

编码的秘密(python版)
编码(python版)
最近在学习python的过程中,被不同的编码搞得有点晕,于是看了前人的留下的文档,加上自己的理解,准备写下来,分享给正在为编码苦苦了挣扎的你。
编码的概念
编码就是将信息从一种格式转换成另一种格式,计算机只认识二进制,简单的理解,将我们眼睛看到的文字转换为计算机能够识别的二进制格式视为编码,而二进制以某种编码格式转换为我们能看的文字的过程可以看成是解码。既然计算机只能认识二进制0,1,那么我们用的字母、数字和文字等是怎样和他们对应的呢?那就请继续看吧!
python中查看默认的编码规范是:
import sysprint(sys.getdefaultencoding())#运行结果:utf-8
ASCⅡ码
我们都知道计算机是米国发明的,起初的时候也只有米国那些国家使用,而他们的语言仅仅只有26个字母组成,再加上一些符号,所以在一开始的时候,用的编码规则就是ASCⅡ码。ASCⅡ,中文名叫美国信息交换标准代码,因为名叫American Standard Code for Information Interchange,下面我们来看看ASCⅡ表:

ASCⅡ码用一个字节,也就是8位二进制组来标识一个字符,比如00100001就代表字符!,第一版的ASCⅡ没有用到最高的一个bit,所以取值范围为0-127,只能表示128字符。为了满足西欧等国家的字符要求,于是用上了最高位的bit,能表示的字符也从128增加到了256个。

在python中使用函数ord(),可以字符转换为对应数值,使用函数chr可以将数值转换为对应字符:
>>> ord("a") #将字符转换为数值97>>> ord("A")65>>> chr(65)'A'>>> chr(97) #将数值转换为字符'a'>>>
GB2312和GBK
当计算机漂洋过海来到了中国,ASCⅡ已经不能满足我大天朝的需求了,常用的汉字大致都有2k-3k。所以中国国家标准总局在1980发布了《信息交换用汉字编码字符集》,也就是GB2313标准。GB2312一共收录了7445个字符(6763个汉字和682个其他符号),包括拉丁字母、希腊字母和日文平假名等,基本上满足了国人的需求。
在GB2312中每个汉字使用两个字节来表示,分为高字节和低字节,汉字区高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768,其中有5个空位是D7FA-D7FE,规定第一个字节大于127的就代表这是一个汉字的开始(这一个字节和下一个字节就代表一个汉字),每个字节的最高位都位1。
但是对于人名、古汉语等方面出现的罕用字,GB2312不能处理,后来就出现了GBK。GBK向下兼容GB2312,其编码范围从8140到FEFE(不包括xx7F),共23940个码位,共收录了21003个汉字,这还是很厉害的了。现在我们使用的计算机默认的就是GBK编码。

Unicode和UTF-8
我们国家搞出了GBK,其他的国家也搞出了各种各样的编码,比如小日本的SJIJ,宝岛台湾的BIG5,国际组织一看,这不行啊,每个地方都各自搞各自的,那么在不同的国家之间就会出现不兼容,我用GBK编码格式写的软件,弄到你编码格式为SJIJ的计算机就不能执行了。所以就出现了Unicode,也称万国码。unicode是用2个字节来表示一个字符的,65536类个字符,这足以覆盖世界上所有的文字。
这样虽好,但是美国人民就不开心了,我一个字母,比如'a'就需要占用一个字节,现在需要占用两个字节,这样就大大的浪费了内存和硬盘的空间,所有后来就出现了UTF-32,UTF-16和UTF-8,前两个这里就不在敖述了,现在并不常用,我们这看看这个UTF-8,UTF-8是一种可变长的编码格式,存储英文字母只需要一个字节,存储汉字需要3个字节,但超大字符集中的更大多数汉字要占4个字节。我们在内存里面的数据是unicode,在传输数据和保存数据的时候使用UTF-8已节省空间和带宽。
Python2的编码
在python2中默认的编码是ASCII,python2的字符串类型有两种:str和Unicode,这两个只是字符串类型的名字,我们主要看它们在内存里面的内存地址:
= = u repr(name2) #输出结果
'\xe5\xbd\xac\xe5\xbd\xac' #字节数据
u'\u5f6c\u5f6c' #Unicode数据

