

scrapy抓取学院新闻报告实例

抓取四川大学公共管理学院官网()所有的新闻咨询.
实验流程
1.确定抓取目标.
2.制定抓取规则.
3.'编写/调试'抓取规则.
4.获得抓取数据
1.确定抓取目标
我们这次需要抓取的目标为四川大学公共管理学院的所有新闻资讯.于是我们需要知道公管学院官网的布局结构.
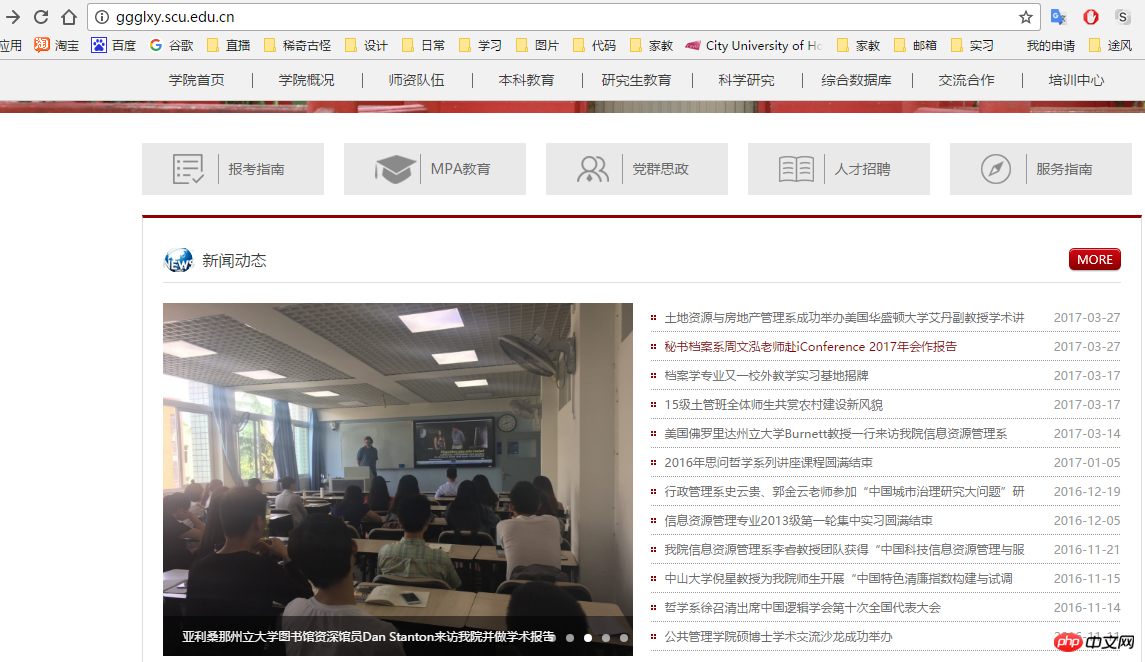
这里我们发现想要抓到全部的新闻信息,不能直接在官网首页进行抓取,需要点击"more"进入到新闻总栏目里面.

我们看到了具体的新闻栏目,但是这显然不满足我们的抓取需求: 当前新闻动态网页只能抓取新闻的时间,标题和URL,但是并不能抓取新闻的内容.所以我们想要需要进入到新闻详情页抓取新闻的具体内容.
2.制定抓取规则
通过第一部分的分析,我们会想到,如果我们要抓取一篇新闻的具体信息,需要从新闻动态页面点击进入新闻详情页抓取到新闻的具体内容.我们点击一篇新闻尝试一下

我们发现,我们能够直接在新闻详情页面抓取到我们需要的数据:标题,时间,内容.URL.
好,到现在我们清楚抓取一篇新闻的思路了.但是,如何抓取所有的新闻内容呢?
这显然难不到我们.

我们在新闻栏目的最下方能够看到页面跳转的按钮.那么我们可以通过"下一页"按钮实现抓取所有的新闻.
那么整理一下思路,我们能够想到一个显而易见的抓取规则:
通过抓取'新闻栏目下'所有的新闻链接,并且进入到新闻详情链接里面抓取所有的新闻内容.
3.'编写/调试'抓取规则
为了让调试爬虫的粒度尽量的小,我将编写和调试模块糅合在一起进行.
在爬虫中,我将实现以下几个功能点:
1.爬出一页新闻栏目下的所有新闻链接
2.通过爬到的一页新闻链接进入到新闻详情爬取所需要数据(主要是新闻内容)
3.通过循环爬取到所有的新闻.
分别对应的知识点为:
1.爬出一个页面下的基础数据.
2.通过爬到的数据进行二次爬取.
3.通过循环对网页进行所有数据的爬取.
话不多说,现在开干.
3.1爬出一页新闻栏目下的所有新闻链接

通过对新闻栏目的源代码分析,我们发现所抓数据的结构为

那么我们只需要将爬虫的选择器定位到(li:newsinfo_box_cf),再进行for循环抓取即可.
编写代码
import scrapyclass News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = ["http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=1",
]def parse(self, response):for href in response.xpath("//div[@class='newsinfo_box cf']"):
url = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())测试,通过!

3.2通过爬到的一页新闻链接进入到新闻详情爬取所需要数据(主要是新闻内容)
现在我获得了一组URL,现在我需要进入到每一个URL中抓取我所需要的标题,时间和内容,代码实现也挺简单,只需要在原有代码抓到一个URL时进入该URL并且抓取相应的数据即可.所以,我只需要再写一个进入新闻详情页的抓取方法,并且使用scapy.request调用即可.
编写代码
#进入新闻详情页的抓取方法
def parse_dir_contents(self, response):item = GgglxyItem()item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()item['href'] = responseitem['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")item['content'] = data[0].xpath('string(.)').extract()[0]
yield item整合进原有代码后,有:
import scrapyfrom ggglxy.items import GgglxyItemclass News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = ["http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=1",
]def parse(self, response):for href in response.xpath("//div[@class='newsinfo_box cf']"):
url = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())#调用新闻抓取方法yield scrapy.Request(url, callback=self.parse_dir_contents)#进入新闻详情页的抓取方法 def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0]yield item测试,通过!

这时我们加一个循环:
NEXT_PAGE_NUM = 1
NEXT_PAGE_NUM = NEXT_PAGE_NUM + 1if NEXT_PAGE_NUM<11:next_url = 'http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=%s' % NEXT_PAGE_NUM
yield scrapy.Request(next_url, callback=self.parse)加入到原本代码:
import scrapyfrom ggglxy.items import GgglxyItem
NEXT_PAGE_NUM = 1class News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = ["http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=1",
]def parse(self, response):for href in response.xpath("//div[@class='newsinfo_box cf']"):
URL = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())yield scrapy.Request(URL, callback=self.parse_dir_contents)global NEXT_PAGE_NUM
NEXT_PAGE_NUM = NEXT_PAGE_NUM + 1if NEXT_PAGE_NUM<11:
next_url = 'http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=%s' % NEXT_PAGE_NUMyield scrapy.Request(next_url, callback=self.parse) def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0] yield item测试:

抓到的数量为191,但是我们看官网发现有193条新闻,少了两条.
为啥呢?我们注意到log的error有两条:
定位问题:原来发现,学院的新闻栏目还有两条隐藏的二级栏目:
比如:

对应的URL为

URL都长的不一样,难怪抓不到了!
那么我们还得为这两条二级栏目的URL设定专门的规则,只需要加入判断是否为二级栏目:
if URL.find('type') != -1: yield scrapy.Request(URL, callback=self.parse)
组装原函数:
import scrapy
from ggglxy.items import GgglxyItem
NEXT_PAGE_NUM = 1class News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = ["http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=1",
]def parse(self, response):for href in response.xpath("//div[@class='newsinfo_box cf']"):
URL = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())if URL.find('type') != -1:yield scrapy.Request(URL, callback=self.parse)yield scrapy.Request(URL, callback=self.parse_dir_contents)
global NEXT_PAGE_NUM
NEXT_PAGE_NUM = NEXT_PAGE_NUM + 1if NEXT_PAGE_NUM<11:
next_url = 'http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=%s' % NEXT_PAGE_NUMyield scrapy.Request(next_url, callback=self.parse) def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0] yield item测试:

我们发现,抓取的数据由以前的193条增加到了238条,log里面也没有error了,说明我们的抓取规则OK!
4.获得抓取数据
<code class="haxe"> scrapy crawl <span class="hljs-keyword">new<span class="hljs-type">s_info_2 -o <span class="hljs-number">0016.json</span></span></span></code><br/><br/>
Atas ialah kandungan terperinci scrapy抓取学院新闻报告实例. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Scrapy melaksanakan rangkak dan analisis artikel akaun awam WeChat
Jun 22, 2023 am 09:41 AM
Scrapy melaksanakan rangkak dan analisis artikel akaun awam WeChat
Jun 22, 2023 am 09:41 AM
Scrapy melaksanakan rangkak artikel dan analisis akaun awam WeChat WeChat ialah aplikasi media sosial yang popular dalam beberapa tahun kebelakangan ini, dan akaun awam yang dikendalikan di dalamnya juga memainkan peranan yang sangat penting. Seperti yang kita sedia maklum, akaun awam WeChat adalah lautan maklumat dan pengetahuan, kerana setiap akaun awam boleh menerbitkan artikel, mesej grafik dan maklumat lain. Maklumat ini boleh digunakan secara meluas dalam banyak bidang, seperti laporan media, penyelidikan akademik, dsb. Jadi, artikel ini akan memperkenalkan cara menggunakan rangka kerja Scrapy untuk merangkak dan menganalisis artikel akaun awam WeChat. Scr
 Analisis kes buruk: Cara merangkak maklumat syarikat di LinkedIn
Jun 23, 2023 am 10:04 AM
Analisis kes buruk: Cara merangkak maklumat syarikat di LinkedIn
Jun 23, 2023 am 10:04 AM
Scrapy ialah rangka kerja perangkak berasaskan Python yang boleh mendapatkan maklumat berkaitan dengan cepat dan mudah di Internet. Dalam artikel ini, kami akan menggunakan kes Scrapy untuk menganalisis secara terperinci cara merangkak maklumat syarikat di LinkedIn. Tentukan URL sasaran Mula-mula, kita perlu menjelaskan dengan jelas bahawa sasaran kita ialah maklumat syarikat di LinkedIn. Oleh itu, kita perlu mencari URL halaman maklumat syarikat LinkedIn. Buka laman web LinkedIn, masukkan nama syarikat dalam kotak carian, dan
 Kaedah pelaksanaan pemuatan asynchronous Scrapy berdasarkan Ajax
Jun 22, 2023 pm 11:09 PM
Kaedah pelaksanaan pemuatan asynchronous Scrapy berdasarkan Ajax
Jun 22, 2023 pm 11:09 PM
Scrapy ialah rangka kerja perangkak Python sumber terbuka yang boleh mendapatkan data daripada tapak web dengan cepat dan cekap. Walau bagaimanapun, banyak tapak web menggunakan teknologi pemuatan tak segerak Ajax, menjadikannya mustahil untuk Scrapy mendapatkan data secara langsung. Artikel ini akan memperkenalkan kaedah pelaksanaan Scrapy berdasarkan pemuatan tak segerak Ajax. 1. Prinsip pemuatan tak segerak Ajax Pemuatan tak segerak Ajax: Dalam kaedah pemuatan halaman tradisional, selepas pelayar menghantar permintaan kepada pelayan, ia mesti menunggu pelayan mengembalikan respons dan memuatkan keseluruhan halaman sebelum meneruskan ke langkah seterusnya.
 Petua pengoptimuman buruk: Cara mengurangkan rangkak URL pendua dan meningkatkan kecekapan
Jun 22, 2023 pm 01:57 PM
Petua pengoptimuman buruk: Cara mengurangkan rangkak URL pendua dan meningkatkan kecekapan
Jun 22, 2023 pm 01:57 PM
Scrapy ialah rangka kerja perangkak Python yang berkuasa yang boleh digunakan untuk mendapatkan sejumlah besar data daripada Internet. Walau bagaimanapun, apabila membangunkan Scrapy, kami sering menghadapi masalah merangkak URL pendua, yang membuang banyak masa dan sumber serta menjejaskan kecekapan. Artikel ini akan memperkenalkan beberapa teknik pengoptimuman Scrapy untuk mengurangkan rangkak URL pendua dan meningkatkan kecekapan perangkak Scrapy. 1. Gunakan atribut start_urls dan allowed_domains dalam perangkak Scrapy untuk
