

Python爬取qq音乐的过程实例

一、前言
qq music上的音乐还是不少的,有些时候想要下载好听的音乐,但有每次在网页下载都是烦人的登录什么的。于是,来了个qqmusic的爬虫。至少我觉得for循环爬虫,最核心的应该就是找到待爬元素所在url吧。下面开始找吧(讲的不对不要笑我)
<br>
二、Python爬取QQ音乐单曲
之前看的慕课网的一个视频, 很好地讲解了一般编写爬虫的步骤,我们也按这个来。
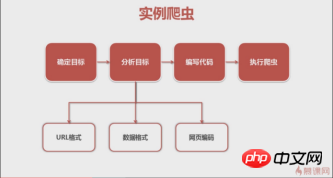
爬虫步骤
1.确定目标
首先我们要明确目标,本次爬取的是QQ音乐歌手刘德华的单曲。
(百度百科)->分析目标(策略:url格式(范围)、数据格式、网页编码)->编写代码->执行爬虫
2.分析目标
歌曲链接:
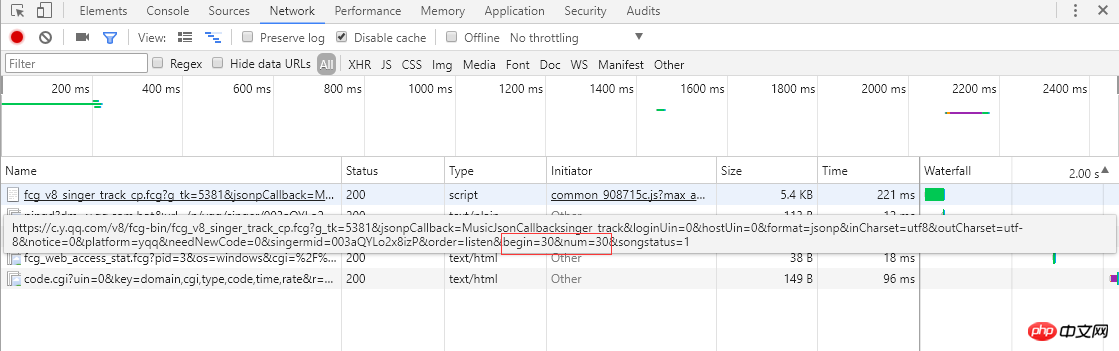
从左边的截图可以知道单曲采用分页的方式排列歌曲信息,每页显示30条,总共30页。点击页码或者最右边的">"会跳转到下一页,浏览器会向服务器发送ajax异步请求,从链接可以看到begin和num参数,分别代表起始歌曲下标(截图是第2页,起始下标是30)和一页返回30条,服务器响应返回json格式的歌曲信息(MusicJsonCallbacksinger_track({"code":0,"data":{"list":[{"Flisten_count1":......]})),如果只是单独想获取歌曲信息,可以直接拼接链接请求和解析返回的json格式的数据。这里不采用直接解析数据格式的方法,我采用的是Python Selenium方式,每获取和解析完一页的单曲信息,点击 ">" 跳转到下一页继续解析,直至解析并记录所有的单曲信息。最后请求每个单曲的链接,获取详细的单曲信息。
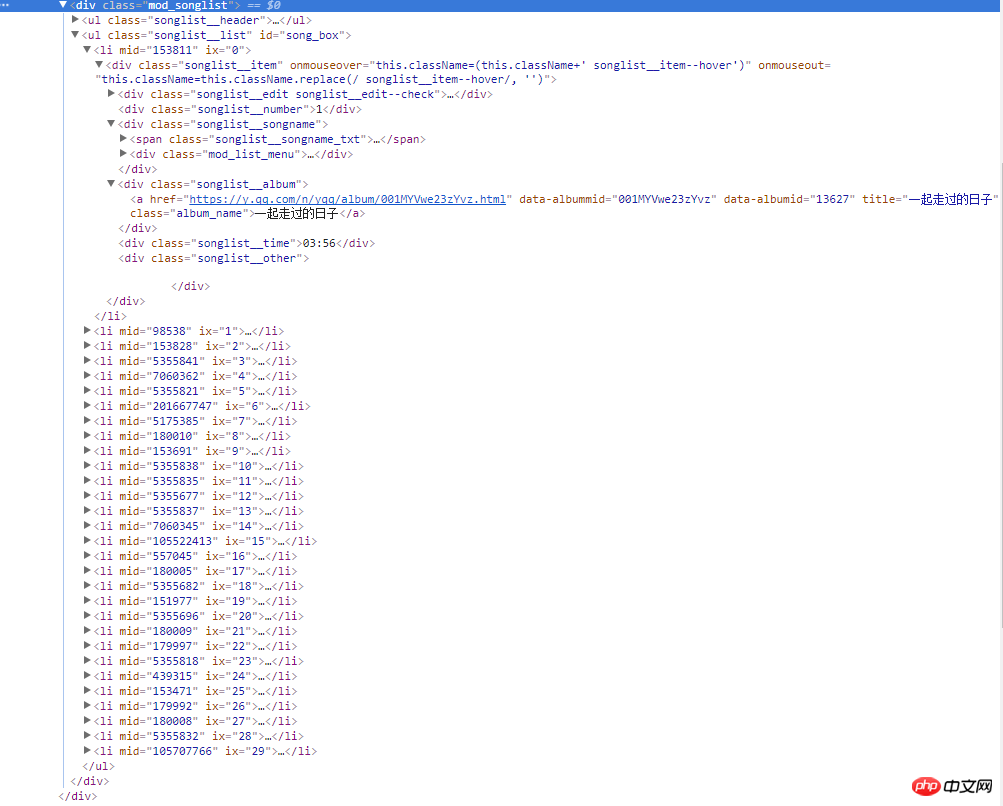
右边的截图是网页的源码,所有歌曲信息都在类名为mod_songlist的div浮层里面,类名为songlist_list的无序列表ul下,每个子元素li展示一个单曲,类名为songlist__album下的a标签,包含单曲的链接,名称和时长等。
3.编写代码
1)下载网页内容,这里使用Python 的Urllib标准库,自己封装了一个download方法:
def download(url, user_agent='wswp', num_retries=2):
if url is None:
return None
print('Downloading:', url)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
request = urllib.request.Request(url, headers=headers) # 设置用户代理wswp(Web Scraping with Python)
try:
html = urllib.request.urlopen(request).read().decode('utf-8')
except urllib.error.URLError as e:
print('Downloading Error:', e.reason)
html = None
if num_retries > 0:
if hasattr(e, 'code') and 500 <= e.code < 600:
# retry when return code is 5xx HTTP erros
return download(url, num_retries-1) # 请求失败,默认重试2次,
return html<br>2)解析网页内容,这里使用第三方插件BeautifulSoup,具体可以参考BeautifulSoup API 。
def music_scrapter(html, page_num=0):
try:
soup = BeautifulSoup(html, 'html.parser')
mod_songlist_div = soup.find_all('div', class_='mod_songlist')
songlist_ul = mod_songlist_div[1].find('ul', class_='songlist__list')
'''开始解析li歌曲信息'''
lis = songlist_ul.find_all('li')
for li in lis:
a = li.find('div', class_='songlist__album').find('a')
music_url = a['href'] # 单曲链接
urls.add_new_url(music_url) # 保存单曲链接
# print('music_url:{0} '.format(music_url))
print('total music link num:%s' % len(urls.new_urls))
next_page(page_num+1)
except TimeoutException as err:
print('解析网页出错:', err.args)
return next_page(page_num + 1)
return Nonedef get_music():
try:
while urls.has_new_url():
# print('urls count:%s' % len(urls.new_urls))
'''跳转到歌曲链接,获取歌曲详情'''
new_music_url = urls.get_new_url()
print('url leave count:%s' % str( len(urls.new_urls) - 1))
html_data_info = download(new_music_url)
# 下载网页失败,直接进入下一循环,避免程序中断
if html_data_info is None:
continue
soup_data_info = BeautifulSoup(html_data_info, 'html.parser')
if soup_data_info.find('div', class_='none_txt') is not None:
print(new_music_url, ' 对不起,由于版权原因,暂无法查看该专辑!')
