

分享用MongoDB中oplog机制实现数据监控实例

MongoDB 的Replication是通过一个日志来存储写操作的,这个日志就叫做oplog,而下面这篇文章主要给大家介绍了利用MongoDB中oplog机制实现准实时数据的操作监控的相关资料,需要的朋友可以参考借鉴,下面来一起看看吧。
前言
最近有一个需求是要实时获取到新插入到MongoDB的数据,而插入程序本身已经有一套处理逻辑,所以不方便直接在插入程序里写相关程序,传统的数据库大多自带这种触发器机制,但是Mongo没有相关的函数可以用(也可能我了解的太少了,求纠正),当然还有一点是需要python实现,于是收集整理了一个相应的实现方法。
一、引子
首先可以想到,这种需求其实很像数据库的主从备份机制,从数据库之所以能够同步主库是因为存在某些指标来做控制,我们知道MongoDB虽然没有现成触发器,但是它能够实现主从备份,所以我们就从它的主从备份机制入手。
二、OPLOG
首先,需要以master模式来打开mongod守护,命令行使用–master,或者配置文件增加master键为true。
此时,我们可以在Mongo的系统库local里见到新增的collection——oplog,此时oplog.$main里就会存储进oplog信息,如果此时还有充当从数据库的Mongo存在,就会还有一些slaves的信息,由于我们这里并不是主从同步,所以不存在这些集合。
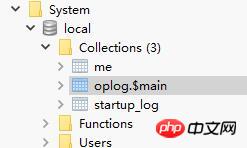
再来看看oplog结构:
"ts" : Timestamp(6417682881216249, 1), 时间戳
"h" : NumberLong(0), 长度
"v" : 2,
"op" : "n", 操作类型
"ns" : "", 操作的库和集合
"o2" : "_id" update条件
"o" : {} 操作值,即document这里需要知道op的几种属性:
insert,'i' update, 'u' remove(delete), 'd' cmd, 'c' noop, 'n' 空操作
从上面的信息可以看出,我们只要不断读取到ts来做对比,然后根据op即可判断当前出现的是什么操作,相当于使用程序实现了一个从数据库的接收端。
三、CODE
在Github上找到了别人的实现方式,不过它的函数库太老旧,所以在他的基础上进行修改。
Github地址:github.com/RedBeard0531/mongo-oplog-watcher
mongo_oplog_watcher.py如下:
#!/usr/bin/python
import pymongo
import re
import time
from pprint import pprint # pretty printer
from pymongo.errors import AutoReconnect
class OplogWatcher(object):
def init(self, db=None, collection=None, poll_time=1.0, connection=None, start_now=True):
if collection is not None:
if db is None:
raise ValueError('must specify db if you specify a collection')
self._ns_filter = db + '.' + collection
elif db is not None:
self._ns_filter = re.compile(r'^%s\.' % db)
else:
self._ns_filter = None
self.poll_time = poll_time
self.connection = connection or pymongo.Connection()
if start_now:
self.start()
@staticmethod
def get_id(op):
id = None
o2 = op.get('o2')
if o2 is not None:
id = o2.get('_id')
if id is None:
id = op['o'].get('_id')
return id
def start(self):
oplog = self.connection.local['oplog.$main']
ts = oplog.find().sort('$natural', -1)[0]['ts']
while True:
if self._ns_filter is None:
filter = {}
else:
filter = {'ns': self._ns_filter}
filter['ts'] = {'$gt': ts}
try:
cursor = oplog.find(filter, tailable=True)
while True:
for op in cursor:
ts = op['ts']
id = self.get_id(op)
self.all_with_noop(ns=op['ns'], ts=ts, op=op['op'], id=id, raw=op)
time.sleep(self.poll_time)
if not cursor.alive:
break
except AutoReconnect:
time.sleep(self.poll_time)
def all_with_noop(self, ns, ts, op, id, raw):
if op == 'n':
self.noop(ts=ts)
else:
self.all(ns=ns, ts=ts, op=op, id=id, raw=raw)
def all(self, ns, ts, op, id, raw):
if op == 'i':
self.insert(ns=ns, ts=ts, id=id, obj=raw['o'], raw=raw)
elif op == 'u':
self.update(ns=ns, ts=ts, id=id, mod=raw['o'], raw=raw)
