

mongoDB是怎么实现分页的?

这篇文章主要为大家详细介绍了mongoDB实现分页的两种方法,具有一定的参考价值,感兴趣的小伙伴们可以参考一下
mongoDB的分页查询是通过limit(),skip(),sort()这三个函数组合进行分页查询的。
下面这个是我的测试数据
db.test.find().sort({"age":1});

第一种方法
查询第一页的数据:db.test.find().sort({"age":1}).limit(2);

查询第二页的数据:db.test.find().sort({"age":1}).skip(2).limit(2);

查询其他页数以此类推。。。
第二种方法
查询第一页的数据:db.test.find().sort({"age":1}).limit(2);
跟上面的第一种方法一样的。
查询第二页的数据:
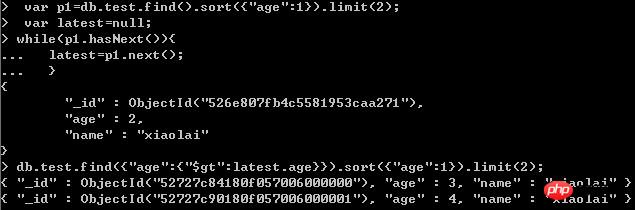
这个是获取第一页最后一条记录的值,然后排除前面的记录,就能获取到新的记录了
总结来说,如果数据量不是很大的话,可以使用第一种方法,毕竟比较简单,如果数据量比较大的话,使用第二种方法比较好,因为这样就可以不用到skip()这个函数,skip跳过太多的记录,效率有点低
经过认真的考虑,第二种方法确实不适合跳页,而且效率也不是很高
对于海量数据的话,我们要做些特殊的处理,
有以下2种方法
第一种方法

限制分页的页数,类似百度的百度的分页处理,只是显示前面的七百多条记录,这样的就不用考虑性能的问题了,毕竟一般人都只是翻到前面十页,就找到自己需要的了
后面的统计结果应该是估算出来的,根据查出来的这些记录所占的比例估算出总的记录数
第二种方法
我们可以这样做,假设是根据id排序的,我们可以id跟id所在的页数的序号存到redis/MemberCached中,
就像这样,假设每一页有10条记录
id page
1 1
2 1
。。。
10 1
11 2
12 2
。。。。
20 2
这样我们查第一页的时候就能直接取出十条数据
假设有1亿条数据,一条记录id占4个字节,其他信息的占一个字节,一条记录就占5个字节
1 0000 0000 *5/(1024*1024)=476MB
这种做法使用空间换时间,一般数据库查询的时间大多花在跟数据库的连接上,放在缓存中,可以大大加快查询的速度
Atas ialah kandungan terperinci mongoDB是怎么实现分页的?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1389
1389
 52
52