continue
mod_songlist_div = soup_data_info.find('div', class_='mod_songlist')
songlist_ul = mod_songlist_div.find('ul', class_='songlist__list')
lis = songlist_ul.find_all('li')
del lis[0] # 删除第一个li
# print('len(lis):$s' % len(lis))
for li in lis:
a_songname_txt = li.find('div', class_='songlist__songname').find('span', class_='songlist__songname_txt').find('a')
if 'https' not in a_songname_txt['href']: #如果单曲链接不包含协议头,加上
song_url = 'https:' + a_songname_txt['href']
song_name = a_songname_txt['title']
singer_name = li.find('div', class_='songlist__artist').find('a').get_text()
song_time =li.find('div', class_='songlist__time').get_text()
music_info = {}
music_info['song_name'] = song_name
music_info['song_url'] = song_url
music_info['singer_name'] = singer_name
music_info['song_time'] = song_time
collect_data(music_info)
except Exception as err: # 如果解析异常,跳过
print('Downloading or parse music information error continue:', err.args)4.执行爬虫
<span style="font-size: 16px;">爬虫跑起来了,一页一页地去爬取专辑的链接,并保存到集合中,最后通过get_music()方法获取单曲的名称,链接,歌手名称和时长并保存到Excel文件中。</span><br><span style="font-size: 14px;"><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/001/a1138f33f00f8d95b52fbfe06e562d24-4.png" class="lazy" alt="" style="max-width:90%" style="max-width:90%"><strong><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/001/9282b5f7a1dc4a90cee186c16d036272-5.png" class="lazy" alt=""></strong></span>
<br>
三、Python爬取QQ音乐单曲总结
1.单曲采用的是分页方式,切换下一页是通过异步ajax请求从服务器获取json格式的数据并渲染到页面,浏览器地址栏链接是不变的,不能通过拼接链接来请求。一开始想过都通过Python Urllib库来模拟ajax请求,后来想想还是用Selenium。Selenium能够很好地模拟浏览器真实的操作,页面元素定位也很方便,模拟单击下一页,不断地切换单曲分页,再通过BeautifulSoup解析网页源码,获取单曲信息。
2.url链接管理器,采用集合数据结构来保存单曲链接,为什么要使用集合?因为多个单曲可能来自同一专辑(专辑网址一样),这样可以减少请求次数。
class UrlManager(object):<br> def __init__(self):<br> self.new_urls = set() # 使用集合数据结构,过滤重复元素<br> self.old_urls = set() # 使用集合数据结构,过滤重复元素
def add_new_url(self, url):<br> if url is None:<br> return<br> if url not in self.new_urls and url not in self.old_urls:<br> self.new_urls.add(url)<br><br> def add_new_urls(self, urls):<br> if urls is None or len(urls) == 0:<br> return<br> for url in urls:<br> self.add_new_url(url)<br><br> def has_new_url(self):<br> return len(self.new_urls) != 0<br><br> def get_new_url(self):<br> new_url = self.new_urls.pop()<br> self.old_urls.add(new_url)<br> return new_url<br><br>
3.通过Python第三方插件openpyxl读写Excel十分方便,把单曲信息通过Excel文件可以很好地保存起来。
def write_to_excel(self, content):<br> try:<br> for row in content:<br> self.workSheet.append([row['song_name'], row['song_url'], row['singer_name'], row['song_time']])<br> self.workBook.save(self.excelName) # 保存单曲信息到Excel文件<br> except Exception as arr:<br> print('write to excel error', arr.args)<br><br>
四、后语
最后还是要庆祝下,毕竟成功把QQ音乐的单曲信息爬取下来了。本次能够成功爬取单曲,Selenium功不可没,这次只是用到了selenium一些简单的功能,后续会更加深入学习Selenium,不仅在爬虫方面还有UI自动化。
后续还需要优化的点:
1.下载的链接比较多,一个一个下载起来比较慢,后面打算用多线程并发下载。
2.下载速度过快,为了避免服务器禁用IP,后面还要对于同一域名访问过于频繁的问题,有个等待机制,每个请求之间有个等待间隔。
3. 解析网页是一个重要的过程,可以采用正则表达式,BeautifulSoup和lxml,目前采用的是BeautifulSoup库, 在效率方面,BeautifulSoup没lxml效率高,后面会尝试采用lxml。
Atas ialah kandungan terperinci Python爬取qq音乐的过程实例. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 PHP dan Python: Membandingkan dua bahasa pengaturcaraan yang popular
Apr 14, 2025 am 12:13 AM
PHP dan Python: Membandingkan dua bahasa pengaturcaraan yang popular
Apr 14, 2025 am 12:13 AM
PHP dan Python masing -masing mempunyai kelebihan mereka sendiri, dan memilih mengikut keperluan projek. 1.PHP sesuai untuk pembangunan web, terutamanya untuk pembangunan pesat dan penyelenggaraan laman web. 2. Python sesuai untuk sains data, pembelajaran mesin dan kecerdasan buatan, dengan sintaks ringkas dan sesuai untuk pemula.
 Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Fungsi Readdir dalam sistem Debian adalah panggilan sistem yang digunakan untuk membaca kandungan direktori dan sering digunakan dalam pengaturcaraan C. Artikel ini akan menerangkan cara mengintegrasikan Readdir dengan alat lain untuk meningkatkan fungsinya. Kaedah 1: Menggabungkan Program Bahasa C dan Pipeline Pertama, tulis program C untuk memanggil fungsi Readdir dan output hasilnya:#termasuk#termasuk#includeintMain (intargc, char*argv []) {dir*dir; structdirent*entry; if (argc! = 2) {
 Cara mengkonfigurasi pelayan https di debian openssl
Apr 13, 2025 am 11:03 AM
Cara mengkonfigurasi pelayan https di debian openssl
Apr 13, 2025 am 11:03 AM
Mengkonfigurasi pelayan HTTPS pada sistem Debian melibatkan beberapa langkah, termasuk memasang perisian yang diperlukan, menghasilkan sijil SSL, dan mengkonfigurasi pelayan web (seperti Apache atau Nginx) untuk menggunakan sijil SSL. Berikut adalah panduan asas, dengan mengandaikan anda menggunakan pelayan Apacheweb. 1. Pasang perisian yang diperlukan terlebih dahulu, pastikan sistem anda terkini dan pasang Apache dan OpenSSL: sudoaptDateSudoaptgradesudoaptinsta
 Python dan Masa: Memanfaatkan masa belajar anda
Apr 14, 2025 am 12:02 AM
Python dan Masa: Memanfaatkan masa belajar anda
Apr 14, 2025 am 12:02 AM
Untuk memaksimumkan kecekapan pembelajaran Python dalam masa yang terhad, anda boleh menggunakan modul, masa, dan modul Python. 1. Modul DateTime digunakan untuk merakam dan merancang masa pembelajaran. 2. Modul Masa membantu menetapkan kajian dan masa rehat. 3. Modul Jadual secara automatik mengatur tugas pembelajaran mingguan.
 Panduan Pembangunan Plug-In Gitlab di Debian
Apr 13, 2025 am 08:24 AM
Panduan Pembangunan Plug-In Gitlab di Debian
Apr 13, 2025 am 08:24 AM
Membangunkan plugin Gitlab pada Debian memerlukan beberapa langkah dan pengetahuan tertentu. Berikut adalah panduan asas untuk membantu anda memulakan proses ini. Memasang GitLab terlebih dahulu, anda perlu memasang GitLab pada sistem Debian anda. Anda boleh merujuk kepada manual pemasangan rasmi GitLab. Dapatkan token akses API sebelum melakukan integrasi API, anda perlu mendapatkan token akses API Gitlab terlebih dahulu. Buka papan pemuka Gitlab, cari pilihan "AccessTokens" dalam tetapan pengguna, dan menghasilkan token akses baru. Akan dijana
 Perkhidmatan apa yang Apache
Apr 13, 2025 pm 12:06 PM
Perkhidmatan apa yang Apache
Apr 13, 2025 pm 12:06 PM
Apache adalah wira di belakang internet. Ia bukan sahaja pelayan web, tetapi juga platform yang kuat yang menyokong lalu lintas yang besar dan menyediakan kandungan dinamik. Ia memberikan fleksibiliti yang sangat tinggi melalui reka bentuk modular, yang membolehkan pengembangan pelbagai fungsi seperti yang diperlukan. Walau bagaimanapun, modulariti juga membentangkan cabaran konfigurasi dan prestasi yang memerlukan pengurusan yang teliti. Apache sesuai untuk senario pelayan yang memerlukan keperluan yang sangat disesuaikan dan memenuhi keperluan kompleks.
 PHP dan Python: Contoh dan perbandingan kod
Apr 15, 2025 am 12:07 AM
PHP dan Python: Contoh dan perbandingan kod
Apr 15, 2025 am 12:07 AM
PHP dan Python mempunyai kelebihan dan kekurangan mereka sendiri, dan pilihannya bergantung kepada keperluan projek dan keutamaan peribadi. 1.PHP sesuai untuk pembangunan pesat dan penyelenggaraan aplikasi web berskala besar. 2. Python menguasai bidang sains data dan pembelajaran mesin.
 Bahasa apa yang ditulis Apache?
Apr 13, 2025 pm 12:42 PM
Bahasa apa yang ditulis Apache?
Apr 13, 2025 pm 12:42 PM
Apache ditulis dalam C. Bahasa ini menyediakan kelajuan, kestabilan, mudah alih, dan akses perkakasan langsung, menjadikannya sesuai untuk pembangunan pelayan web.