在python2中,str类型字符串类型在内存中存储的是bytes数据,Unicode类型字符串在内存中存储的是unicode数据。那两种数据之间是什么关系了?这里就涉及到了解码(encode)和编码(decode)了。
= name2 = u = name.decode(= name2.encode(<type ><type >
由上运行结果可知,unicode转换为bytes数据的过程是编码。从bytes数据转换为unicode数据的过程是解码。我们再来看一下:
#coding=utf8name = '彬彬'name3 = name.decode('big5')print name3#运行结果敶砍蓮我们可以看到得到一堆乱文,name存在内存里的时候是以UTF编码成的bytes数据,而我们这里decode('big5')使用big5来解码,虽然成功了,但是输出结果却不是我们想要的结果。
当我们把第一行coding改为big5的时候就不会出现乱文了,
#coding=big5name = '彬彬'name3 = name.decode('big5')print name3#运行结果彬彬所以我们用什么规则编码的就要用什么区解码!

注意:我们在终端显示出来的明文,就是你用户所看到的,其实都是已经转换成unicode到内存里面,而bytes数据一般都是计算机识别的。
Python3的编码
在Python3中也定义了2种类型的字符串类型,str和bytes,str类型存储unicode数据,bytes类型存储bytes数据。
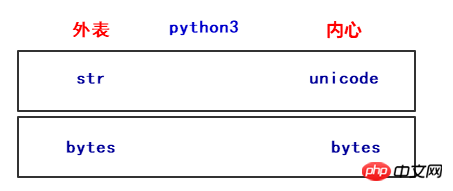
name = "彬彬"name2 = b"hello"print(type(name))print(type(name.encode('utf8')))print(type(name.encode('gbk')))print(type(name2))print(type(name2.decode('utf8')))#运行结果<class 'str'>
<class 'bytes'>
<class 'bytes'>
<class 'bytes'>
<class 'str'>如上运行结果,bytes转换为unicode为解码,uicode转为bytes数据类型为编码。

