

网络爬虫如何做才算好?

网络爬虫的实质,其实是从网络上“偷”数据。通过网络爬虫,我们可以采集到所需要的资源,但是同样,使用不当也可能会引发一些比较严重的问题。
因此,在使用网络爬虫时,我们需要做到“盗亦有道”。
网络爬虫主要分为以下三类:
1. 小规模,数据量小,爬取速度不敏感;对于这类网络爬虫我们可以使用Requests库来实现,主要用于爬取网页;
2. 中规模,数据规模较大,爬取速度敏感;对于这类网络爬虫我们可以使用Scrapy库来实现,主要用于爬取网站或系列网站;
3. 大规模,搜索引擎,爬取速度关键;此时需要定制开发,主要用于爬取全网,一般是建立全网搜索引擎,如百度、Google搜索等。
在这三种中,我们最为常见的是第一种,大多数均是小规模的爬取网页的爬虫。
对于网络爬虫,也有很多反对声音。因为网络爬虫会不停的向服务器发出请求,影响服务器性能,对服务器产生骚扰行为,并加大了网站维护者的工作量。
除了对服务器的骚扰外,网络爬虫也有可能引发法律风险。因为服务器上的数据有产权归属,如果将该数据用于牟利的话,将会带来法律风险。
此外,网络爬虫也可能会造成用户的隐私泄露。
简而言之,网路爬虫的风险主要归于以下三点:
对服务器的性能骚扰
内容层面的法律风险
个人隐私的泄露
因此,网络爬虫的使用需要有一定的规则。
在实际情况中,一些较大的网站都对网络爬虫进行了相关限制,整个互联网上也将网络爬虫视为可规范的功能来看待。
对于一般的服务器来讲,我们可以通过2种方式来限制网络爬虫:
1. 如果网站的所有者有一定的技术能力,可以通过来源审查来限制网络爬虫。
来源审查,一般通过判断User-Agent来进行限制,本篇文章着重介绍第2种。
2. 通过Robots协议来告诉网络爬虫需要遵守的规则,哪些可以爬取,哪些是不允许的,并要求所有的爬虫遵守该协议。
第2种是以公告的形式告知,Robots协议是建议但非约束性,网络爬虫可以不遵守,但可能会存在法律风险。通过这两种方法,互联网上形成了对网络爬虫的道德和技术上的有效限制。
那么,我们在编写网络爬虫时,就需要去尊重网站的维护人员对网站资源的管理。
互联网上,部分网站没有Robots协议,所有数据都可以爬取;不过,绝大多数的主流网站都支持Robots协议,有做相关限制,下面就具体介绍下Robots协议的基本语法。
Robots协议(Robots Exclusion Standard,网络爬虫排除标准):
作用:网站告知网络爬虫哪些页面可以爬取,哪些不行。
形式:在网站根目录下的robots.txt文件。
Robots协议的基本语法:*代表所有,/代表根目录。
比如,PMCAFF的Robots协议:
User-agent: *
Disallow: /article/edit
Disallow: /discuss/write
Disallow: /discuss/edit
第1行中User-agent:*,是指所有的网络爬虫都需要遵守如下协议;
第2行中Disallow: /article/edit,是指所有的网络爬虫都不允许访问article/edit下的内容,其他同理。
如果观察京东的Robots协议,,可以看到下面有User-agent: EtaoSpider,Disallow: /,其中EtaoSpider是恶意爬虫,不允许其爬取京东的任何资源。
User-agent: *
Disallow: /?*
Disallow: /pop/*.html
Disallow: /pinpai/*.html?*
User-agent: EtaoSpider
Disallow: /
User-agent: HuihuiSpider
Disallow: /
User-agent: GwdangSpider
Disallow: /
User-agent: WochachaSpider
Disallow: /
有了Robots协议后,可以对网站的内容做个规范,告诉所有的网络爬虫哪些可以爬取,哪些不允许。
需要特别注意的是,Robots协议都是存在根目录下的,不同的根目录可能Robots协议是不一样的,在爬取时需要多加留意。
Atas ialah kandungan terperinci 网络爬虫如何做才算好?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

![Modul pengembangan WLAN telah berhenti [fix]](https://img.php.cn/upload/article/000/465/014/170832352052603.gif?x-oss-process=image/resize,m_fill,h_207,w_330) Modul pengembangan WLAN telah berhenti [fix]
Feb 19, 2024 pm 02:18 PM
Modul pengembangan WLAN telah berhenti [fix]
Feb 19, 2024 pm 02:18 PM
Jika terdapat masalah dengan modul pengembangan WLAN pada komputer Windows anda, ia mungkin menyebabkan anda terputus sambungan daripada Internet. Keadaan ini sering mengecewakan, tetapi mujurlah, artikel ini menyediakan beberapa cadangan mudah yang boleh membantu anda menyelesaikan masalah ini dan membolehkan sambungan wayarles anda berfungsi dengan baik semula. Betulkan Modul Kebolehlanjutan WLAN Telah Berhenti Jika Modul Kebolehlanjutan WLAN telah berhenti berfungsi pada komputer Windows anda, ikuti cadangan ini untuk membetulkannya: Jalankan Penyelesai Masalah Rangkaian dan Internet untuk melumpuhkan dan mendayakan semula sambungan rangkaian wayarles Mulakan semula Perkhidmatan Konfigurasi Auto WLAN Ubah Suai Pilihan Kuasa Ubah suai Tetapan Kuasa Lanjutan Pasang Semula Pemacu Penyesuai Rangkaian Jalankan Beberapa Perintah Rangkaian Sekarang, mari kita lihat secara terperinci
 Bagaimana untuk menyelesaikan ralat pelayan DNS win11
Jan 10, 2024 pm 09:02 PM
Bagaimana untuk menyelesaikan ralat pelayan DNS win11
Jan 10, 2024 pm 09:02 PM