 Bagaimana untuk mengenal pasti kotak kasut tulen dan palsu bagi kasut Nike (kuasai satu helah untuk mengenal pasti dengan mudah)
Sep 02, 2024 pm 04:11 PM
Bagaimana untuk mengenal pasti kotak kasut tulen dan palsu bagi kasut Nike (kuasai satu helah untuk mengenal pasti dengan mudah)
Sep 02, 2024 pm 04:11 PM
Sebagai jenama sukan yang terkenal di dunia, kasut Nike telah menarik perhatian ramai. Bagaimanapun, terdapat juga sejumlah besar produk tiruan di pasaran, termasuk kotak kasut Nike palsu. Membezakan kotak kasut tulen daripada yang palsu adalah penting untuk melindungi hak dan kepentingan pengguna. Artikel ini akan memberi anda beberapa kaedah yang mudah dan berkesan untuk membantu anda membezakan antara kotak kasut asli dan palsu. 1: Tajuk pembungkusan luar Dengan memerhatikan pembungkusan luar kotak kasut Nike, anda boleh menemui banyak perbezaan yang ketara. Kotak kasut Nike tulen biasanya mempunyai bahan kertas berkualiti tinggi yang licin untuk disentuh dan tidak mempunyai bau pedas yang jelas. Fon dan logo pada kotak kasut tulen biasanya jelas dan terperinci, dan tiada kabur atau ketidakkonsistenan warna. 2: LOGO tajuk hot stamping LOGO pada kotak kasut Nike biasanya hot stamping Bahagian hot stamping pada kotak kasut tulen akan ditunjukkan
 Cara mengkonfigurasi pengembangan automatik MongoDB pada Debian
Apr 02, 2025 am 07:36 AM
Cara mengkonfigurasi pengembangan automatik MongoDB pada Debian
Apr 02, 2025 am 07:36 AM
Artikel ini memperkenalkan cara mengkonfigurasi MongoDB pada sistem Debian untuk mencapai pengembangan automatik. Langkah -langkah utama termasuk menubuhkan set replika MongoDB dan pemantauan ruang cakera. 1. Pemasangan MongoDB Pertama, pastikan MongoDB dipasang pada sistem Debian. Pasang menggunakan arahan berikut: SudoaptDateSudoaptInstall-ImongoDB-Org 2. Mengkonfigurasi set replika replika MongoDB MongoDB Set memastikan ketersediaan dan kelebihan data yang tinggi, yang merupakan asas untuk mencapai pengembangan kapasiti automatik. Mula MongoDB Service: sudosystemctlstartmongodsudosys
 Cara menangani kegelisahan video (petua praktikal untuk membantu anda menghapuskan kegelisahan video)
Sep 02, 2024 pm 03:53 PM
Cara menangani kegelisahan video (petua praktikal untuk membantu anda menghapuskan kegelisahan video)
Sep 02, 2024 pm 03:53 PM
Gegaran ialah masalah biasa semasa merakam atau menonton video, yang menjejaskan pengalaman menonton dan mengurangkan kualiti video. Artikel ini akan memperkenalkan beberapa petua praktikal untuk membantu anda menangani masalah kegelisahan video dan menjadikan video anda lebih stabil dan lancar. 1. Gunakan Teknologi Penstabil untuk Menghapuskan Gegaran Video Menggunakan alat penstabil adalah salah satu cara paling mudah dan berkesan untuk menyelesaikan masalah gegaran video. Penstabil boleh mengurangkan kegelisahan yang disebabkan oleh goncangan tangan atau faktor lain dengan mengimbangi dan menstabilkan kamera. 2. Pengenalan kepada teknologi penstabilan video perisian Teknologi penstabilan video perisian menghilangkan kegelisahan dengan melaraskan video dalam pemprosesan pasca. Teknologi ini boleh memberikan penstabilan video yang lebih baik dengan menjejak bingkai utama, menggunakan algoritma penstabilan imej dan banyak lagi. 3. Pengesanan jitter video dan pembaikan automatik
 Cara Memastikan Ketersediaan MongoDB Tinggi di Debian
Apr 02, 2025 am 07:21 AM
Cara Memastikan Ketersediaan MongoDB Tinggi di Debian
Apr 02, 2025 am 07:21 AM
