

Pandas数据处理实例展示:全球上市公司数据整理
手头现在有一份福布斯2016年全球上市企业2000强排行榜的数据,但原始数据并不规范,需要处理后才能进一步使用。
本文通过实例操作来介绍用pandas进行数据整理。
照例先说下我的运行环境,如下:
windows 7, 64位
python 3.5
pandas 0.19.2版本
在拿到原始数据后,我们先来看看数据的情况,并思考下我们需要什么样的数据结果。
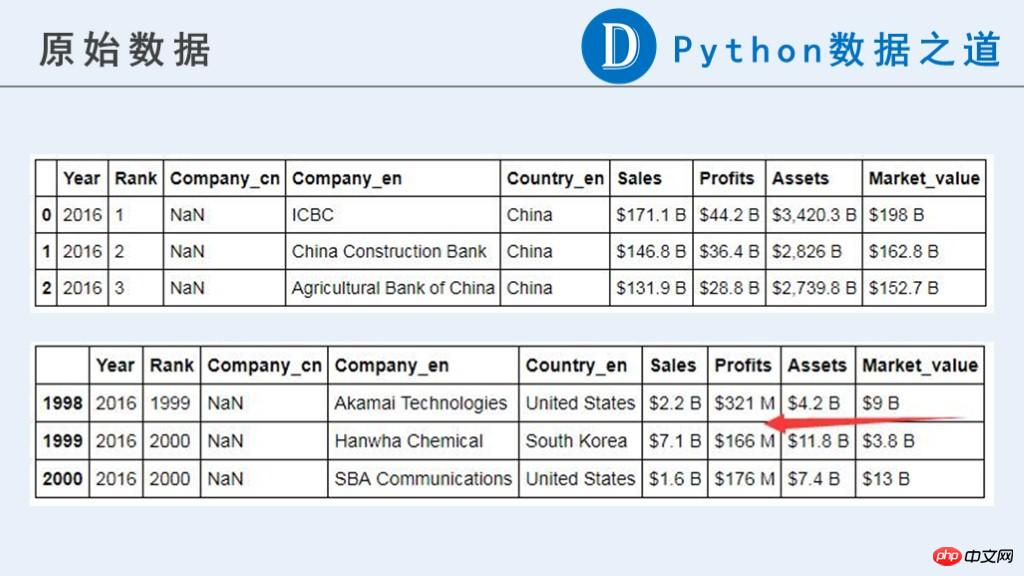
下面是原始数据:
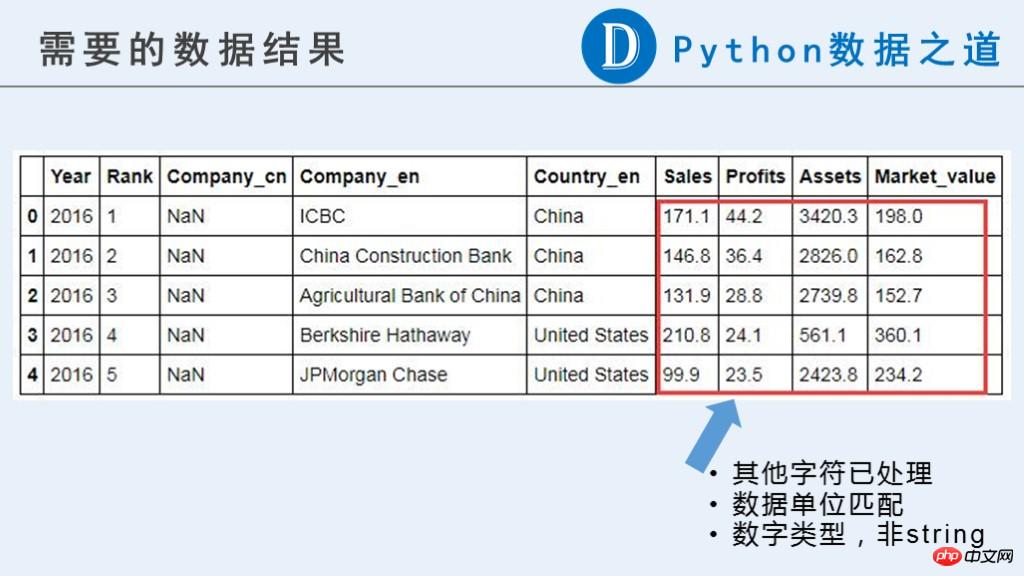
在本文中,我们需要以下的初步结果,以供以后继续使用。
可以看到,原始数据中,跟企业相关的数据中(“Sales”,“Profits”,“Assets”,“Market_value”),目前都是不是可以用来计算的数字类型。
原始内容中包含货币符号”$“,“-”,纯字母组成的字符串以及其他一些我们认为异常的信息。更重要的是,这些数据的单位并不一致。分别有以“B”(Billion,十亿)和“M”(Million,百万)表示的。在后续计算之前需要进行单位统一。
1 处理方法 Method-1
首先想到的处理思路就是将数据信息分别按十亿(’B’)和百万(‘M’)进行拆分,分别进行处理,最后在合并到一起。过程如下所示。
加载数据,并添加列的名称
import pandas as pd
df_2016 = pd.read_csv('data_2016.csv', encoding='gbk',header=None)# 更新列名df_2016.columns = ['Year', 'Rank', 'Company_cn','Company_en', 'Country_en', 'Sales', 'Profits', 'Assets', 'Market_value']
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head(3)获取单位为十亿(’B’)的数据
# 数据单位为 B的数据(Billion,十亿)df_2016_b = df_2016[df_2016['Sales'].str.endswith('B')]
print(df_2016_b.shape)
df_2016_b获取单位为百万(‘M’)的数据
# 数据单位为 M的数据(Million,百万)df_2016_m = df_2016[df_2016['Sales'].str.endswith('M')]
print(df_2016_m.shape)
df_2016_m这种方法理解起来比较简单,但操作起来会比较繁琐,尤其是如果有很多列数据需要处理的话,会花费很多时间。
进一步的处理,我这里就不描述了。当然,各位可以试试这个方法。
下面介绍稍微简单一点的方法。
2 处理方法 Method-2
2.1 加载数据
第一步还是加载数据,跟Method-1是一样的。
下面来处理’Sales’列
2.2 替换相关的异常字符
首先是替换相关的异常字符,包括美元的货币符号’$’,纯字母的字符串’undefined’,以及’B’。 这里,我们想统一把数据的单位整理成十亿,所以’B’可以直接进行替换。而’M’需要更多的处理步骤。
2.3 处理’M’相关的数据
处理含有百万“M”为单位的数据,即以“M”结尾的数据,思路如下:
(1)设定查找条件mask;
(2)替换字符串“M”为空值
(3)用pd.to_numeric()转换为数字
(4)除以1000,转换为十亿美元,与其他行的数据一致
上面两个步骤相关的代码如下:
# 替换美元符号df_2016['Sales'] = df_2016['Sales'].str.replace('$','')# # 查看异常值,均为字母(“undefined”)# df_2016[df_2016['Sales'].str.isalpha()]# 替换异常值“undefined”为空白# df_2016['Sales'] = df_2016['Sales'].str.replace('undefined','')df_2016['Sales'] = df_2016['Sales'].str.replace('^[A-Za-z]+$','')# 替换符号十亿美元“B”为空白,数字本身代表的就是十亿美元为单位df_2016['Sales'] = df_2016['Sales'].str.replace('B','')# 处理含有百万“M”为单位的数据,即以“M”结尾的数据# 思路:# (1)设定查找条件mask;# (2)替换字符串“M”为空值# (3)用pd.to_numeric()转换为数字# (4)除以1000,转换为十亿美元,与其他行的数据一致mask = df_2016['Sales'].str.endswith('M')
df_2016.loc[mask, 'Sales'] = pd.to_numeric(df_2016.loc[mask, 'Sales'].str.replace('M', ''))/1000df_2016['Sales'] = pd.to_numeric(df_2016['Sales'])
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head(3)用同样类似的方法处理其他列
可以看到,这个方法比第一种方法还是要方便很多。当然,这个方法针对DataFrame的每列数据都要进行相关的操作,如果列数多了,也还是比较繁琐的。
有没有更方便一点的方法呢。 答案是有的。
插播一条硬广:技术文章转发太多。文章来自微信公众号“Python数据之道”(ID:PyDataRoad)。
3 处理方法 Method-3
在Method-2的基础上,将处理方法写成更通用的数据处理函数,根据数据的结构,拓展更多的适用性,则可以比较方便的处理相关数据。
3.1 加载数据
第一步还是加载数据,跟Method-1是一样的。
3.2 编写数据处理的自定义函数
参考Method-2的处理过程,编写数据处理的自定义函数’pro_col’,并在Method-2的基础上拓展其他替换功能,使之适用于这四列数据(“Sales”,“Profits”,“Assets”,“Market_value”)。
函数编写的代码如下:
def pro_col(df, col): # 替换相关字符串,如有更多的替换情形,可以自行添加df[col] = df[col].str.replace('$','')
df[col] = df[col].str.replace('^[A-Za-z]+$','')
df[col] = df[col].str.replace('B','')# 注意这里是'-$',即以'-'结尾,而不是'-',因为有负数df[col] = df[col].str.replace('-$','')
df[col] = df[col].str.replace(',','')# 处理含有百万“M”为单位的数据,即以“M”结尾的数据# 思路:# (1)设定查找条件mask;# (2)替换字符串“M”为空值# (3)用pd.to_numeric()转换为数字# (4)除以1000,转换为十亿美元,与其他行的数据一致mask = df[col].str.endswith('M')
df.loc[mask, col] = pd.to_numeric(df.loc[mask, col].str.replace('M',''))/1000# 将字符型的数字转换为数字类型df[col] = pd.to_numeric(df[col])return df3.3 将自定义函数进行应用
针对DataFrame的每列,应用该自定义函数,进行数据处理,得到需要的结果。
pro_col(df_2016, 'Sales')
pro_col(df_2016, 'Profits')
pro_col(df_2016, 'Assets')
pro_col(df_2016, 'Market_value')
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head()当然,如果DataFrame的列数特别多,可以用for循环,这样代码更简洁。代码如下:
cols = ['Sales', 'Profits', 'Assets', 'Market_value']for col in cols:
pro_col(df_2016, col)
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
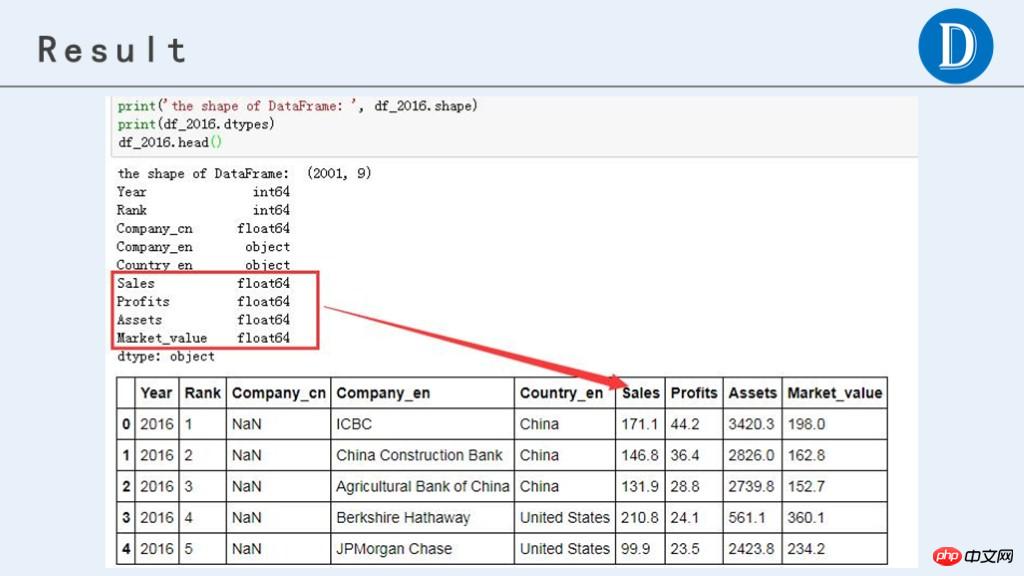
df_2016.head()最终处理后,获得的数据结果如下:
Atas ialah kandungan terperinci Pandas数据处理实例展示:全球上市公司数据整理. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Menyelesaikan masalah pemasangan panda biasa: tafsiran dan penyelesaian kepada ralat pemasangan
Feb 19, 2024 am 09:19 AM
Menyelesaikan masalah pemasangan panda biasa: tafsiran dan penyelesaian kepada ralat pemasangan
Feb 19, 2024 am 09:19 AM
Tutorial pemasangan Pandas: Analisis ralat pemasangan biasa dan penyelesaiannya, contoh kod khusus diperlukan Pengenalan: Pandas ialah alat analisis data yang berkuasa yang digunakan secara meluas dalam pembersihan data, pemprosesan data dan visualisasi data, jadi ia sangat dihormati dalam bidang sains data. Walau bagaimanapun, disebabkan oleh konfigurasi persekitaran dan isu pergantungan, anda mungkin menghadapi beberapa kesukaran dan ralat semasa memasang panda. Artikel ini akan memberi anda tutorial pemasangan panda dan menganalisis beberapa ralat pemasangan biasa serta penyelesaiannya. 1. Pasang panda
 Cara membaca fail txt dengan betul menggunakan panda
Jan 19, 2024 am 08:39 AM
Cara membaca fail txt dengan betul menggunakan panda
Jan 19, 2024 am 08:39 AM
Cara menggunakan panda untuk membaca fail txt dengan betul memerlukan contoh kod khusus Pandas ialah perpustakaan analisis data Python yang digunakan secara meluas. Ia boleh digunakan untuk memproses pelbagai jenis data, termasuk fail CSV, fail Excel, pangkalan data SQL, dll. Pada masa yang sama, ia juga boleh digunakan untuk membaca fail teks, seperti fail txt. Walau bagaimanapun, apabila membaca fail txt, kadangkala kami menghadapi beberapa masalah, seperti masalah pengekodan, masalah pembatas, dsb. Artikel ini akan memperkenalkan cara membaca txt dengan betul menggunakan panda
