

爬虫问题解决的相关问题
继续上一篇文章的内容,上一篇文章中已经将url管理器和下载器写好了。接下来就是url解析器,总的来说这个模块是几个模块中比较难的。因为通过下载器下载完页面之后,我们虽然得到了页面,但是这并不是我们想要的结果。而且由于页面的代码很多,我们很难去里面找到自己想要的数据。所幸,我们下载的是html页面,它是一种由多个多层次的节点组成的树型结构的文本文件。所以,相较于txt文件,我们更加容易定位到我们要找的数据块。现在我们要做的就是去原页面去分析一下,我们想要的数据到底在哪。
打开百度百科pyton词条的页面,然后按F12调出开发者工具。通过使用工具,我们就能定位到页面的内容:
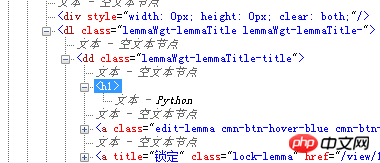

这样我们就找到了我们想要的信息处在哪个标签里了。
1 import bs4 2 import re 3 from urllib.parse import urljoin 4 class HtmlParser(object): 5 """docstring for HtmlParser""" 6 def _get_new_urls(self, url, soup): 7 new_urls = set() 8 links = soup.find_all('a', href = re.compile(r'/item/.')) 9 for link in links:10 new_url = re.sub(r'(/item/)(.*)', r'\1%s' % link.getText(), link['href'])11 new_full_url = urljoin(url, new_url)12 new_urls.add(new_full_url)13 return new_urls14 15 def _get_new_data(self, url, soup):16 res_data = {}17 #url18 res_data['url'] = url19 #<dd class="lemmaWgt-lemmaTitle-title">20 title_node = soup.find('dd', class_ = "lemmaWgt-lemmaTitle-title").find('h1')21 res_data['title'] = title_node.getText()22 #<div class="lemma-summary" label-module="lemmaSummary">23 summary_node = soup.find('div', class_ = "lemma-summary")24 res_data['summary'] = summary_node.getText()25 return res_data26 27 def parse(self, url, html_cont):28 if url is None or html_cont is None:29 return 30 soup = bs4.BeautifulSoup(html_cont, 'lxml')31 new_urls = self._get_new_urls(url, soup)32 new_data = self._get_new_data(url, soup)33 return new_urls, new_data解析器只有一个外部方法就是parse方法,
a.首先它会接受url, html_cont两个参数,然后进行判断页面内容是否为空
b.调用bs4模块的方法来解析网页内容,'lxml'为文档解析器,默认的为html.parser,bs官方推荐我们用lxml,那就听它的吧,谁让人家是官方呢。
c.接下来就是调用两个内部函数来获取新的url列表和数据
d.最后将url列表和数据返回
这里有一些注意点
1.bs的方法调用还有一个参数,from_encoding 这个和我在下载器那里的重复了,所以我就取消了,两个的功能是一样的。
2.获取url列表的内部方法,需要用到正则表达式,这里我也是摸着石头过河,不是很会,中间也调试过许多次。
3.数据是放在字典中的,这样可以通过key来增改删除数据。
最好,就直接数据输出了,这个比较简单,直接上代码。
1 class HtmlOutputer(object): 2 """docstring for HtmlOutputer""" 3 def __init__(self): 4 self.datas = [] 5 def collect_data(self, new_data): 6 if new_data is None: 7 return 8 self.datas.append(new_data) 9 def output_html(self):10 fout = open('output1.html', 'w', encoding = 'utf-8')11 fout.write('<html>')12 fout.write('<head><meta charset="utf-8"></head>')13 fout.write('<body>')14 fout.write('<table>')15 for data in self.datas:16 fout.write('<tr>')17 fout.write('<td>%s</td>' % data['url'])18 fout.write('<td>%s</td>' % data['title'])19 fout.write('<td>%s</td>' % data['summary'])20 fout.write('</tr>')21 fout.write('</table>')22 fout.write('</body>')23 fout.write('</html>')24 fout.close()这里也有两个注意点
1.fout = open('output1.html', 'w', encoding = 'utf-8'),这里的encoding参数一定要加,不然会报错,在windows平台,它默认是使用gbk编码来写文件的。
2.fout.write('