Artikel ini menerangkan cara membina pangkalan data MongoDB yang sangat tersedia pada sistem Debian. Kami akan meneroka pelbagai cara untuk memastikan keselamatan data dan perkhidmatan terus beroperasi. Strategi Utama: Replicaset: Replicaset: Gunakan replika untuk mencapai redundansi data dan failover automatik. Apabila nod induk gagal, set replika secara automatik akan memilih nod induk baru untuk memastikan ketersediaan perkhidmatan yang berterusan. Sandaran dan Pemulihan Data: Secara kerap Gunakan perintah Mongodump untuk membuat sandaran pangkalan data dan merumuskan strategi pemulihan yang berkesan untuk menangani risiko kehilangan data. Pemantauan dan penggera: Menyebarkan alat pemantauan (seperti Prometheus, Grafana) untuk memantau status MongoDB dalam masa nyata, dan
 Cara menjadikan deposit bank anda lebih menjimatkan kos (strategi penjimatan wang didedahkan)
Aug 21, 2024 pm 04:21 PM
Cara menjadikan deposit bank anda lebih menjimatkan kos (strategi penjimatan wang didedahkan)
Aug 21, 2024 pm 04:21 PM
Dalam masyarakat moden, kita semua tidak dapat dipisahkan daripada akaun bank, dan menyimpan wang adalah interaksi paling asas antara kita dan bank. Walau bagaimanapun, ramai orang mempunyai keraguan dan kekeliruan tertentu tentang cara membuat simpanan mereka lebih menjimatkan kos. Artikel ini akan memberi anda beberapa nasihat penjimatan wang yang praktikal untuk membantu anda meningkatkan nilai simpanan anda. Perenggan 1 Rancangan Kewangan: Pelan tindakan untuk pertumbuhan kekayaan masa hadapan Membangunkan pelan kewangan adalah asas untuk mengurus dan mengembangkan simpanan anda dengan berkesan. Kenal pasti matlamat kewangan anda, kedua-dua jangka pendek dan panjang. Bangunkan pelan simpanan khusus berdasarkan matlamat ini, tetapkan masa, jumlah dan kaedah deposit yang diperlukan untuk setiap matlamat. Semak dan laraskan pelan anda secara kerap untuk menyesuaikan diri dengan keadaan ekonomi dan keperluan peribadi yang berubah-ubah. Perenggan 2 Memilih Akaun Simpanan Kadar Faedah Tinggi: Tingkatkan Pulangan Deposit Pilih Kadar Faedah Tinggi
 Kaedah Navicat untuk melihat kata laluan pangkalan data MongoDB
Apr 08, 2025 pm 09:39 PM
Kaedah Navicat untuk melihat kata laluan pangkalan data MongoDB
Apr 08, 2025 pm 09:39 PM
Tidak mustahil untuk melihat kata laluan MongoDB secara langsung melalui Navicat kerana ia disimpan sebagai nilai hash. Cara mendapatkan kata laluan yang hilang: 1. Tetapkan semula kata laluan; 2. Periksa fail konfigurasi (mungkin mengandungi nilai hash); 3. Semak Kod (boleh kata laluan Hardcode).
 Kemas kini utama Pi Coin: Pi Bank akan datang!
Mar 03, 2025 pm 06:18 PM
Kemas kini utama Pi Coin: Pi Bank akan datang!
Mar 03, 2025 pm 06:18 PM
Pinetwork akan melancarkan Pibank, platform perbankan mudah alih revolusioner! Pinetwork hari ini mengeluarkan kemas kini utama mengenai Pimisrbank Elmahrosa (muka), yang disebut sebagai Pibank, yang mengintegrasikan dengan baik perkhidmatan perbankan tradisi C). Apakah pesona Pibank? Mari kita cari! Fungsi utama Pibank: Pengurusan sehenti akaun bank dan aset cryptocurrency. Menyokong urus niaga masa nyata dan mengamalkan biospesies
 Cara Menyulitkan Data dalam Debian Mongodb
Apr 12, 2025 pm 08:03 PM
Cara Menyulitkan Data dalam Debian Mongodb
Apr 12, 2025 pm 08:03 PM
Menyulitkan pangkalan data MongoDB pada sistem Debian memerlukan langkah berikut: Langkah 1: Pasang MongoDB terlebih dahulu, pastikan sistem Debian anda dipasang MongoDB. Jika tidak, sila rujuk kepada dokumen MongoDB rasmi untuk pemasangan: https://docs.mongodb.com/manual/tutorial/install-mongodb-on-debian/step 2: menghasilkan fail kunci penyulitan Buat fail yang mengandungi kunci penyulitan dan tetapkan kebenaran yang betul:
