

RequireJs 源码剖析推出脚本加载的工作原理
引言
俗话说的好,不喜欢研究原理的程序员不是好的程序员,不喜欢读源码的程序员不是好的 jser。这两天看到了有关前端模块化的问题,才发现 JavaScript 社区为了前端工程化真是煞费苦心。今天研究了一天前端模块化的问题,先是大概了解了下模块化的标准规范,然后了解了一下 RequireJs 的语法和使用方法,最后研究了下 RequireJs 的设计模式和源码,所以想记录一下相关的心得,剖析一下模块加载的原理。
一、认识 RequireJs
在开始之前,我们需要了解前端模块化,本文不讨论有关前端模块化的问题,有关这方面的问题可以参考阮一峰的系列文章 Javascript 模块化编程。
使用 RequireJs 的第一步:前往官网 ;
第二步:下载文件;


第三步:在页面中引入 requirejs.js 并设置 main 函数;
1 <script type="text/javascript" src="scripts/require.js?1.1.11" data-main="scripts/main.js?1.1.11"></script>
然后我们就可以在 main.js 文件里编程了,requirejs 采用了 main 函数式的思想,一个文件即为一个模块,模块与模块之间可以依赖,也可以毫无干系。使用 requirejs ,我们在编程时就不必将所有模块都引入页面,而是需要一个模块,引入一个模块,就相当于 Java 当中的 import 一样。
定义模块:
1 //直接定义一个对象 2 define({ 3 color: "black", 4 size: "unisize" 5 }); 6 //通过函数返回一个对象,即可以实现 IIFE 7 define(function () { 8 //Do setup work here 9 10 return {11 color: "black",12 size: "unisize"13 }14 });15 //定义有依赖项的模块16 define(["./cart", "./inventory"], function(cart, inventory) {17 //return an object to define the "my/shirt" module.18 return {19 color: "blue",20 size: "large",21 addToCart: function() {22 inventory.decrement(this);23 cart.add(this);24 }25 }26 }27 );导入模块:
1 //导入一个模块2 require(['foo'], function(foo) {3 //do something4 });5 //导入多个模块6 require(['foo', 'bar'], function(foo, bar) {7 //do something8 });关于 requirejs 的使用,可以查看官网 API ,也可以参考 RequireJS 和 AMD 规范 ,本文暂不对 requirejs 的使用进行讲解。
二、main 函数入口
requirejs 的核心思想之一就是使用一个规定的函数入口,就像 C++ 的 int main(),Java 的 public static void main(),requirejs 的使用方式是把 main 函数缓存在 script 标签上。也就是将脚本文件的 url 缓存在 script 标签上。
1 <script type="text/javascript" src="scripts/require.js?1.1.11" data-main="scripts/main.js?1.1.11"></script>
初来乍到电脑同学一看,哇!script 标签难道还有什么不为人知的属性吗?吓得我赶紧打开了 W3C 查看相关 API,并为自己的 HTML 基础知识感到惭愧,可是遗憾的是 script 标签并没有相关的属性,甚至这都不是一个标准的属性,那么它到底是什么玩意呢?下面直接上一部分 requirejs 源码:
1 //Look for a data-main attribute to set main script for the page2 //to load. If it is there, the path to data main becomes the3 //baseUrl, if it is not already set.4 dataMain = script.getAttribute('data-main');实际上在 requirejs 中只是获取在 script 标签上缓存的数据,然后取出数据加载而已,也就是跟动态加载脚本是一样的,具体是怎么操作,在下面的讲解中会放出源码。
三、动态加载脚本
这一部分是整个 requirejs 的核心,我们知道在 Node.js 中加载模块的方式是同步的,这是因为在服务器端所有文件都存储在本地的硬盘上,传输速率快而且稳定。而换做了浏览器端,就不能这么干了,因为浏览器加载脚本会与服务器进行通信,这是一个未知的请求,如果使用同步的方式加载,就可能会一直阻塞下去。为了防止浏览器的阻塞,我们要使用异步的方式加载脚本。因为是异步加载,所以与模块相依赖的操作就必须得在脚本加载完成后执行,这里就得使用回调函数的形式。
我们知道,如果显示的在 HTML 中定义脚本文件,那么脚本的执行顺序是同步的,比如:
1 //module1.js2 console.log("module1");1 //module2.js2 console.log("module2");1 //module3.js2 console.log("module3");1 <script type="text/javascript" src="scripts/module/module1.js?1.1.11"></script>2 <script type="text/javascript" src="scripts/module/module2.js?1.1.11"></script>3 <script type="text/javascript" src="scripts/module/module3.js?1.1.11"></script>
那么在浏览器端总是会输出:

但是如果是动态加载脚本的话,脚本的执行顺序是异步的,而且不光是异步的,还是无序的:
1 //main.js 2 console.log("main start"); 3 4 var script1 = document.createElement("script"); 5 script1.src = "scripts/module/module1.js?1.1.11"; 6 document.head.appendChild(script1); 7 8 var script2 = document.createElement("script"); 9 script2.src = "scripts/module/module2.js?1.1.11";10 document.head.appendChild(script2);11 12 var script3 = document.createElement("script");13 script3.src = "scripts/module/module3.js?1.1.11";14 document.head.appendChild(script3);15 16 console.log("main end");使用这种方式加载脚本会造成脚本的无序加载,浏览器按照先来先运行的方法执行脚本,如果 module1.js 文件比较大,那么极其有可能会在 module2.js 和 module3.js 后执行,所以说这也是不可控的。要知道一个程序当中最大的 BUG 就是一个不可控的 BUG ,有时候它可能按顺序执行,有时候它可能乱序,这一定不是我们想要的。
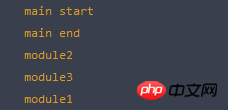
注意这里的还有一个重点是,"module" 的输出永远会在 "main end" 之后。这正是动态加载脚本异步性的特征,因为当前的脚本是一个 task ,而无论其他脚本的加载速度有多快,它都会在 Event Queue 的后面等待调度执行。这里涉及到一个关键的知识 — Event Loop ,如果你还对 JavaScript Event Loop 不了解,那么请先阅读这篇文章 深入理解 JavaScript 事件循环(一)— Event Loop。
四、导入模块原理
在上一小节,我们了解到,使用动态加载脚本的方式会使脚本无序执行,这一定是软件开发的噩梦,想象一下你的模块之间存在上下依赖的关系,而这时候他们的加载顺序是不可控的。动态加载同时也具有异步性,所以在 main.js 脚本文件中根本无法访问到模块文件中的任何变量。那么 requirejs 是如何解决这个问题的呢?我们知道在 requirejs 中,任何文件都是一个模块,一个模块也就是一个文件,包括主模块 main.js,下面我们看一段 requirejs 的源码:
1 /** 2 * Creates the node for the load command. Only used in browser envs. 3 */ 4 req.createNode = function (config, moduleName, url) { 5 var node = config.xhtml ? 6 document.createElementNS('http://www.w3.org/1999/xhtml', 'html:script') : 7 document.createElement('script'); 8 node.type = config.scriptType || 'text/javascript'; 9 node.charset = 'utf-8';10 node.async = true;11 return node;12 };在这段代码中我们可以看出, requirejs 导入模块的方式实际就是创建脚本标签,一切的模块都需要经过这个方法创建。那么 requirejs 又是如何处理异步加载的呢?传说江湖上最高深的医术不是什么灵丹妙药,而是以毒攻毒,requirejs 也深得其精髓,既然动态加载是异步的,那么我也用异步来对付你,使用 onload 事件来处理回调函数:
1 //In the browser so use a script tag 2 node = req.createNode(config, moduleName, url); 3 4 node.setAttribute('data-requirecontext', context.contextName); 5 node.setAttribute('data-requiremodule', moduleName); 6 7 //Set up load listener. Test attachEvent first because IE9 has 8 //a subtle issue in its addEventListener and script onload firings 9 //that do not match the behavior of all other browsers with10 //addEventListener support, which fire the onload event for a11 //script right after the script execution. See:12 //13 //UNFORTUNATELY Opera implements attachEvent but does not follow the script14 //script execution mode.15 if (node.attachEvent &&16 //Check if node.attachEvent is artificially added by custom script or17 //natively supported by browser18 //read 19 //if we can NOT find [native code] then it must NOT natively supported.20 //in IE8, node.attachEvent does not have toString()21 //Note the test for "[native code" with no closing brace, see:22 //23 !(node.attachEvent.toString && node.attachEvent.toString().indexOf('[native code') < 0) &&24 !isOpera) {25 //Probably IE. IE (at least 6-8) do not fire26 //script onload right after executing the script, so27 //we cannot tie the anonymous define call to a name.28 //However, IE reports the script as being in 'interactive'29 //readyState at the time of the define call.30 useInteractive = true;31 32 node.attachEvent('onreadystatechange', context.onScriptLoad);33 //It would be great to add an error handler here to catch34 //404s in IE9+. However, onreadystatechange will fire before35 //the error handler, so that does not help. If addEventListener36 //is used, then IE will fire error before load, but we cannot37 //use that pathway given the connect.microsoft.com issue38 //mentioned above about not doing the 'script execute,39 //then fire the script load event listener before execute40 //next script' that other browsers do.41 //Best hope: IE10 fixes the issues,42 //and then destroys all installs of IE 6-9.43 //node.attachEvent('onerror', context.onScriptError);44 } else {45 node.addEventListener('load', context.onScriptLoad, false);46 node.addEventListener('error', context.onScriptError, false);47 }48 node.src = url;注意在这段源码当中的监听事件,既然动态加载脚本是异步的的,那么干脆使用 onload 事件来处理回调函数,这样就保证了在我们的程序执行前依赖的模块一定会提前加载完成。因为在事件队列里, onload 事件是在脚本加载完成之后触发的,也就是在事件队列里面永远处在依赖模块的后面,例如我们执行:
1 require(["module"], function (module) {2 //do something3 });那么在事件队列里面的相对顺序会是这样:

相信细心的同学可能会注意到了,在源码当中不光光有 onload 事件,同时还添加了一个 onerror 事件,我们在使用 requirejs 的时候也可以定义一个模块加载失败的处理函数,这个函数在底层也就对应了 onerror 事件。同理,其和 onload 事件一样是一个异步的事件,同时也永远发生在模块加载之后。
谈到这里 requirejs 的核心模块思想也就一目了然了,不过其中的过程还远不直这些,博主只是将模块加载的实现思想抛了出来,但 requirejs 的具体实现还要复杂的多,比如我们定义模块的时候可以导入依赖模块,导入模块的时候还可以导入多个依赖,具体的实现方法我就没有深究过了, requirejs 虽然不大,但是源码也是有两千多行的... ...但是只要理解了动态加载脚本的原理过后,其思想也就不难理解了,比如我现在就可以想到一个简单的实现多个模块依赖的方法,使用计数的方式检查模块是否加载完全:
1 function myRequire(deps, callback){ 2 //记录模块加载数量 3 var ready = 0; 4 //创建脚本标签 5 function load (url) { 6 var script = document.createElement("script"); 7 script.type = 'text/javascript'; 8 script.async = true; 9 script.src = url;10 return script;11 }12 var nodes = [];13 for (var i = deps.length - 1; i >= 0; i--) {14 nodes.push(load(deps[i]));15 }16 //加载脚本17 for (var i = nodes.length - 1; i >= 0; i--) {18 nodes[i].addEventListener("load", function(event){19 ready++;20 //如果所有依赖脚本加载完成,则执行回调函数;21 if(ready === nodes.length){22 callback()23 }24 }, false);25 document.head.appendChild(nodes[i]);26 }27 }实验一下是否能够工作:
1 myRequire(["module/module1.js?1.1.11", "module/module2.js?1.1.11", "module/module3.js?1.1.11"], function(){2 console.log("ready!");3 }); 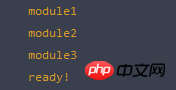
Yes, it's work!
总结
requirejs 加载模块的核心思想是利用了动态加载脚本的异步性以及 onload 事件以毒攻毒,关于脚本的加载,我们需要注意一下几点:
在 HTML 中引入

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik
AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.