'),这里的meta标签也要加上,因为要告诉浏览器使用什么编码来渲染页面,这里我一开始没加弄了很久,我打开页面的内容,发现里面是中文的,结果浏览器展示的就是乱码。总的来说,因为整个页面采集过程结果好几个模块,所以编码问题要非常小心,不然少不留神就会出错。
最后总结,这段程序还有许多方面可以深入探讨:
1.页面的数据量过小,我尝试了10000个页面的爬取。一旦数据量剧增之后,就会带来一下问题,第一是待爬取url和已爬取url就不能放在set集合中了,要么放到radi缓存服务器里,要么放到mysql数据库中
2.第二,数据也是同样的,字典也满足不了了,需要专门的数据库来存放
3.第三量上去之后,对爬取效率就有要求了,那么多线程就要加进来
4.第四,一旦布置好任务,单台服务器的压力会过大,而且一旦宕机,风险很大,所以分布式的高可用架构也要跟上来
5.一方面是页面的内容过于简单,都是静态页面,不涉及登录,也不涉及ajax动态获取
6.这只是数据采集,后续还有建模,分析…………
综上所述,路还远的很呢,加油!
Atas ialah kandungan terperinci 爬虫问题解决的相关问题. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1374
1374
 52
52

 Apakah sebab mengapa PS terus menunjukkan pemuatan?
Apr 06, 2025 pm 06:39 PM
Apakah sebab mengapa PS terus menunjukkan pemuatan?
Apr 06, 2025 pm 06:39 PM
PS "Memuatkan" Masalah disebabkan oleh akses sumber atau masalah pemprosesan: Kelajuan bacaan cakera keras adalah perlahan atau buruk: Gunakan CrystaldiskInfo untuk memeriksa kesihatan cakera keras dan menggantikan cakera keras yang bermasalah. Memori yang tidak mencukupi: Meningkatkan memori untuk memenuhi keperluan PS untuk imej resolusi tinggi dan pemprosesan lapisan kompleks. Pemandu kad grafik sudah lapuk atau rosak: Kemas kini pemandu untuk mengoptimumkan komunikasi antara PS dan kad grafik. Laluan fail terlalu panjang atau nama fail mempunyai aksara khas: Gunakan laluan pendek dan elakkan aksara khas. Masalah PS sendiri: Pasang semula atau membaiki pemasang PS.
 Bagaimana untuk mempercepatkan kelajuan pemuatan PS?
Apr 06, 2025 pm 06:27 PM
Bagaimana untuk mempercepatkan kelajuan pemuatan PS?
Apr 06, 2025 pm 06:27 PM
Menyelesaikan masalah Permulaan Photoshop Perlahan memerlukan pendekatan berbilang arah, termasuk: menaik taraf perkakasan (memori, pemacu keadaan pepejal, CPU); menyahpasang pemalam yang sudah lapuk atau tidak serasi; membersihkan sampah sistem dan program latar belakang yang berlebihan dengan kerap; menutup program yang tidak relevan dengan berhati -hati; Mengelakkan membuka sejumlah besar fail semasa permulaan.
 Bagaimana menyelesaikan masalah pemuatan apabila PS dimulakan?
Apr 06, 2025 pm 06:36 PM
Bagaimana menyelesaikan masalah pemuatan apabila PS dimulakan?
Apr 06, 2025 pm 06:36 PM
PS yang tersangkut pada "memuatkan" apabila boot boleh disebabkan oleh pelbagai sebab: Lumpuhkan plugin yang korup atau bercanggah. Padam atau namakan semula fail konfigurasi yang rosak. Tutup program yang tidak perlu atau menaik taraf memori untuk mengelakkan memori yang tidak mencukupi. Naik taraf ke pemacu keadaan pepejal untuk mempercepatkan bacaan cakera keras. Pasang semula PS untuk membaiki fail sistem rasuah atau isu pakej pemasangan. Lihat maklumat ralat semasa proses permulaan analisis log ralat.