由上图所示,在不同的编码之间转换的时候,我们都要经过unicode这个中转站,没办法,虽然unicode老大哥强大呢,当我们想把utf-8编码的数据转换为gbk的,我们就需要把utf-8的数据先解码成unicode,再由unicode编码成gbk。
在py2和py3中有个重要的区分就是,py2会自动把bytes数据解码成unicode,而py3就不会自动把bytes解码成unicode了。所以说py3更清晰的区分了bytes数据和unicode。
#py2中print(u"liu" + "bin")#运行结果liubin
( + b, line 2, <module>( + bbytes
print("liu" + (b"bin").decode('utf8'))
#运行结果liubin
一个.py文件的"一生"
那我们创建.py文件,到执行.py文件,这里面的编码和解码是怎么来的呢?
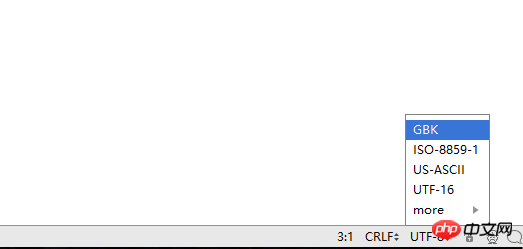
1.当我们创建一个.py文件的时候,会有一个默认的编码格式(这里以pycharm为例),在右下角,默认是UTF-8,当然你也可以选择其他的编码:
2.当我们在.py文件里面写入代码的时候,会以unicode的编码格式保存在内存中;
print("你好,世界!")
3.当我们保存的时候,会将Unicode数据编码成utf-8格式的数据,然后保存在硬盘里面;
4.当我们执行文件的时候,pycharm会调用python的解释器来读取文件,在py2中,默认会以ASCII将代码解码成unicode数据,但是ASCII码并不认识中文,所以就会出现报错。
File "E:/py/�ַ�����.py", line 2SyntaxError: Non-ASCII character '\xe4' in file E:/py/�ַ�����.py on line 2, but no encoding declared; see for details
所以,在py2中,我们需要加上:
#coding=utf8print("你好,世界!")#运行结果你好,世界!但是在py3中就不存在这个问题了,只要编码的时候适用的是UTF-8,python3默认的编码规范就是UTF-8,它会用UTF-8来将UTF-8的bytes数据解码成unicode,然后在计算机终端显示!
Atas ialah kandungan terperinci 编码的秘密(python版). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Apakah sebab mengapa PS terus menunjukkan pemuatan?
Apr 06, 2025 pm 06:39 PM
Apakah sebab mengapa PS terus menunjukkan pemuatan?
Apr 06, 2025 pm 06:39 PM
PS "Memuatkan" Masalah disebabkan oleh akses sumber atau masalah pemprosesan: Kelajuan bacaan cakera keras adalah perlahan atau buruk: Gunakan CrystaldiskInfo untuk memeriksa kesihatan cakera keras dan menggantikan cakera keras yang bermasalah. Memori yang tidak mencukupi: Meningkatkan memori untuk memenuhi keperluan PS untuk imej resolusi tinggi dan pemprosesan lapisan kompleks. Pemandu kad grafik sudah lapuk atau rosak: Kemas kini pemandu untuk mengoptimumkan komunikasi antara PS dan kad grafik. Laluan fail terlalu panjang atau nama fail mempunyai aksara khas: Gunakan laluan pendek dan elakkan aksara khas. Masalah PS sendiri: Pasang semula atau membaiki pemasang PS.
 Bagaimana menyelesaikan masalah pemuatan apabila PS dimulakan?
Apr 06, 2025 pm 06:36 PM
Bagaimana menyelesaikan masalah pemuatan apabila PS dimulakan?
Apr 06, 2025 pm 06:36 PM
PS yang tersangkut pada "memuatkan" apabila boot boleh disebabkan oleh pelbagai sebab: Lumpuhkan plugin yang korup atau bercanggah. Padam atau namakan semula fail konfigurasi yang rosak. Tutup program yang tidak perlu atau menaik taraf memori untuk mengelakkan memori yang tidak mencukupi. Naik taraf ke pemacu keadaan pepejal untuk mempercepatkan bacaan cakera keras. Pasang semula PS untuk membaiki fail sistem rasuah atau isu pakej pemasangan. Lihat maklumat ralat semasa proses permulaan analisis log ralat.
 Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Artikel ini memperkenalkan operasi pangkalan data MySQL. Pertama, anda perlu memasang klien MySQL, seperti MySqlworkbench atau Command Line Client. 1. Gunakan perintah MySQL-Uroot-P untuk menyambung ke pelayan dan log masuk dengan kata laluan akaun root; 2. Gunakan CreateTatabase untuk membuat pangkalan data, dan gunakan Pilih pangkalan data; 3. Gunakan createtable untuk membuat jadual, menentukan medan dan jenis data; 4. Gunakan InsertInto untuk memasukkan data, data pertanyaan, kemas kini data dengan kemas kini, dan padam data dengan padam. Hanya dengan menguasai langkah -langkah ini, belajar menangani masalah biasa dan mengoptimumkan prestasi pangkalan data anda boleh menggunakan MySQL dengan cekap.
 Bagaimanakah Feathering PS mengawal kelembutan peralihan?
Apr 06, 2025 pm 07:33 PM
Bagaimanakah Feathering PS mengawal kelembutan peralihan?
Apr 06, 2025 pm 07:33 PM