Kita perlu menggunakan DNS yang betul apabila menyambung ke Internet untuk mengakses Internet. Dengan cara yang sama, jika kita menggunakan tetapan dns yang salah, ia akan menyebabkan ralat pelayan dns Pada masa ini, kita boleh cuba menyelesaikan masalah dengan memilih untuk mendapatkan dns secara automatik dalam tetapan rangkaian penyelesaian. Cara menyelesaikan ralat pelayan dns rangkaian win11 Kaedah 1: Tetapkan semula DNS 1. Pertama, klik Mula dalam bar tugas untuk masuk, cari dan klik butang ikon "Tetapan". 2. Kemudian klik arahan pilihan "Rangkaian & Internet" di lajur kiri. 3. Kemudian cari pilihan "Ethernet" di sebelah kanan dan klik untuk masuk. 4. Selepas itu, klik "Edit" dalam tugasan pelayan DNS, dan akhirnya tetapkan DNS kepada "Automatik (D
 Betulkan muat turun 'Ralat Rangkaian Gagal' pada Chrome, Google Drive dan Photos!
Oct 27, 2023 pm 11:13 PM
Betulkan muat turun 'Ralat Rangkaian Gagal' pada Chrome, Google Drive dan Photos!
Oct 27, 2023 pm 11:13 PM
Apakah isu "Muat turun ralat rangkaian gagal"? Sebelum kita menyelidiki penyelesaiannya, mari kita fahami dahulu maksud isu "Muat Turun Ralat Rangkaian Gagal". Ralat ini biasanya berlaku apabila sambungan rangkaian terganggu semasa memuat turun. Ia boleh berlaku atas pelbagai sebab seperti sambungan internet yang lemah, kesesakan rangkaian atau isu pelayan. Apabila ralat ini berlaku, muat turun akan berhenti dan mesej ralat akan dipaparkan. Bagaimana untuk membetulkan muat turun yang gagal dengan ralat rangkaian? Menghadapi "Ralat Rangkaian Muat Turun Gagal" boleh menjadi penghalang semasa mengakses atau memuat turun fail yang diperlukan. Sama ada anda menggunakan penyemak imbas seperti Chrome atau platform seperti Google Drive dan Google Photos, ralat ini akan muncul yang menyebabkan kesulitan. Di bawah ialah perkara untuk membantu anda menavigasi dan menyelesaikan isu ini
 Betulkan: WD My Cloud tidak muncul pada rangkaian dalam Windows 11
Oct 02, 2023 pm 11:21 PM
Betulkan: WD My Cloud tidak muncul pada rangkaian dalam Windows 11
Oct 02, 2023 pm 11:21 PM
Jika WDMyCloud tidak muncul pada rangkaian dalam Windows 11, ini boleh menjadi masalah besar, terutamanya jika anda menyimpan sandaran atau fail penting lain di dalamnya. Ini boleh menjadi masalah besar bagi pengguna yang kerap perlu mengakses storan rangkaian, jadi dalam panduan hari ini, kami akan menunjukkan kepada anda cara untuk menyelesaikan masalah ini secara kekal. Mengapa WDMyCloud tidak muncul pada rangkaian Windows 11? Peranti MyCloud, penyesuai rangkaian atau sambungan Internet anda tidak dikonfigurasikan dengan betul. Fungsi SMB tidak dipasang pada komputer. Gangguan sementara dalam Winsock kadangkala boleh menyebabkan masalah ini. Apakah yang perlu saya lakukan jika awan saya tidak muncul pada rangkaian? Sebelum kami mula membetulkan masalah, anda boleh melakukan beberapa semakan awal:
 Apakah yang perlu saya lakukan jika bumi dipaparkan di sudut kanan bawah Windows 10 apabila saya tidak boleh mengakses Internet Pelbagai penyelesaian kepada masalah yang Bumi tidak dapat mengakses Internet dalam Win10?
Feb 29, 2024 am 09:52 AM
Apakah yang perlu saya lakukan jika bumi dipaparkan di sudut kanan bawah Windows 10 apabila saya tidak boleh mengakses Internet Pelbagai penyelesaian kepada masalah yang Bumi tidak dapat mengakses Internet dalam Win10?
