

python爬取文章实例教程
这篇文章主要跟大家介绍了利用python爬取散文网文章的相关资料,文中介绍的非常详细,对大家具有一定的参考学习价值,需要的朋友们下面来一起看看吧。
本文主要给大家介绍的是关于python爬取散文网文章的相关内容,分享出来供大家参考学习,下面一起来看看详细的介绍:
效果图如下:

配置python 2.7
bs4 requests
安装 用pip进行安装 sudo pip install bs4
sudo pip install requests
简要说明一下bs4的使用因为是爬取网页 所以就介绍find 跟find_all
find跟find_all的不同在于返回的东西不同 find返回的是匹配到的第一个标签及标签里的内容
find_all返回的是一个列表
比如我们写一个test.html 用来测试find跟find_all的区别。
内容是:
<html> <head> </head> <body> <p id="one"><a></a></p> <p id="two"><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >abc</a></p> <p id="three"><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >three a</a><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >three a</a><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >three a</a></p> <p id="four"><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >four<p>four p</p><p>four p</p><p>four p</p> a</a></p> </body> </html>
然后test.py的代码为:
from bs4 import BeautifulSoup import lxml if __name__=='__main__': s = BeautifulSoup(open('test.html'),'lxml') print s.prettify() print "------------------------------" print s.find('p') print s.find_all('p') print "------------------------------" print s.find('p',id='one') print s.find_all('p',id='one') print "------------------------------" print s.find('p',id="two") print s.find_all('p',id="two") print "------------------------------" print s.find('p',id="three") print s.find_all('p',id="three") print "------------------------------" print s.find('p',id="four") print s.find_all('p',id="four") print "------------------------------"
运行以后我们可以看到结果当获取指定标签时候两者区别不大当获取一组标签的时候两者的区别就会显示出来
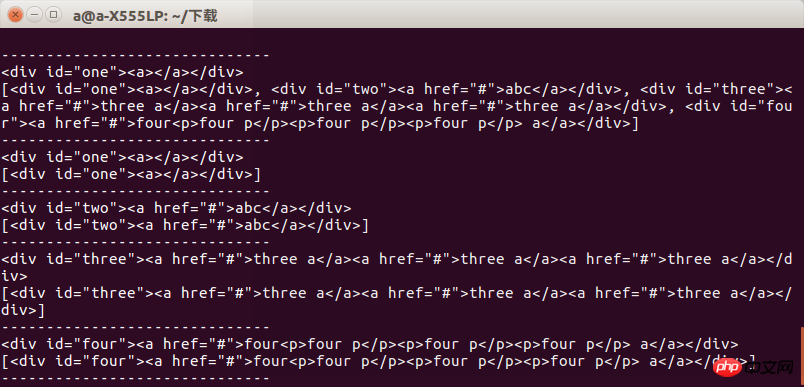
所以我们在使用时候要注意到底要的是什么,否则会出现报错
接下来就是通过requests 获取网页信息了,我不太懂别人为什么要写heard跟其他的东西
我直接进行网页访问,通过get方式获取散文网几个分类的二级网页然后通过一个组的测试,把所有的网页爬取一遍
def get_html():
url = "https://www.sanwen.net/"
two_html = ['sanwen','shige','zawen','suibi','rizhi','novel']
for doc in two_html:
i=1
if doc=='sanwen':
print "running sanwen -----------------------------"
if doc=='shige':
print "running shige ------------------------------"
if doc=='zawen':
print 'running zawen -------------------------------'
if doc=='suibi':
print 'running suibi -------------------------------'
if doc=='rizhi':
print 'running ruzhi -------------------------------'
if doc=='nove':
print 'running xiaoxiaoshuo -------------------------'
while(i<10):
par = {'p':i}
res = requests.get(url+doc+'/',params=par)
if res.status_code==200:
soup(res.text)
