

python学习之抓取博客园新闻

前言
说到python,对它有点耳闻的人,第一反应可能都是爬虫~
这两天看了点python的皮毛知识,忍不住想写一个简单的爬虫练练手,JUST DO IT
准备工作
要制作数据抓取的爬虫,对请求的源页面结构需要有特定分析,只有分析正确了,才能更好更快的爬到我们想要的内容。
浏览器访问570973/,右键“查看源代码”,初步只想取一些简单的数据(文章标题、作者、发布时间等),在HTML源码中找到相关数据的部分:
1)标题(url):
2)作者:投递人 itwriter
3)发布时间:发布于 2017-06-06 14:53
4)当前新闻ID :
当然了,要想“顺藤摸瓜”,“上一篇”和“下一篇”链接的结构非常重要;但发现一个问题,页面中的这两个标签,它的链接和文本内容,是通过js渲染的,这可如何是好?尝试寻找资料(python执行js之类的),可对于python菜鸟来说,可能有点超前了,打算另找方案。
虽然这两个链接是通过js渲染的,但是理论上来说,js之所以能渲染该内容,应该也是通过发起请求,得到响应后执行的渲染吧;那么是否可以通过监视网页加载过程看看有什么有用信息呢?在此要为chrome/firefox这些浏览器点个赞了,开发者工具/网络,可以清清楚楚的看到所有资源的请求和响应情况。

