian muat turun pakej pemasangan kod VS yang sepadan dengan seni bina sistem dan pasangnya seperti yang diminta. Selepas pemasangan, sedar bahawa beberapa sambungan mungkin tidak sesuai dengan Windows 8 dan perlu mencari sambungan alternatif atau menggunakan sistem Windows yang lebih baru dalam mesin maya. Pasang sambungan yang diperlukan untuk memeriksa sama ada ia berfungsi dengan betul. Walaupun kod VS boleh dilaksanakan pada Windows 8, disyorkan untuk menaik taraf ke sistem Windows yang lebih baru untuk pengalaman dan keselamatan pembangunan yang lebih baik.
 Adakah sambungan vscode berniat jahat?
Apr 15, 2025 pm 07:57 PM
Adakah sambungan vscode berniat jahat?
Apr 15, 2025 pm 07:57 PM
Sambungan kod VS menimbulkan risiko yang berniat jahat, seperti menyembunyikan kod jahat, mengeksploitasi kelemahan, dan melancap sebagai sambungan yang sah. Kaedah untuk mengenal pasti sambungan yang berniat jahat termasuk: memeriksa penerbit, membaca komen, memeriksa kod, dan memasang dengan berhati -hati. Langkah -langkah keselamatan juga termasuk: kesedaran keselamatan, tabiat yang baik, kemas kini tetap dan perisian antivirus.
 Memilih antara php dan python: panduan
Apr 18, 2025 am 12:24 AM
Memilih antara php dan python: panduan
Apr 18, 2025 am 12:24 AM
PHP sesuai untuk pembangunan web dan prototaip pesat, dan Python sesuai untuk sains data dan pembelajaran mesin. 1.Php digunakan untuk pembangunan web dinamik, dengan sintaks mudah dan sesuai untuk pembangunan pesat. 2. Python mempunyai sintaks ringkas, sesuai untuk pelbagai bidang, dan mempunyai ekosistem perpustakaan yang kuat.
 Cara menjalankan program di terminal vscode
Apr 15, 2025 pm 06:42 PM
Cara menjalankan program di terminal vscode
Apr 15, 2025 pm 06:42 PM
Dalam kod VS, anda boleh menjalankan program di terminal melalui langkah -langkah berikut: Sediakan kod dan buka terminal bersepadu untuk memastikan bahawa direktori kod selaras dengan direktori kerja terminal. Pilih arahan Run mengikut bahasa pengaturcaraan (seperti python python your_file_name.py) untuk memeriksa sama ada ia berjalan dengan jayanya dan menyelesaikan kesilapan. Gunakan debugger untuk meningkatkan kecekapan debug.
 PHP dan Python: Paradigma yang berbeza dijelaskan
Apr 18, 2025 am 12:26 AM
PHP dan Python: Paradigma yang berbeza dijelaskan
Apr 18, 2025 am 12:26 AM
PHP terutamanya pengaturcaraan prosedur, tetapi juga menyokong pengaturcaraan berorientasikan objek (OOP); Python menyokong pelbagai paradigma, termasuk pengaturcaraan OOP, fungsional dan prosedur. PHP sesuai untuk pembangunan web, dan Python sesuai untuk pelbagai aplikasi seperti analisis data dan pembelajaran mesin.
 Bolehkah kod studio visual digunakan dalam python
Apr 15, 2025 pm 08:18 PM
Bolehkah kod studio visual digunakan dalam python
Apr 15, 2025 pm 08:18 PM
Kod VS boleh digunakan untuk menulis Python dan menyediakan banyak ciri yang menjadikannya alat yang ideal untuk membangunkan aplikasi python. Ia membolehkan pengguna untuk: memasang sambungan python untuk mendapatkan fungsi seperti penyempurnaan kod, penonjolan sintaks, dan debugging. Gunakan debugger untuk mengesan kod langkah demi langkah, cari dan selesaikan kesilapan. Mengintegrasikan Git untuk Kawalan Versi. Gunakan alat pemformatan kod untuk mengekalkan konsistensi kod. Gunakan alat linting untuk melihat masalah yang berpotensi lebih awal.
 Boleh vscode digunakan untuk mac
Apr 15, 2025 pm 07:36 PM
Boleh vscode digunakan untuk mac
Apr 15, 2025 pm 07:36 PM
VS Kod boleh didapati di Mac. Ia mempunyai sambungan yang kuat, integrasi git, terminal dan debugger, dan juga menawarkan banyak pilihan persediaan. Walau bagaimanapun, untuk projek yang sangat besar atau pembangunan yang sangat profesional, kod VS mungkin mempunyai prestasi atau batasan fungsi.
 Boleh vscode menjalankan ipynb
Apr 15, 2025 pm 07:30 PM
Boleh vscode menjalankan ipynb
Apr 15, 2025 pm 07:30 PM
Kunci untuk menjalankan buku nota Jupyter dalam kod VS adalah untuk memastikan bahawa persekitaran Python dikonfigurasi dengan betul, memahami bahawa perintah pelaksanaan kod adalah konsisten dengan susunan sel, dan mengetahui fail besar atau perpustakaan luaran yang boleh menjejaskan prestasi. Fungsi penyempurnaan dan debug yang disediakan oleh kod VS dapat meningkatkan kecekapan pengekodan dan mengurangkan kesilapan.