i+=i这部分的代码中我没有对res.status_code不是200的进行处理,导致的问题是会不显示错误,爬取的内容会有丢失。然后分析散文网的网页,发现是www.sanwen.net/rizhi/&p=1
p最大值是10这个不太懂,上次爬盘多多是100页,算了算了以后再分析。然后就通过get方法获取每页的内容。
获取每页内容以后就是分析作者跟题目了代码是这样的
def soup(html_text): s = BeautifulSoup(html_text,'lxml') link = s.find('p',class_='categorylist').find_all('li') for i in link: if i!=s.find('li',class_='page'): title = i.find_all('a')[1] author = i.find_all('a')[2].text url = title.attrs['href'] sign = re.compile(r'(//)|/') match = sign.search(title.text) file_name = title.text if match: file_name = sign.sub('a',str(title.text))
获取标题的时候出现坑爹的事,请问大佬们写散文你标题加斜杠干嘛,不光加一个还有加两个的,这个问题直接导致我后面写入文件的时候文件名出现错误,于是写正则表达式,我给你改行了吧。
最后就是获取散文内容了,通过每页的分析,获得文章地址,然后直接获取内容,本来还想直接通过改网页地址一个一个的获得呢,这样也省事了。
def get_content(url): res = requests.get('https://www.sanwen.net'+url) if res.status_code==200: soup = BeautifulSoup(res.text,'lxml') contents = soup.find('p',class_='content').find_all('p') content = '' for i in contents: content+=i.text+'\n' return content
最后就是写入文件保存ok
f = open(file_name+'.txt','w') print 'running w txt'+file_name+'.txt' f.write(title.text+'\n') f.write(author+'\n') content=get_content(url) f.write(content) f.close()
三个函数获取散文网的散文,不过有问题,问题在于不知道为什么有些散文丢失了我只能获取到大概400多篇文章,这跟散文网的文章是差很多很多的,但是确实是一页一页的获取来的,这个问题希望大佬帮忙看看。可能应该做网页无法访问的处理,当然我觉得跟我宿舍这个破网有关系
f = open(file_name+'.txt','w') print 'running w txt'+file_name+'.txt' f.write(title.text+'\n') f.write(author+'\n') content=get_content(url) f.write(content) f.close()
差点忘了效果图
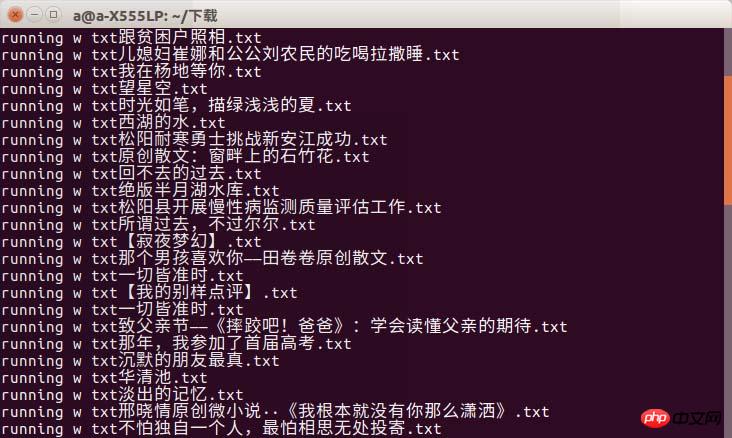
能会出现timeout现象吧,只能说上大学一定要选网好的啊!
Atas ialah kandungan terperinci python爬取文章实例教程. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Rancangan Python 2 jam: Pendekatan yang realistik
Apr 11, 2025 am 12:04 AM
Rancangan Python 2 jam: Pendekatan yang realistik
Apr 11, 2025 am 12:04 AM
Anda boleh mempelajari konsep pengaturcaraan asas dan kemahiran Python dalam masa 2 jam. 1. Belajar Pembolehubah dan Jenis Data, 2.
 Python: meneroka aplikasi utamanya
Apr 10, 2025 am 09:41 AM
Python: meneroka aplikasi utamanya
Apr 10, 2025 am 09:41 AM
Python digunakan secara meluas dalam bidang pembangunan web, sains data, pembelajaran mesin, automasi dan skrip. 1) Dalam pembangunan web, kerangka Django dan Flask memudahkan proses pembangunan. 2) Dalam bidang sains data dan pembelajaran mesin, numpy, panda, scikit-learn dan perpustakaan tensorflow memberikan sokongan yang kuat. 3) Dari segi automasi dan skrip, Python sesuai untuk tugas -tugas seperti ujian automatik dan pengurusan sistem.