它们的请求地址分别为:
1)上一篇新闻ID:
2)下一篇新闻ID:
响应的内容为JSON
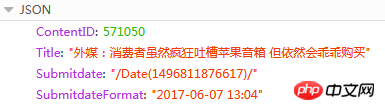
此处ContentID就是我们需要的,可以根据这个值,知道当前新闻的上一篇或下一篇新闻URL,因为新闻发布的页面地址是有固定格式的:{{ContentID}}/ (红色内容就是可替换的ID)
工具
1)python 3.6(安装的时候同时安装pip,并且加入环境变量)
2)PyCharm 2017.1.3
3)第三方python库(安装:cmd -> pip install name)
a)pyperclip : 用于读写剪贴板
b)requests : 基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库。它比 urllib 更加方便,可以节约我们大量的工作
c)beautifulsoup4 : Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据
源码
代码个人觉得都是很基础易懂的(毕竟菜鸟也写不出高深的代码),有疑问或是建议的,请不吝赐教
#! python3
# coding = utf-8
# get_cnblogs_news.py
# 根据博客园内的任意一篇新闻,获取所有新闻(标题、发布时间、发布人)
#
# 这是标题格式 :<div id="news_title"><a href="//news.cnblogs.com/n/570973/">SpaceX重复使用的“龙”飞船成功与国际空间站对接</a></div>
# 这是发布人格式 :<span class="news_poster">投递人 <a href="//home.cnblogs.com/u/34358/">itwriter</a></span>
# 这是发布时间格式 :<span class="time">发布于 2017-06-06 14:53</span>
# 当前新闻ID :<input type="hidden" value="570981" id="lbContentID">
# html中获取不到上一篇和下一篇的直接链接,因为它是使用ajax请求后期渲染的
# 需要另外请求地址,获取结果,JSON
# 上一篇
# 下一篇
# 响应内容
# ContentID : 570971
# Title : "Mac支持外部GPU VR开发套件售599美元"
# Submitdate : "/Date(1425445514)"
# SubmitdateFormat : "2017-06-06 14:47"
import sys, pyperclip
import requests, bs4
import json
# 解析并打印(标题、作者、发布时间、当前ID)
# soup : 响应的HTML内容经过bs4转化的对象
def get_info(soup):
dict_info = {'curr_id': '', 'author': '', 'time': '', 'title': '', 'url': ''}
titles = soup.select('div#news_title > a')
if len(titles) > 0:
dict_info['title'] = titles[0].getText()
dict_info['url'] = titles[0].get('href')
authors = soup.select('span.news_poster > a')
if len(authors) > 0:
dict_info['author'] = authors[0].getText()
times = soup.select('span.time')
if len(times) > 0:
dict_info['time'] = times[0].getText()
content_ids = soup.select('input#lbContentID')
if len(content_ids) > 0:
dict_info['curr_id'] = content_ids[0].get('value')
# 写文件
with open('D:/cnblognews.csv', 'a') as f:
text = '%s,%s,%s,%s\n' % (dict_info['curr_id'], (dict_info['author'] + dict_info['time']), dict_info['url'], dict_info['title'])
print(text)
f.write(text)
return dict_info['curr_id']
# 获取前一篇文章信息
# curr_id : 新闻ID
# loop_count : 向上多少条,如果为0,则无限向上,直至结束
def get_prev_info(curr_id, loop_count = 0):
private_loop_count = 0
try:
while loop_count == 0 or private_loop_count < loop_count:
res_prev = requests.get('https://news.cnblogs.com/NewsAjax/GetPreNewsById?contentId=' + curr_id)
res_prev.raise_for_status()
res_prev_dict = json.loads(res_prev.text)
prev_id = res_prev_dict['ContentID']
res_prev = requests.get('https://news.cnblogs.com/n/%s/' % prev_id)
res_prev.raise_for_status()
soup_prev = bs4.BeautifulSoup(res_prev.text, 'html.parser')
curr_id = get_info(soup_prev)
private_loop_count += 1
except:
pass
# 获取下一篇文章信息
# curr_id : 新闻ID
# loop_count : 向下多少条,如果为0,则无限向下,直至结束
def get_next_info(curr_id, loop_count = 0):
private_loop_count = 0
try:
while loop_count == 0 or private_loop_count < loop_count:
res_next = requests.get('https://news.cnblogs.com/NewsAjax/GetNextNewsById?contentId=' + curr_id)
res_next.raise_for_status()
res_next_dict = json.loads(res_next.text)
next_id = res_next_dict['ContentID']
res_next = requests.get('https://news.cnblogs.com/n/%s/' % next_id)
res_next.raise_for_status()
soup_next = bs4.BeautifulSoup(res_next.text, 'html.parser')
curr_id = get_info(soup_next)
private_loop_count += 1
except:
pass
# 参数从优先从命令行获取,如果无,则从剪切板获取
# url是博客园新闻版块下,任何一篇新闻
if len(sys.argv) > 1:
url = sys.argv[1]
else:
url = pyperclip.paste()
# 没有获取到有地址,则抛出异常
if not url:
raise ValueError
# 开始从源地址中获取新闻内容
res = requests.get(url)
res.raise_for_status()
if not res.text:
raise ValueError
#解析Html
soup = bs4.BeautifulSoup(res.text, 'html.parser')
curr_id = get_info(soup)
print('backward...')
get_prev_info(curr_id)
print('forward...')
get_next_info(curr_id)
print('done')
运行
将以上源代码保存至D:/get_cnblogs_news.py ,windows平台下打开命令行工具cmd:
输入命令:py.exe D:/get_cnblogs_news.py 回车
解析:py.exe就不用解释了,第二个参数为python脚本文件,第三个参数为需要爬的源页面(代码里有另一种考虑,如果你将这个url拷贝在系统剪贴板的时候,可以直接运行:py.exe D:/get_cnblogs_news.py
命令行输出界面(print)
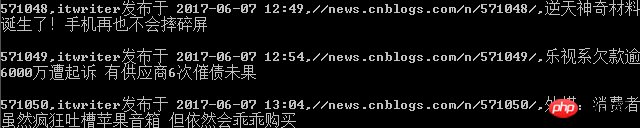
保存到csv文件的内容

推荐菜鸟python学习书箱或资料:
1)廖雪峰的Python教程,很基础易懂:
2)Python编程快速上手 让繁琐工作自动化.pdf
文章仅是给自己学习python的日记,如有误导请批评指正(不喜勿喷),如对您有帮助,荣幸之至。
Atas ialah kandungan terperinci python学习之抓取博客园新闻. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1379
1379
 52
52