elif op == 'd':
self.delete(ns=ns, ts=ts, id=id, raw=raw)
elif op == 'c':
self.command(ns=ns, ts=ts, cmd=raw['o'], raw=raw)
elif op == 'db':
self.db_declare(ns=ns, ts=ts, raw=raw)
def noop(self, ts):
pass
def insert(self, ns, ts, id, obj, raw, **kw):
pass
def update(self, ns, ts, id, mod, raw, **kw):
pass
def delete(self, ns, ts, id, raw, **kw):
pass
def command(self, ns, ts, cmd, raw, **kw):
pass
def db_declare(self, ns, ts, **kw):
pass
class OplogPrinter(OplogWatcher):
def all(self, **kw):
pprint (kw)
print #newline
if name == 'main':
OplogPrinter()首先是实现一个数据库的初始化,设定一个延迟时间(准实时):
self.poll_time = poll_time self.connection = connection or pymongo.MongoClient()
主要的函数是start() ,实现一个时间的比对并进行相应字段的处理:
def start(self):
oplog = self.connection.local['oplog.$main']
#读取之前提到的库
ts = oplog.find().sort('$natural', -1)[0]['ts']
#获取一个时间边际
while True:
if self._ns_filter is None:
filter = {}
else:
filter = {'ns': self._ns_filter}
filter['ts'] = {'$gt': ts}
try:
cursor = oplog.find(filter)
#对此时间之后的进行处理
while True:
for op in cursor:
ts = op['ts']
id = self.get_id(op)
self.all_with_noop(ns=op['ns'], ts=ts, op=op['op'], id=id, raw=op)
#可以指定处理插入监控,更新监控或者删除监控等
time.sleep(self.poll_time)
if not cursor.alive:
break
except AutoReconnect:
time.sleep(self.poll_time)循环这个start函数,在all_with_noop这里就可以编写相应的监控处理逻辑。
这样就可以实现一个简易的准实时Mongo数据库操作监控器,下一步就可以配合其他操作来对新入库的程序进行相应处理。
Atas ialah kandungan terperinci 分享用MongoDB中oplog机制实现数据监控实例. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Apa yang perlu dilakukan jika navicat tamat tempoh
Apr 23, 2024 pm 12:12 PM
Apa yang perlu dilakukan jika navicat tamat tempoh
Apr 23, 2024 pm 12:12 PM
Penyelesaian untuk menyelesaikan isu tamat tempoh Navicat termasuk: memperbaharui lesen dan menyahpasang semula kemas kini automatik, hubungi Navicat Premium Essentials;
 Bagaimana untuk menyambungkan navicat ke mongodb
Apr 24, 2024 am 11:27 AM
Bagaimana untuk menyambungkan navicat ke mongodb
Apr 24, 2024 am 11:27 AM
Untuk menyambung ke MongoDB menggunakan Navicat, anda perlu: Pasang Navicat Buat sambungan MongoDB: a Masukkan nama sambungan, alamat hos dan port b Masukkan maklumat pengesahan (jika perlu) Tambah sijil SSL (jika perlu) Sahkan sambungan Simpan sambungan
 Apakah kegunaan net4.0
May 10, 2024 am 01:09 AM
Apakah kegunaan net4.0
May 10, 2024 am 01:09 AM
.NET 4.0 digunakan untuk mencipta pelbagai aplikasi dan ia menyediakan pemaju aplikasi dengan ciri yang kaya termasuk: pengaturcaraan berorientasikan objek, fleksibiliti, seni bina berkuasa, penyepaduan pengkomputeran awan, pengoptimuman prestasi, perpustakaan yang luas, keselamatan, Kebolehskalaan, akses data dan mudah alih sokongan pembangunan.