 Kaedah Navicat untuk melihat kata laluan pangkalan data MongoDB
Apr 08, 2025 pm 09:39 PM
Kaedah Navicat untuk melihat kata laluan pangkalan data MongoDB
Apr 08, 2025 pm 09:39 PM
Tidak mustahil untuk melihat kata laluan MongoDB secara langsung melalui Navicat kerana ia disimpan sebagai nilai hash. Cara mendapatkan kata laluan yang hilang: 1. Tetapkan semula kata laluan; 2. Periksa fail konfigurasi (mungkin mengandungi nilai hash); 3. Semak Kod (boleh kata laluan Hardcode).
 Cara Menggunakan AWS Glue Crawler dengan Amazon Athena
Apr 09, 2025 pm 03:09 PM
Cara Menggunakan AWS Glue Crawler dengan Amazon Athena
Apr 09, 2025 pm 03:09 PM
Sebagai profesional data, anda perlu memproses sejumlah besar data dari pelbagai sumber. Ini boleh menimbulkan cabaran kepada pengurusan data dan analisis. Nasib baik, dua perkhidmatan AWS dapat membantu: AWS Glue dan Amazon Athena.
 Cara memulakan pelayan dengan redis
Apr 10, 2025 pm 08:12 PM
Cara memulakan pelayan dengan redis
Apr 10, 2025 pm 08:12 PM
Langkah -langkah untuk memulakan pelayan Redis termasuk: Pasang Redis mengikut sistem operasi. Mulakan perkhidmatan Redis melalui Redis-server (Linux/macOS) atau redis-server.exe (Windows). Gunakan redis-cli ping (linux/macOS) atau redis-cli.exe ping (windows) perintah untuk memeriksa status perkhidmatan. Gunakan klien Redis, seperti redis-cli, python, atau node.js untuk mengakses pelayan.
 Cara Membaca Gilir Redis
Apr 10, 2025 pm 10:12 PM
Cara Membaca Gilir Redis
Apr 10, 2025 pm 10:12 PM
Untuk membaca giliran dari Redis, anda perlu mendapatkan nama giliran, membaca unsur -unsur menggunakan arahan LPOP, dan memproses barisan kosong. Langkah-langkah khusus adalah seperti berikut: Dapatkan nama giliran: Namakannya dengan awalan "giliran:" seperti "giliran: my-queue". Gunakan arahan LPOP: Keluarkan elemen dari kepala barisan dan kembalikan nilainya, seperti LPOP Queue: My-Queue. Memproses Baris kosong: Jika barisan kosong, LPOP mengembalikan nihil, dan anda boleh menyemak sama ada barisan wujud sebelum membaca elemen.
 Cara melihat versi pelayan Redis
Apr 10, 2025 pm 01:27 PM
Cara melihat versi pelayan Redis
Apr 10, 2025 pm 01:27 PM
Soalan: Bagaimana untuk melihat versi pelayan Redis? Gunakan alat perintah Redis-cli -version untuk melihat versi pelayan yang disambungkan. Gunakan arahan pelayan INFO untuk melihat versi dalaman pelayan dan perlu menghuraikan dan mengembalikan maklumat. Dalam persekitaran kluster, periksa konsistensi versi setiap nod dan boleh diperiksa secara automatik menggunakan skrip. Gunakan skrip untuk mengautomasikan versi tontonan, seperti menyambung dengan skrip Python dan maklumat versi percetakan.
 Betapa selamatnya kata laluan Navicat?
Apr 08, 2025 pm 09:24 PM
Betapa selamatnya kata laluan Navicat?
Apr 08, 2025 pm 09:24 PM
Keselamatan kata laluan Navicat bergantung pada gabungan penyulitan simetri, kekuatan kata laluan dan langkah -langkah keselamatan. Langkah -langkah khusus termasuk: menggunakan sambungan SSL (dengan syarat bahawa pelayan pangkalan data menyokong dan mengkonfigurasi sijil dengan betul), mengemas kini Navicat, menggunakan kaedah yang lebih selamat (seperti terowong SSH), menyekat hak akses, dan yang paling penting, tidak pernah merakam kata laluan.