 Petua praktikal untuk membaca fail txt menggunakan panda
Jan 19, 2024 am 09:49 AM
Petua praktikal untuk membaca fail txt menggunakan panda
Jan 19, 2024 am 09:49 AM
Petua praktikal untuk membaca fail txt menggunakan panda, contoh kod khusus diperlukan Dalam analisis data dan pemprosesan data, fail txt ialah format data biasa. Menggunakan panda untuk membaca fail txt membolehkan pemprosesan data yang cepat dan mudah. Artikel ini akan memperkenalkan beberapa teknik praktikal untuk membantu anda menggunakan panda dengan lebih baik untuk membaca fail txt, bersama-sama dengan contoh kod tertentu. Baca fail txt dengan pembatas Apabila menggunakan panda untuk membaca fail txt dengan pembatas, anda boleh menggunakan read_c
 Mendedahkan kaedah penduaan data yang cekap dalam Pandas: Petua untuk mengalih keluar data pendua dengan cepat
Jan 24, 2024 am 08:12 AM
Mendedahkan kaedah penduaan data yang cekap dalam Pandas: Petua untuk mengalih keluar data pendua dengan cepat
Jan 24, 2024 am 08:12 AM
Rahsia kaedah deduplikasi Pandas: cara yang cepat dan cekap untuk menyahduplikasi data, yang memerlukan contoh kod khusus Dalam proses analisis dan pemprosesan data, duplikasi dalam data sering ditemui. Data pendua mungkin mengelirukan keputusan analisis, jadi penduaan adalah langkah yang sangat penting. Pandas, pustaka pemprosesan data yang berkuasa, menyediakan pelbagai kaedah untuk mencapai penyahduplikasian data Artikel ini akan memperkenalkan beberapa kaedah penyahduplikasian yang biasa digunakan, dan melampirkan contoh kod tertentu. Kes penduaan yang paling biasa berdasarkan satu lajur adalah berdasarkan sama ada nilai lajur tertentu diduakan.