 PHP dan Python: Contoh dan perbandingan kod
Apr 15, 2025 am 12:07 AM
PHP dan Python: Contoh dan perbandingan kod
Apr 15, 2025 am 12:07 AM
PHP dan Python mempunyai kelebihan dan kekurangan mereka sendiri, dan pilihannya bergantung kepada keperluan projek dan keutamaan peribadi. 1.PHP sesuai untuk pembangunan pesat dan penyelenggaraan aplikasi web berskala besar. 2. Python menguasai bidang sains data dan pembelajaran mesin.
 Cara Melatih Model Pytorch di CentOs
Apr 14, 2025 pm 03:03 PM
Cara Melatih Model Pytorch di CentOs
Apr 14, 2025 pm 03:03 PM
Latihan yang cekap model pytorch pada sistem CentOS memerlukan langkah -langkah, dan artikel ini akan memberikan panduan terperinci. 1. Penyediaan Persekitaran: Pemasangan Python dan Ketergantungan: Sistem CentOS biasanya mempamerkan python, tetapi versi mungkin lebih tua. Adalah disyorkan untuk menggunakan YUM atau DNF untuk memasang Python 3 dan menaik taraf PIP: Sudoyumupdatepython3 (atau SudodnfupdatePython3), pip3install-upgradepip. CUDA dan CUDNN (Percepatan GPU): Jika anda menggunakan Nvidiagpu, anda perlu memasang Cudatool
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
 Python vs JavaScript: Komuniti, Perpustakaan, dan Sumber
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: Komuniti, Perpustakaan, dan Sumber
Apr 15, 2025 am 12:16 AM
Python dan JavaScript mempunyai kelebihan dan kekurangan mereka sendiri dari segi komuniti, perpustakaan dan sumber. 1) Komuniti Python mesra dan sesuai untuk pemula, tetapi sumber pembangunan depan tidak kaya dengan JavaScript. 2) Python berkuasa dalam bidang sains data dan perpustakaan pembelajaran mesin, sementara JavaScript lebih baik dalam perpustakaan pembangunan dan kerangka pembangunan depan. 3) Kedua -duanya mempunyai sumber pembelajaran yang kaya, tetapi Python sesuai untuk memulakan dengan dokumen rasmi, sementara JavaScript lebih baik dengan MDNWebDocs. Pilihan harus berdasarkan keperluan projek dan kepentingan peribadi.
 Cara Memilih Versi PyTorch Di Bawah Centos
Apr 14, 2025 pm 02:51 PM
Cara Memilih Versi PyTorch Di Bawah Centos
Apr 14, 2025 pm 02:51 PM
Apabila memilih versi pytorch di bawah CentOS, faktor utama berikut perlu dipertimbangkan: 1. Keserasian versi CUDA Sokongan GPU: Jika anda mempunyai NVIDIA GPU dan ingin menggunakan pecutan GPU, anda perlu memilih pytorch yang menyokong versi CUDA yang sepadan. Anda boleh melihat versi CUDA yang disokong dengan menjalankan arahan NVIDIA-SMI. Versi CPU: Jika anda tidak mempunyai GPU atau tidak mahu menggunakan GPU, anda boleh memilih versi CPU PyTorch. 2. Pytorch versi python
 Keserasian Centos Miniopen
Apr 14, 2025 pm 05:45 PM
Keserasian Centos Miniopen
Apr 14, 2025 pm 05:45 PM
Penyimpanan Objek Minio: Penyebaran berprestasi tinggi di bawah CentOS System Minio adalah prestasi tinggi, sistem penyimpanan objek yang diedarkan yang dibangunkan berdasarkan bahasa Go, serasi dengan Amazons3. Ia menyokong pelbagai bahasa pelanggan, termasuk Java, Python, JavaScript, dan GO. Artikel ini akan memperkenalkan pemasangan dan keserasian minio pada sistem CentOS. Keserasian versi CentOS Minio telah disahkan pada pelbagai versi CentOS, termasuk tetapi tidak terhad kepada: CentOS7.9: Menyediakan panduan pemasangan lengkap yang meliputi konfigurasi kluster, penyediaan persekitaran, tetapan fail konfigurasi, pembahagian cakera, dan mini
 Cara Memasang Nginx di CentOs
Apr 14, 2025 pm 08:06 PM
Cara Memasang Nginx di CentOs
Apr 14, 2025 pm 08:06 PM
CentOS Memasang Nginx memerlukan mengikuti langkah-langkah berikut: memasang kebergantungan seperti alat pembangunan, pcre-devel, dan openssl-devel. Muat turun Pakej Kod Sumber Nginx, unzip dan menyusun dan memasangnya, dan tentukan laluan pemasangan sebagai/usr/local/nginx. Buat pengguna Nginx dan kumpulan pengguna dan tetapkan kebenaran. Ubah suai fail konfigurasi nginx.conf, dan konfigurasikan port pendengaran dan nama domain/alamat IP. Mulakan perkhidmatan Nginx. Kesalahan biasa perlu diberi perhatian, seperti isu ketergantungan, konflik pelabuhan, dan kesilapan fail konfigurasi. Pengoptimuman prestasi perlu diselaraskan mengikut keadaan tertentu, seperti menghidupkan cache dan menyesuaikan bilangan proses pekerja.