 Fungsi Halaman Seterusnya HTML
Apr 06, 2025 am 11:45 AM
Fungsi Halaman Seterusnya HTML
Apr 06, 2025 am 11:45 AM
<p> Fungsi halaman seterusnya boleh dibuat melalui HTML. Langkah -langkah termasuk: Membuat elemen kontena, memisahkan kandungan, menambah pautan navigasi, menyembunyikan halaman lain, dan menambah skrip. Ciri ini membolehkan pengguna melayari kandungan segmen, memaparkan hanya satu halaman pada satu masa, dan sesuai untuk memaparkan sejumlah besar data atau kandungan. </p>
 Adakah pemuatan ps lambat berkaitan dengan konfigurasi komputer?
Apr 06, 2025 pm 06:24 PM
Adakah pemuatan ps lambat berkaitan dengan konfigurasi komputer?
Apr 06, 2025 pm 06:24 PM
Alasan pemuatan PS yang perlahan adalah kesan gabungan perkakasan (CPU, memori, cakera keras, kad grafik) dan perisian (sistem, program latar belakang). Penyelesaian termasuk: Menaik taraf perkakasan (terutamanya menggantikan pemacu keadaan pepejal), mengoptimumkan perisian (membersihkan sampah sistem, mengemas kini pemacu, menyemak tetapan PS), dan memproses fail PS. Penyelenggaraan komputer yang kerap juga boleh membantu meningkatkan kelajuan berjalan PS.
 Bagaimana untuk menyelesaikan masalah pemuatan apabila PS membuka fail?
Apr 06, 2025 pm 06:33 PM
Bagaimana untuk menyelesaikan masalah pemuatan apabila PS membuka fail?
Apr 06, 2025 pm 06:33 PM
"Memuatkan" gagap berlaku apabila membuka fail pada PS. Sebab-sebabnya mungkin termasuk: fail yang terlalu besar atau rosak, memori yang tidak mencukupi, kelajuan cakera keras perlahan, masalah pemacu kad grafik, versi PS atau konflik plug-in. Penyelesaiannya ialah: Semak saiz fail dan integriti, tingkatkan memori, menaik taraf cakera keras, mengemas kini pemacu kad grafik, menyahpasang atau melumpuhkan pemalam yang mencurigakan, dan memasang semula PS. Masalah ini dapat diselesaikan dengan berkesan dengan memeriksa secara beransur -ansur dan memanfaatkan tetapan prestasi PS yang baik dan membangunkan tabiat pengurusan fail yang baik.
 Bagaimana untuk menyelesaikan masalah pemuatan apabila PS sentiasa menunjukkan bahawa ia memuatkan?
Apr 06, 2025 pm 06:30 PM
Bagaimana untuk menyelesaikan masalah pemuatan apabila PS sentiasa menunjukkan bahawa ia memuatkan?
Apr 06, 2025 pm 06:30 PM
Kad PS adalah "Memuatkan"? Penyelesaian termasuk: Memeriksa konfigurasi komputer (memori, cakera keras, pemproses), membersihkan pemecahan cakera keras, mengemas kini pemacu kad grafik, menyesuaikan tetapan PS, memasang semula PS, dan membangunkan tabiat pengaturcaraan yang baik.
 Apakah perbezaan antara pengeluaran halaman H5 dan laman web tradisional
Apr 06, 2025 am 07:03 AM
Apakah perbezaan antara pengeluaran halaman H5 dan laman web tradisional
Apr 06, 2025 am 07:03 AM
Perbezaan utama antara halaman H5 melalui laman web tradisional adalah keutamaan dan fleksibiliti mudah alih mereka, yang lebih sesuai untuk peranti mudah alih dan mempunyai kecekapan pembangunan yang lebih cepat dan keserasian silang platform yang lebih baik. Khususnya, halaman H5 memperkenalkan ciri -ciri baru seperti tag semantik, sokongan multimedia, penyimpanan luar talian, dan lokasi geografi, meningkatkan pengalaman mudah alih.
