

Python: Pandas如何高效运算的方法
本文就Pandas的运行效率作一个对比的测试,来探讨用哪些方式,会使得运行效率较好。
测试环境如下:
windows 7, 64位
python 3.5
pandas 0.19.2
numpy 1.11.3
jupyter notebook
需要说明的是,不同的系统,不同的电脑配置,不同的软件环境,运行结果可能有些差异。就算是同一台电脑,每次运行时,运行结果也不完全一样。
1 测试内容
测试的内容为,分别用三种方法来计算一个简单的运算过程,即 a*a+b*b 。
三种方法分别是:
python的for循环
Pandas的Series
Numpy的ndarray
首先构造一个DataFrame,数据量的大小,即DataFrame的行数,分别为10, 100, 1000, … ,直到10,000,000(一千万)。
然后在jupyter notebook中,用下面的代码分别去测试,来查看不同方法下的运行时间,做一个对比。
import pandas as pdimport numpy as np# 100分别用 10,100,...,10,000,000来替换运行list_a = list(range(100))# 200分别用 20,200,...,20,000,000来替换运行list_b = list(range(100,200))
print(len(list_a))
print(len(list_b))
df = pd.DataFrame({'a':list_a, 'b':list_b})
print('数据维度为:{}'.format(df.shape))
print(len(df))
print(df.head())100 100 数据维度为:(100, 2) 100 a b 0 0 100 1 1 101 2 2 102 3 3 103 4 4 104
执行运算, a*a + b*b
Method 1: for循环
%%timeit# 当DataFrame的行数大于等于1000000时,请用 %%time 命令for i in range(len(df)): df['a'][i]*df['a'][i]+df['b'][i]*df['b'][i]
100 loops, best of 3: 12.8 ms per loop
Method 2: Series
type(df['a'])
pandas.core.series.Series
%%timeit df['a']*df['a']+df['b']*df['b']
The slowest run took 5.41 times longer than the fastest. This could mean that an intermediate result is being cached. 1000 loops, best of 3: 669 µs per loop
Method 3: ndarray
type(df['a'].values)
numpy.ndarray
%%timeit df['a'].values*df['a'].values+df['b'].values*df['b'].values
10000 loops, best of 3: 34.2 µs per loop
2 测试结果
运行结果如下:
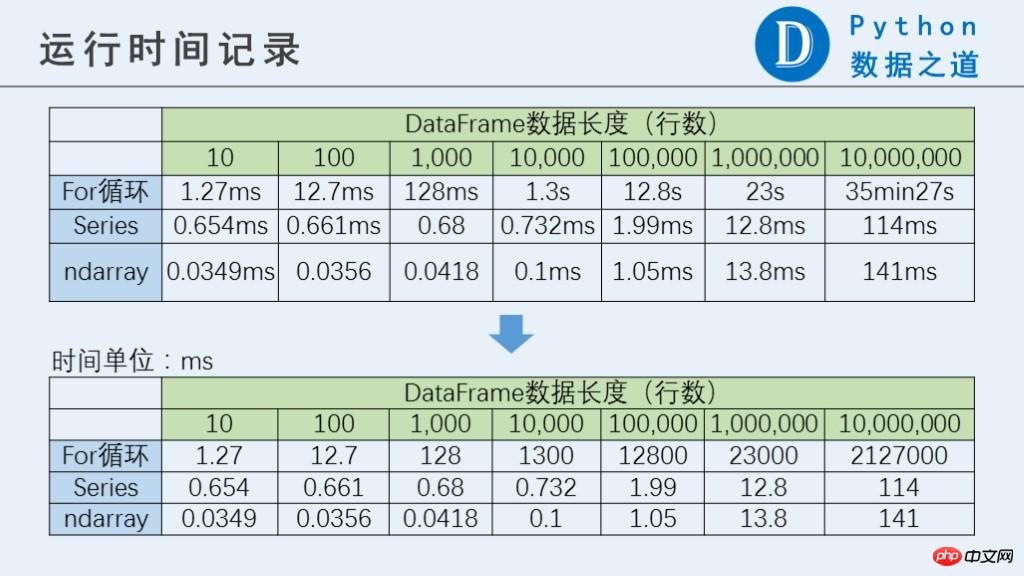
从运行结果可以看出,for循环明显比Series和ndarray要慢很多,并且数据量越大,差异越明显。当数据量达到一千万行时,for循环的表现也差一万倍以上。 而Series和ndarray之间的差异则没有那么大。
PS: 1000万行时,for循环运行耗时特别长,各位如果要测试,需要注意下,请用 %%time 命令(只测试一次)。