 Penyepaduan fungsi dan pangkalan data Java dalam seni bina tanpa pelayan
Apr 28, 2024 am 08:57 AM
Penyepaduan fungsi dan pangkalan data Java dalam seni bina tanpa pelayan
Apr 28, 2024 am 08:57 AM
Dalam seni bina tanpa pelayan, fungsi Java boleh disepadukan dengan pangkalan data untuk mengakses dan memanipulasi data dalam pangkalan data. Langkah utama termasuk: mencipta fungsi Java, mengkonfigurasi pembolehubah persekitaran, menggunakan fungsi dan menguji fungsi. Dengan mengikuti langkah ini, pembangun boleh membina aplikasi kompleks yang mengakses data yang disimpan dalam pangkalan data dengan lancar.
 Cara mengkonfigurasi pengembangan automatik MongoDB pada Debian
Apr 02, 2025 am 07:36 AM
Cara mengkonfigurasi pengembangan automatik MongoDB pada Debian
Apr 02, 2025 am 07:36 AM
Artikel ini memperkenalkan cara mengkonfigurasi MongoDB pada sistem Debian untuk mencapai pengembangan automatik. Langkah -langkah utama termasuk menubuhkan set replika MongoDB dan pemantauan ruang cakera. 1. Pemasangan MongoDB Pertama, pastikan MongoDB dipasang pada sistem Debian. Pasang menggunakan arahan berikut: SudoaptDateSudoaptInstall-ImongoDB-Org 2. Mengkonfigurasi set replika replika MongoDB MongoDB Set memastikan ketersediaan dan kelebihan data yang tinggi, yang merupakan asas untuk mencapai pengembangan kapasiti automatik. Mula MongoDB Service: sudosystemctlstartmongodsudosys
 Cara Memastikan Ketersediaan MongoDB Tinggi di Debian
Apr 02, 2025 am 07:21 AM
Cara Memastikan Ketersediaan MongoDB Tinggi di Debian
Apr 02, 2025 am 07:21 AM
Artikel ini menerangkan cara membina pangkalan data MongoDB yang sangat tersedia pada sistem Debian. Kami akan meneroka pelbagai cara untuk memastikan keselamatan data dan perkhidmatan terus beroperasi. Strategi Utama: Replicaset: Replicaset: Gunakan replika untuk mencapai redundansi data dan failover automatik. Apabila nod induk gagal, set replika secara automatik akan memilih nod induk baru untuk memastikan ketersediaan perkhidmatan yang berterusan. Sandaran dan Pemulihan Data: Secara kerap Gunakan perintah Mongodump untuk membuat sandaran pangkalan data dan merumuskan strategi pemulihan yang berkesan untuk menangani risiko kehilangan data. Pemantauan dan penggera: Menyebarkan alat pemantauan (seperti Prometheus, Grafana) untuk memantau status MongoDB dalam masa nyata, dan
 Bolehkah navicat menyambung ke mongodb?
Apr 23, 2024 pm 05:15 PM
Bolehkah navicat menyambung ke mongodb?
Apr 23, 2024 pm 05:15 PM
Ya, Navicat boleh menyambung ke pangkalan data MongoDB. Langkah khusus termasuk: Buka Navicat dan buat sambungan baharu. Pilih jenis pangkalan data sebagai MongoDB. Masukkan alamat hos MongoDB, port dan nama pangkalan data. Masukkan nama pengguna dan kata laluan MongoDB anda (jika perlu). Klik butang "Sambung".
 Kemas kini utama Pi Coin: Pi Bank akan datang!
Mar 03, 2025 pm 06:18 PM
Kemas kini utama Pi Coin: Pi Bank akan datang!
Mar 03, 2025 pm 06:18 PM
Pinetwork akan melancarkan Pibank, platform perbankan mudah alih revolusioner! Pinetwork hari ini mengeluarkan kemas kini utama mengenai Pimisrbank Elmahrosa (muka), yang disebut sebagai Pibank, yang mengintegrasikan dengan baik perkhidmatan perbankan tradisi C). Apakah pesona Pibank? Mari kita cari! Fungsi utama Pibank: Pengurusan sehenti akaun bank dan aset cryptocurrency. Menyokong urus niaga masa nyata dan mengamalkan biospesies