Kunci kawalan bulu adalah memahami sifatnya secara beransur -ansur. PS sendiri tidak menyediakan pilihan untuk mengawal lengkung kecerunan secara langsung, tetapi anda boleh melaraskan radius dan kelembutan kecerunan dengan pelbagai bulu, topeng yang sepadan, dan pilihan halus untuk mencapai kesan peralihan semula jadi.
 Adakah Mysql perlu membayar
Apr 08, 2025 pm 05:36 PM
Adakah Mysql perlu membayar
Apr 08, 2025 pm 05:36 PM
MySQL mempunyai versi komuniti percuma dan versi perusahaan berbayar. Versi komuniti boleh digunakan dan diubahsuai secara percuma, tetapi sokongannya terhad dan sesuai untuk aplikasi dengan keperluan kestabilan yang rendah dan keupayaan teknikal yang kuat. Edisi Enterprise menyediakan sokongan komersil yang komprehensif untuk aplikasi yang memerlukan pangkalan data yang stabil, boleh dipercayai, berprestasi tinggi dan bersedia membayar sokongan. Faktor yang dipertimbangkan apabila memilih versi termasuk kritikal aplikasi, belanjawan, dan kemahiran teknikal. Tidak ada pilihan yang sempurna, hanya pilihan yang paling sesuai, dan anda perlu memilih dengan teliti mengikut keadaan tertentu.
 Apa yang perlu saya lakukan jika kad PS berada di antara muka pemuatan?
Apr 06, 2025 pm 06:54 PM
Apa yang perlu saya lakukan jika kad PS berada di antara muka pemuatan?
Apr 06, 2025 pm 06:54 PM
Antara muka pemuatan kad PS mungkin disebabkan oleh perisian itu sendiri (fail rasuah atau konflik plug-in), persekitaran sistem (pemacu yang wajar atau fail sistem rasuah), atau perkakasan (rasuah cakera keras atau kegagalan tongkat memori). Pertama semak sama ada sumber komputer mencukupi, tutup program latar belakang dan lepaskan memori dan sumber CPU. Betulkan pemasangan PS atau periksa isu keserasian untuk pemalam. Mengemas kini atau menewaskan versi PS. Semak pemacu kad grafik dan kemas kini, dan jalankan semak fail sistem. Jika anda menyelesaikan masalah di atas, anda boleh mencuba pengesanan cakera keras dan ujian memori.
 Bagaimana cara menyediakan bulu ps?
Apr 06, 2025 pm 07:36 PM
Bagaimana cara menyediakan bulu ps?
Apr 06, 2025 pm 07:36 PM
PS Feathering adalah kesan kabur tepi imej, yang dicapai dengan purata piksel berwajaran di kawasan tepi. Menetapkan jejari bulu dapat mengawal tahap kabur, dan semakin besar nilai, semakin kaburnya. Pelarasan fleksibel radius dapat mengoptimumkan kesan mengikut imej dan keperluan. Sebagai contoh, menggunakan jejari yang lebih kecil untuk mengekalkan butiran apabila memproses foto watak, dan menggunakan radius yang lebih besar untuk mewujudkan perasaan kabur ketika memproses karya seni. Walau bagaimanapun, perlu diperhatikan bahawa terlalu besar jejari boleh dengan mudah kehilangan butiran kelebihan, dan terlalu kecil kesannya tidak akan jelas. Kesan bulu dipengaruhi oleh resolusi imej dan perlu diselaraskan mengikut pemahaman imej dan kesan genggaman.
 Cara mengoptimumkan prestasi pangkalan data selepas pemasangan MySQL
Apr 08, 2025 am 11:36 AM
Cara mengoptimumkan prestasi pangkalan data selepas pemasangan MySQL
Apr 08, 2025 am 11:36 AM
Pengoptimuman prestasi MySQL perlu bermula dari tiga aspek: konfigurasi pemasangan, pengindeksan dan pengoptimuman pertanyaan, pemantauan dan penalaan. 1. Selepas pemasangan, anda perlu menyesuaikan fail my.cnf mengikut konfigurasi pelayan, seperti parameter innodb_buffer_pool_size, dan tutup query_cache_size; 2. Buat indeks yang sesuai untuk mengelakkan indeks yang berlebihan, dan mengoptimumkan pernyataan pertanyaan, seperti menggunakan perintah menjelaskan untuk menganalisis pelan pelaksanaan; 3. Gunakan alat pemantauan MySQL sendiri (ShowProcessList, ShowStatus) untuk memantau kesihatan pangkalan data, dan kerap membuat semula dan mengatur pangkalan data. Hanya dengan terus mengoptimumkan langkah -langkah ini, prestasi pangkalan data MySQL diperbaiki.