下面通过图表来对比下Series和ndarray之间的表现。
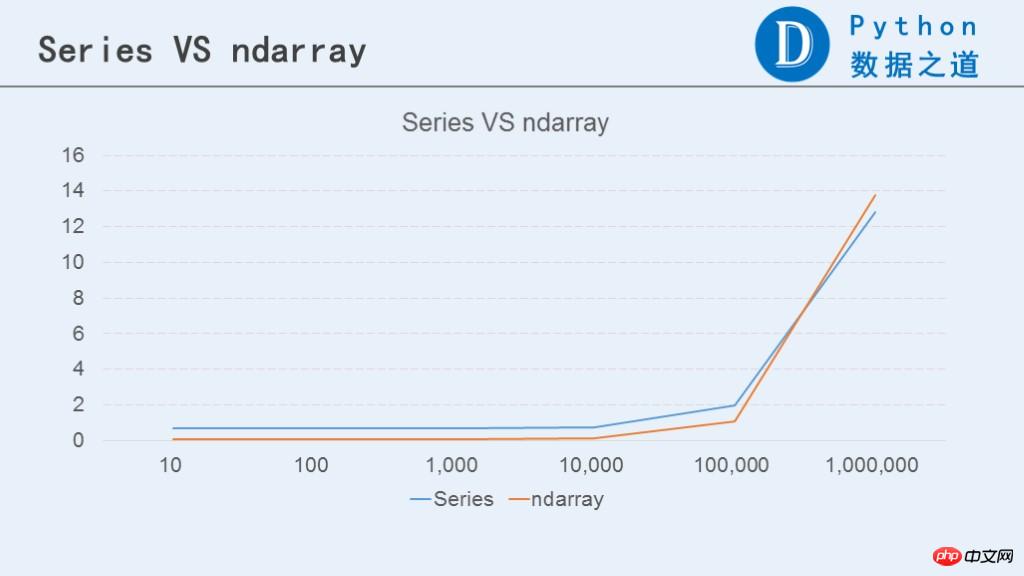
从上图可以看出,当数据小于10万行时,ndarray的表现要比Series好些。而当数据行数大于100万行时,Series的表现要稍微好于ndarray。当然,两者的差异不是特别明显。
所以一般情况下,个人建议,for循环,能不用则不用,而当数量不是特别大时,建议使用ndarray(即df[‘col’].values)来进行计算,运行效率相对来说要好些。
Atas ialah kandungan terperinci Python: Pandas如何高效运算的方法. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1385
1385
 52
52

 PHP dan Python: Contoh dan perbandingan kod
Apr 15, 2025 am 12:07 AM
PHP dan Python: Contoh dan perbandingan kod
Apr 15, 2025 am 12:07 AM
PHP dan Python mempunyai kelebihan dan kekurangan mereka sendiri, dan pilihannya bergantung kepada keperluan projek dan keutamaan peribadi. 1.PHP sesuai untuk pembangunan pesat dan penyelenggaraan aplikasi web berskala besar. 2. Python menguasai bidang sains data dan pembelajaran mesin.
 Python vs JavaScript: Komuniti, Perpustakaan, dan Sumber
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: Komuniti, Perpustakaan, dan Sumber
Apr 15, 2025 am 12:16 AM
Python dan JavaScript mempunyai kelebihan dan kekurangan mereka sendiri dari segi komuniti, perpustakaan dan sumber. 1) Komuniti Python mesra dan sesuai untuk pemula, tetapi sumber pembangunan depan tidak kaya dengan JavaScript. 2) Python berkuasa dalam bidang sains data dan perpustakaan pembelajaran mesin, sementara JavaScript lebih baik dalam perpustakaan pembangunan dan kerangka pembangunan depan. 3) Kedua -duanya mempunyai sumber pembelajaran yang kaya, tetapi Python sesuai untuk memulakan dengan dokumen rasmi, sementara JavaScript lebih baik dengan MDNWebDocs. Pilihan harus berdasarkan keperluan projek dan kepentingan peribadi.