Undress AI Tool
Gambar buka pakaian secara percuma
Clothoff.io
Penyingkiran pakaian AI
AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
R.E.P.O. Kristal tenaga dijelaskan dan apa yang mereka lakukan (kristal kuning)3 minggu yang lalu By 尊渡假赌尊渡假赌尊渡假赌R.E.P.O. Tetapan grafik terbaik3 minggu yang lalu By 尊渡假赌尊渡假赌尊渡假赌Assassin's Creed Shadows: Penyelesaian Riddle Seashell2 minggu yang lalu By DDDR.E.P.O. Cara Memperbaiki Audio Jika anda tidak dapat mendengar sesiapa3 minggu yang lalu By 尊渡假赌尊渡假赌尊渡假赌WWE 2K25: Cara Membuka Segala -galanya Di Myrise3 minggu yang lalu By 尊渡假赌尊渡假赌尊渡假赌
Alat panas
Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma
SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan
Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa
Dreamweaver CS6
Alat pembangunan web visual
SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
Tutorial CakePHP 1376
1376
 52
52











![Ralat memuatkan pemalam dalam Illustrator [Tetap]](https://img.php.cn/upload/article/000/465/014/170831522770626.jpg?x-oss-process=image/resize,m_fill,h_207,w_330) Ralat memuatkan pemalam dalam Illustrator [Tetap]
Feb 19, 2024 pm 12:00 PM
Ralat memuatkan pemalam dalam Illustrator [Tetap]
Feb 19, 2024 pm 12:00 PM
Apabila memulakan Adobe Illustrator, adakah mesej tentang ralat memuatkan pemalam timbul? Sesetengah pengguna Illustrator telah mengalami ralat ini semasa membuka aplikasi. Mesej itu diikuti dengan senarai pemalam yang bermasalah. Mesej ralat ini menunjukkan bahawa terdapat masalah dengan pemalam yang dipasang, tetapi ia juga mungkin disebabkan oleh sebab lain seperti fail Visual C++ DLL yang rosak atau fail pilihan yang rosak. Jika anda menghadapi ralat ini, kami akan membimbing anda dalam artikel ini untuk menyelesaikan masalah, jadi teruskan membaca di bawah. Ralat memuatkan pemalam dalam Illustrator Jika anda menerima mesej ralat "Ralat memuatkan pemalam" semasa cuba melancarkan Adobe Illustrator, anda boleh menggunakan yang berikut: Sebagai pentadbir
 Bagaimana untuk melaksanakan sistem pengecaman pertuturan dalam talian menggunakan WebSocket dan JavaScript
Dec 17, 2023 pm 02:54 PM
Bagaimana untuk melaksanakan sistem pengecaman pertuturan dalam talian menggunakan WebSocket dan JavaScript
Dec 17, 2023 pm 02:54 PM
Cara menggunakan WebSocket dan JavaScript untuk melaksanakan sistem pengecaman pertuturan dalam talian Pengenalan: Dengan perkembangan teknologi yang berterusan, teknologi pengecaman pertuturan telah menjadi bahagian penting dalam bidang kecerdasan buatan. Sistem pengecaman pertuturan dalam talian berdasarkan WebSocket dan JavaScript mempunyai ciri kependaman rendah, masa nyata dan platform merentas, dan telah menjadi penyelesaian yang digunakan secara meluas. Artikel ini akan memperkenalkan cara menggunakan WebSocket dan JavaScript untuk melaksanakan sistem pengecaman pertuturan dalam talian.
 Sari kata Stremio tidak berfungsi; ralat memuatkan sari kata
Feb 24, 2024 am 09:50 AM
Sari kata Stremio tidak berfungsi; ralat memuatkan sari kata
Feb 24, 2024 am 09:50 AM
Sarikata tidak berfungsi pada Stremio pada PC Windows anda? Sesetengah pengguna Stremio melaporkan bahawa sari kata tidak dipaparkan dalam video. Ramai pengguna melaporkan mengalami mesej ralat yang mengatakan "Ralat memuatkan sari kata." Berikut ialah mesej ralat penuh yang muncul dengan ralat ini: Ralat berlaku semasa memuatkan sari kata Gagal memuatkan sari kata: Ini mungkin masalah dengan pemalam yang anda gunakan atau rangkaian anda. Seperti yang dikatakan oleh mesej ralat, mungkin sambungan internet anda yang menyebabkan ralat. Jadi sila semak sambungan rangkaian anda dan pastikan internet anda berfungsi dengan baik. Selain itu, mungkin terdapat sebab lain di sebalik ralat ini, termasuk sarikata yang bercanggah, sari kata yang tidak disokong untuk kandungan video tertentu dan apl Stremio yang sudah lapuk. suka
 WebSocket dan JavaScript: teknologi utama untuk melaksanakan sistem pemantauan masa nyata
Dec 17, 2023 pm 05:30 PM
WebSocket dan JavaScript: teknologi utama untuk melaksanakan sistem pemantauan masa nyata
Dec 17, 2023 pm 05:30 PM
WebSocket dan JavaScript: Teknologi utama untuk merealisasikan sistem pemantauan masa nyata Pengenalan: Dengan perkembangan pesat teknologi Internet, sistem pemantauan masa nyata telah digunakan secara meluas dalam pelbagai bidang. Salah satu teknologi utama untuk mencapai pemantauan masa nyata ialah gabungan WebSocket dan JavaScript. Artikel ini akan memperkenalkan aplikasi WebSocket dan JavaScript dalam sistem pemantauan masa nyata, memberikan contoh kod dan menerangkan prinsip pelaksanaannya secara terperinci. 1. Teknologi WebSocket
 Bagaimana untuk melaksanakan sistem tempahan dalam talian menggunakan WebSocket dan JavaScript
Dec 17, 2023 am 09:39 AM
Bagaimana untuk melaksanakan sistem tempahan dalam talian menggunakan WebSocket dan JavaScript
Dec 17, 2023 am 09:39 AM
Cara menggunakan WebSocket dan JavaScript untuk melaksanakan sistem tempahan dalam talian Dalam era digital hari ini, semakin banyak perniagaan dan perkhidmatan perlu menyediakan fungsi tempahan dalam talian. Adalah penting untuk melaksanakan sistem tempahan dalam talian yang cekap dan masa nyata. Artikel ini akan memperkenalkan cara menggunakan WebSocket dan JavaScript untuk melaksanakan sistem tempahan dalam talian dan memberikan contoh kod khusus. 1. Apakah itu WebSocket? WebSocket ialah kaedah dupleks penuh pada sambungan TCP tunggal.
 Cara menggunakan JavaScript dan WebSocket untuk melaksanakan sistem pesanan dalam talian masa nyata
Dec 17, 2023 pm 12:09 PM
Cara menggunakan JavaScript dan WebSocket untuk melaksanakan sistem pesanan dalam talian masa nyata
Dec 17, 2023 pm 12:09 PM
Pengenalan kepada cara menggunakan JavaScript dan WebSocket untuk melaksanakan sistem pesanan dalam talian masa nyata: Dengan populariti Internet dan kemajuan teknologi, semakin banyak restoran telah mula menyediakan perkhidmatan pesanan dalam talian. Untuk melaksanakan sistem pesanan dalam talian masa nyata, kami boleh menggunakan teknologi JavaScript dan WebSocket. WebSocket ialah protokol komunikasi dupleks penuh berdasarkan protokol TCP, yang boleh merealisasikan komunikasi dua hala masa nyata antara pelanggan dan pelayan. Dalam sistem pesanan dalam talian masa nyata, apabila pengguna memilih hidangan dan membuat pesanan
 Outlook membeku apabila memasukkan hiperpautan
Feb 19, 2024 pm 03:00 PM
Outlook membeku apabila memasukkan hiperpautan
Feb 19, 2024 pm 03:00 PM
Jika anda menghadapi isu beku semasa memasukkan hiperpautan ke dalam Outlook, ia mungkin disebabkan oleh sambungan rangkaian yang tidak stabil, versi Outlook lama, gangguan daripada perisian antivirus atau konflik tambahan. Faktor-faktor ini boleh menyebabkan Outlook gagal mengendalikan operasi hiperpautan dengan betul. Betulkan Outlook terhenti apabila memasukkan hiperpautan Gunakan pembetulan berikut untuk membetulkan Outlook terhenti apabila memasukkan hiperpautan: Semak alat tambah yang dipasang Kemas kini Outlook Lumpuhkan sementara perisian antivirus anda dan kemudian cuba buat profil pengguna baharu Betulkan apl Office Program Nyahpasang dan pasang semula Office Mari mulakan. 1] Semak add-in yang dipasang Mungkin add-in yang dipasang dalam Outlook menyebabkan masalah.
 JavaScript dan WebSocket: Membina sistem ramalan cuaca masa nyata yang cekap
Dec 17, 2023 pm 05:13 PM
JavaScript dan WebSocket: Membina sistem ramalan cuaca masa nyata yang cekap
Dec 17, 2023 pm 05:13 PM
JavaScript dan WebSocket: Membina sistem ramalan cuaca masa nyata yang cekap Pengenalan: Hari ini, ketepatan ramalan cuaca sangat penting kepada kehidupan harian dan membuat keputusan. Apabila teknologi berkembang, kami boleh menyediakan ramalan cuaca yang lebih tepat dan boleh dipercayai dengan mendapatkan data cuaca dalam masa nyata. Dalam artikel ini, kita akan mempelajari cara menggunakan teknologi JavaScript dan WebSocket untuk membina sistem ramalan cuaca masa nyata yang cekap. Artikel ini akan menunjukkan proses pelaksanaan melalui contoh kod tertentu. Kami