 Tutorial pemasangan panda mudah: Panduan terperinci tentang cara memasang panda pada sistem pengendalian yang berbeza
Feb 21, 2024 pm 06:00 PM
Tutorial pemasangan panda mudah: Panduan terperinci tentang cara memasang panda pada sistem pengendalian yang berbeza
Feb 21, 2024 pm 06:00 PM
Tutorial pemasangan panda mudah: Panduan terperinci tentang cara memasang panda pada sistem pengendalian yang berbeza, contoh kod khusus diperlukan Memandangkan permintaan untuk pemprosesan dan analisis data terus meningkat, panda telah menjadi salah satu alat pilihan bagi ramai saintis data dan penganalisis. panda ialah pustaka pemprosesan dan analisis data yang berkuasa yang boleh memproses dan menganalisis sejumlah besar data berstruktur dengan mudah. Artikel ini akan memperincikan cara memasang panda pada sistem pengendalian yang berbeza dan memberikan contoh kod khusus. Pasang pada sistem pengendalian Windows
 Bagaimanakah Golang meningkatkan kecekapan pemprosesan data?
May 08, 2024 pm 06:03 PM
Bagaimanakah Golang meningkatkan kecekapan pemprosesan data?
May 08, 2024 pm 06:03 PM
Golang meningkatkan kecekapan pemprosesan data melalui konkurensi, pengurusan memori yang cekap, struktur data asli dan perpustakaan pihak ketiga yang kaya. Kelebihan khusus termasuk: Pemprosesan selari: Coroutine menyokong pelaksanaan berbilang tugas pada masa yang sama. Pengurusan memori yang cekap: Mekanisme kutipan sampah secara automatik menguruskan memori. Struktur data yang cekap: Struktur data seperti kepingan, peta dan saluran mengakses dan memproses data dengan pantas. Perpustakaan pihak ketiga: meliputi pelbagai perpustakaan pemprosesan data seperti fasthttp dan x/text.
 Gunakan Redis untuk meningkatkan kecekapan pemprosesan data aplikasi Laravel
Mar 06, 2024 pm 03:45 PM
Gunakan Redis untuk meningkatkan kecekapan pemprosesan data aplikasi Laravel
Mar 06, 2024 pm 03:45 PM
Gunakan Redis untuk meningkatkan kecekapan pemprosesan data aplikasi Laravel Dengan pembangunan berterusan aplikasi Internet, kecekapan pemprosesan data telah menjadi salah satu fokus pembangun. Apabila membangunkan aplikasi berdasarkan rangka kerja Laravel, kami boleh menggunakan Redis untuk meningkatkan kecekapan pemprosesan data dan mencapai capaian pantas dan caching data. Artikel ini akan memperkenalkan cara menggunakan Redis untuk pemprosesan data dalam aplikasi Laravel dan memberikan contoh kod khusus. 1. Pengenalan kepada Redis Redis ialah data dalam memori berprestasi tinggi
 Soalan Lazim untuk panda membaca fail txt
Jan 19, 2024 am 09:19 AM
Soalan Lazim untuk panda membaca fail txt
Jan 19, 2024 am 09:19 AM
Pandas ialah alat analisis data untuk Python, terutamanya sesuai untuk membersihkan, memproses dan menganalisis data. Semasa proses analisis data, kita selalunya perlu membaca fail data dalam pelbagai format, seperti fail Txt. Walau bagaimanapun, beberapa masalah akan dihadapi semasa operasi tertentu. Artikel ini akan memperkenalkan jawapan kepada soalan biasa tentang membaca fail txt dengan panda dan memberikan contoh kod yang sepadan. Soalan 1: Bagaimana untuk membaca fail txt? fail txt boleh dibaca menggunakan fungsi read_csv() panda. Ini kerana