Feb 29, 2024 am 09:52 AM
Artikel ini akan memperkenalkan penyelesaian kepada masalah bahawa simbol glob dipaparkan pada rangkaian sistem Win10 tetapi tidak boleh mengakses Internet. Artikel itu akan menyediakan langkah terperinci untuk membantu pembaca menyelesaikan masalah rangkaian Win10 yang menunjukkan bahawa bumi tidak boleh mengakses Internet. Kaedah 1: Mulakan semula secara langsung, periksa sama ada kabel rangkaian tidak dipasang dengan betul dan sama ada jalur lebar tertunggak. Jika tiada perkara penting yang sedang dilakukan pada komputer, anda boleh memulakan semula komputer secara langsung Kebanyakan masalah kecil boleh diselesaikan dengan cepat dengan memulakan semula komputer. Jika ditentukan jalur lebar tidak tertunggak dan rangkaiannya normal, itu adalah perkara lain. Kaedah 2: 1. Tekan kekunci [Win], atau klik [Start Menu] di sudut kiri bawah Dalam item menu yang terbuka, klik ikon gear di atas butang kuasa Ini ialah [Settings].
 Semak sambungan rangkaian: lol tidak boleh menyambung ke pelayan
Feb 19, 2024 pm 12:10 PM
Semak sambungan rangkaian: lol tidak boleh menyambung ke pelayan
Feb 19, 2024 pm 12:10 PM
LOL tidak boleh menyambung ke pelayan, sila semak rangkaian Dalam beberapa tahun kebelakangan ini, permainan dalam talian telah menjadi aktiviti hiburan harian bagi ramai orang. Antaranya, League of Legends (LOL) ialah permainan dalam talian berbilang pemain yang sangat popular, menarik penyertaan dan minat ratusan juta pemain. Walau bagaimanapun, kadangkala apabila kami bermain LOL, kami akan menemui mesej ralat "Tidak dapat menyambung ke pelayan, sila semak rangkaian", yang sudah pasti membawa beberapa masalah kepada pemain. Seterusnya, kita akan membincangkan punca dan penyelesaian kesilapan ini. Pertama sekali, masalah yang LOL tidak dapat menyambung ke pelayan mungkin
 Apakah yang berlaku apabila rangkaian tidak dapat menyambung ke wifi?
Apr 03, 2024 pm 12:11 PM
Apakah yang berlaku apabila rangkaian tidak dapat menyambung ke wifi?
Apr 03, 2024 pm 12:11 PM
1. Semak kata laluan wifi: Pastikan kata laluan wifi yang anda masukkan adalah betul dan perhatikan sensitiviti huruf besar. 2. Sahkan sama ada wifi berfungsi dengan betul: Semak sama ada penghala wifi berjalan seperti biasa Anda boleh menyambungkan peranti lain ke penghala yang sama untuk menentukan sama ada masalah terletak pada peranti. 3. Mulakan semula peranti dan penghala: Kadangkala, terdapat kerosakan atau masalah rangkaian dengan peranti atau penghala, dan memulakan semula peranti dan penghala boleh menyelesaikan masalah. 4. Semak tetapan peranti: Pastikan fungsi wayarles peranti dihidupkan dan fungsi wifi tidak dinyahdayakan.
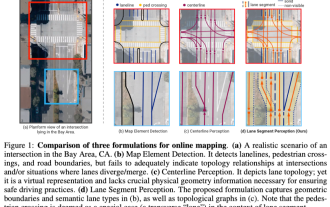 ICLR'24 idea baharu tanpa gambar! LaneSegNet: pembelajaran peta berdasarkan kesedaran pembahagian lorong
Jan 19, 2024 am 11:12 AM
ICLR'24 idea baharu tanpa gambar! LaneSegNet: pembelajaran peta berdasarkan kesedaran pembahagian lorong
Jan 19, 2024 am 11:12 AM
Ditulis di atas & Pemahaman peribadi penulis tentang peta sebagai maklumat utama untuk aplikasi hiliran sistem pemanduan autonomi biasanya diwakili oleh lorong atau garisan tengah. Walau bagaimanapun, kesusasteraan pembelajaran peta sedia ada tertumpu terutamanya pada pengesanan hubungan topologi berasaskan geometri bagi lorong atau penderiaan garis tengah. Kedua-dua kaedah mengabaikan hubungan yang wujud antara garisan lorong dan garisan tengah, iaitu garisan lorong mengikat garisan tengah. Walaupun hanya meramalkan dua jenis lorong dalam satu model adalah saling eksklusif dalam objektif pembelajaran, kertas kerja ini mencadangkan lanesegment sebagai perwakilan baharu yang menggabungkan maklumat geometri dan topologi dengan lancar, sekali gus mencadangkan LaneSegNet. Ini adalah rangkaian pemetaan hujung ke hujung pertama yang menjana lorong untuk mendapatkan gambaran lengkap struktur jalan. LaneSegNet mempunyai dua peringkat