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 Cara menjalankan program di terminal vscode
Apr 15, 2025 pm 06:42 PM
Cara menjalankan program di terminal vscode
Apr 15, 2025 pm 06:42 PM
Dalam kod VS, anda boleh menjalankan program di terminal melalui langkah -langkah berikut: Sediakan kod dan buka terminal bersepadu untuk memastikan bahawa direktori kod selaras dengan direktori kerja terminal. Pilih arahan Run mengikut bahasa pengaturcaraan (seperti python python your_file_name.py) untuk memeriksa sama ada ia berjalan dengan jayanya dan menyelesaikan kesilapan. Gunakan debugger untuk meningkatkan kecekapan debug.
 Python: Automasi, skrip, dan pengurusan tugas
Apr 16, 2025 am 12:14 AM
Python: Automasi, skrip, dan pengurusan tugas
Apr 16, 2025 am 12:14 AM
Python cemerlang dalam automasi, skrip, dan pengurusan tugas. 1) Automasi: Sandaran fail direalisasikan melalui perpustakaan standard seperti OS dan Shutil. 2) Penulisan Skrip: Gunakan Perpustakaan Psutil untuk memantau sumber sistem. 3) Pengurusan Tugas: Gunakan perpustakaan jadual untuk menjadualkan tugas. Kemudahan penggunaan Python dan sokongan perpustakaan yang kaya menjadikannya alat pilihan di kawasan ini.
 Apa itu vscode untuk apa vscode?
Apr 15, 2025 pm 06:45 PM
Apa itu vscode untuk apa vscode?
Apr 15, 2025 pm 06:45 PM
VS Kod adalah nama penuh Visual Studio Code, yang merupakan editor kod dan persekitaran pembangunan yang dibangunkan oleh Microsoft. Ia menyokong pelbagai bahasa pengaturcaraan dan menyediakan penonjolan sintaks, penyiapan automatik kod, coretan kod dan arahan pintar untuk meningkatkan kecekapan pembangunan. Melalui ekosistem lanjutan yang kaya, pengguna boleh menambah sambungan kepada keperluan dan bahasa tertentu, seperti debuggers, alat pemformatan kod, dan integrasi Git. VS Kod juga termasuk debugger intuitif yang membantu dengan cepat mencari dan menyelesaikan pepijat dalam kod anda.
 Adakah sambungan vscode berniat jahat?
Apr 15, 2025 pm 07:57 PM
Adakah sambungan vscode berniat jahat?
Apr 15, 2025 pm 07:57 PM
Sambungan kod VS menimbulkan risiko yang berniat jahat, seperti menyembunyikan kod jahat, mengeksploitasi kelemahan, dan melancap sebagai sambungan yang sah. Kaedah untuk mengenal pasti sambungan yang berniat jahat termasuk: memeriksa penerbit, membaca komen, memeriksa kod, dan memasang dengan berhati -hati. Langkah -langkah keselamatan juga termasuk: kesedaran keselamatan, tabiat yang baik, kemas kini tetap dan perisian antivirus.
 Cara Memasang Nginx di CentOs
Apr 14, 2025 pm 08:06 PM
Cara Memasang Nginx di CentOs
Apr 14, 2025 pm 08:06 PM
CentOS Memasang Nginx memerlukan mengikuti langkah-langkah berikut: memasang kebergantungan seperti alat pembangunan, pcre-devel, dan openssl-devel. Muat turun Pakej Kod Sumber Nginx, unzip dan menyusun dan memasangnya, dan tentukan laluan pemasangan sebagai/usr/local/nginx. Buat pengguna Nginx dan kumpulan pengguna dan tetapkan kebenaran. Ubah suai fail konfigurasi nginx.conf, dan konfigurasikan port pendengaran dan nama domain/alamat IP. Mulakan perkhidmatan Nginx. Kesalahan biasa perlu diberi perhatian, seperti isu ketergantungan, konflik pelabuhan, dan kesilapan fail konfigurasi. Pengoptimuman prestasi perlu diselaraskan mengikut keadaan tertentu, seperti menghidupkan cache dan menyesuaikan bilangan proses pekerja.