 Bagaimana untuk membuka kandungan berita dan minat pada Windows 10
Jan 13, 2024 pm 05:54 PM
Bagaimana untuk membuka kandungan berita dan minat pada Windows 10
Jan 13, 2024 pm 05:54 PM
Bagi pengguna yang sangat meminati sistem pengendalian Windows 10, mereka pasti menyedari fungsi pengesyoran maklumat dan minat yang dibentangkan di sudut kanan bawah desktop mereka. Ciri ini akan menunjukkan kepada anda semua jenis maklumat berita yang menarik pada masa yang tepat Walau bagaimanapun, sesetengah pengguna mungkin merasa terlalu rumit dan memilih untuk mematikannya, sebaliknya sesetengah pengguna memilih untuk mengekalkannya. Pada masa ini, anda boleh menggunakan langkah terperinci berikut untuk melaraskan tetapan ini dengan mudah pada bila-bila masa dan di mana-mana sahaja. Cara membuka berita dan minat dalam win10 1. Pertama tekan win+R dan kemudian masukkan "winver" dan tekan Enter Kemudian anda boleh menyemak maklumat versi komputer anda untuk mengesahkan sama ada ia adalah versi 21h1. 2. Klik kanan pada bar tugas dan pilih "Maklumat dan Minat" 3. Di sini
 Contoh mengikis maklumat Instagram menggunakan PHP
Jun 13, 2023 pm 06:26 PM
Contoh mengikis maklumat Instagram menggunakan PHP
Jun 13, 2023 pm 06:26 PM
Instagram adalah salah satu media sosial paling popular hari ini, dengan ratusan juta pengguna aktif. Pengguna memuat naik berbilion gambar dan video, dan data ini sangat berharga kepada banyak perniagaan dan individu. Oleh itu, dalam banyak kes, perlu menggunakan program untuk mengikis data Instagram secara automatik. Artikel ini akan memperkenalkan cara menggunakan PHP untuk menangkap data Instagram dan memberikan contoh pelaksanaan. Pasang sambungan cURL untuk PHP cURL ialah alat yang digunakan dalam pelbagai
 Menggunakan Selenium dan PhantomJS dalam perangkak Scrapy
Jun 22, 2023 pm 06:03 PM
Menggunakan Selenium dan PhantomJS dalam perangkak Scrapy
Jun 22, 2023 pm 06:03 PM
Menggunakan Selenium dan PhantomJSScrapy dalam perangkak Scrapy Scrapy ialah rangka kerja perangkak web yang sangat baik di bawah Python dan telah digunakan secara meluas dalam pengumpulan dan pemprosesan data dalam pelbagai bidang. Dalam pelaksanaan perangkak, kadangkala perlu untuk mensimulasikan operasi penyemak imbas untuk mendapatkan kandungan yang dibentangkan oleh tapak web tertentu Dalam kes ini, Selenium dan PhantomJS diperlukan. Selenium mensimulasikan operasi manusia pada penyemak imbas, membolehkan kami mengautomasikan ujian aplikasi web
 Penggunaan Scrapy yang mendalam: Bagaimana untuk merangkak data HTML, XML dan JSON?
Jun 22, 2023 pm 05:58 PM
Penggunaan Scrapy yang mendalam: Bagaimana untuk merangkak data HTML, XML dan JSON?
Jun 22, 2023 pm 05:58 PM
Scrapy ialah rangka kerja perangkak Python yang berkuasa yang boleh membantu kami mendapatkan data di Internet dengan cepat dan fleksibel. Dalam proses merangkak sebenar, kami sering menghadapi pelbagai format data seperti HTML, XML dan JSON. Dalam artikel ini, kami akan memperkenalkan cara menggunakan Scrapy untuk merangkak ketiga-tiga format data ini masing-masing. 1. Merangkak data HTML dan mencipta projek Scrapy Pertama, kita perlu membuat projek Scrapy. Buka baris arahan dan masukkan arahan berikut: scrapys
