
最近要对一系列数据做同比比较,需要用到numpy和pandas来计算,下面这篇文章主要给大家介绍了关于python学习教程之Numpy和Pandas使用的相关资料,文中通过示例代码介绍的非常详细,需要的朋友可以参考借鉴。
前言
本文主要给大家介绍了关于python中Numpy和Pandas使用的相关资料,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧。
它们是什么?
NumPy是Python语言的一个扩充程序库。支持高级大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
Pandas是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。Pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
List、Numpy与Pandas
Numpy与List
相同之处:
都可以用下标访问元素,例如a[0]
都可以切片访问,例如a[1:3]
都可以使用for循环进行遍历
不同之处:
Numpy之中每个元素类型必须相同;而List中可以混合多个类型元素
Numpy使用更方便,封装了许多函数,例如mean、std、sum、min、max等
Numpy可以是多维数组
Numpy用C实现,操作起来速度更快
Pandas与Numpy
相同之处:
访问元素一样,可以使用下标,也可以使用切片访问
可以使用For循环遍历
有很多方便的函数,例如mean、std、sum、min、max等
可以进行向量运算
用C实现,速度更快
不同之处:Pandas拥有Numpy一些没有的方法,例如describe函数。其主要区别是:Numpy就像增强版的List,而Pandas就像列表和字典的合集,Pandas有索引。
Numpy使用
1、基本操作
import numpy as np #创建Numpy p1 = np.array([1, 2, 3]) print p1 print p1.dtype
[1 2 3] int64
#求平均值 print p1.mean()
2.0
#求标准差 print p1.std()
0.816496580928
#求和、求最大值、求最小值 print p1.sum() print p1.max() print p1.min()
6 3 1
#求最大值所在位置 print p1.argmax()
2
2、向量运算
p1 = np.array([1, 2, 3]) p2 = np.array([2, 5, 7])
#向量相加,各个元素相加 print p1 + p2
[ 3 7 10]
#向量乘以1个常数 print p1 * 2
[2 4 6]
#向量相减 print p1 - p2
[-1 -3 -4]
#向量相乘,各个元素之间做运算 print p1 * p2
[ 2 10 21]
#向量与一个常数比较 print p1 > 2
[False False True]
3、索引数组
首先,看下面一幅图,理解下
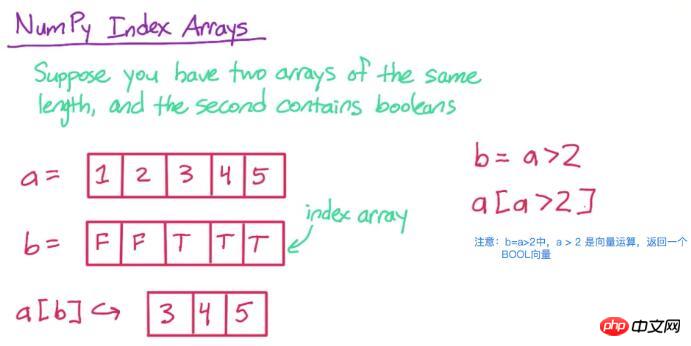
然后,咱们用代码实现看下
a = np.array([1, 2, 3, 4, 5]) print a
[1 2 3 4 5]
b = a > 2 print b
[False False True True True]
print a[b]
[3 4 5]
a[b]中,只会保留a中所对应的b位置为True的元素
4、原地与非原地
咱们先来看一组运算:
a = np.array([1, 2, 3, 4]) b = a a += np.array([1, 1, 1, 1]) print b
[2 3 4 5]
a = np.array([1, 2, 3, 4]) b = a a = a + np.array([1, 1, 1, 1]) print b
[1 2 3 4]
从上面结果可以看出来,+=改变了原来数组,而+没有。这是因为:
+=:它是原地计算,不会创建一个新的数组,在原始数组中更改元素
+:它是非原地计算,会创建一个新的数组,不会修改原始数组中的元素
5、Numpy中的切片与List的切片
l1 = [1, 2, 3, 5] l2 = l1[0:2] l2[0] = 5 print l2 print l1
[5, 2] [1, 2, 3, 5]
p1 = np.array([1, 2, 3, 5]) p2 = p1[0:2] p2[0] = 5 print p1 print p2
[5 2 3 5] [5 2]
从上可知,List中改变切片中的元素,不会影响原来的数组;而Numpy改变切片中的元素,原来的数组也跟着变了。这是因为:Numpy的切片编程不会创建一个新数组出来,当修改对应的切片也会更改原始的数组数据。这样的机制,可以让Numpy比原生数组操作更快,但编程时需要注意。
6、二维数组的操作
p1 = np.array([[1, 2, 3], [7, 8, 9], [2, 4, 5]]) #获取其中一维数组 print p1[0]
[1 2 3]
#获取其中一个元素,注意它可以是p1[0, 1],也可以p1[0][1] print p1[0, 1] print p1[0][1]
2 2
#求和是求所有元素的和 print p1.sum()
41 [10 14 17]
但,当设置axis参数时,当设置为0时,是计算每一列的结果,然后返回一个一维数组;若是设置为1时,则是计算每一行的结果,然后返回一维数组。对于二维数组,Numpy中很多函数都可以设置axis参数。
#获取每一列的结果 print p1.sum(axis=0)
[10 14 17]
#获取每一行的结果 print p1.sum(axis=1)
[ 6 24 11]
#mean函数也可以设置axis print p1.mean(axis=0)
[ 3.33333333 4.66666667 5.66666667]
Pandas使用
Pandas有两种结构,分别是Series和DataFrame。其中Series拥有Numpy的所有功能,可以认为是简单的一维数组;而DataFrame是将多个Series按列合并而成的二维数据结构,每一列单独取出来是一个Series。
咱们主要梳理下Numpy没有的功能:
1、简单基本使用
import pandas as pd pd1 = pd.Series([1, 2, 3]) print pd1
0 1 1 2 2 3 dtype: int64
#也可以求和和标准偏差 print pd1.sum() print pd1.std()
6 1.0
2、索引
(1)Series中的索引
p1 = pd.Series( [1, 2, 3], index = ['a', 'b', 'c'] ) print p1
a 1 b 2 c 3 dtype: int64
print p1['a']
(2)DataFrame数组
p1 = pd.DataFrame({
'name': ['Jack', 'Lucy', 'Coke'],
'age': [18, 19, 21]
})
print p1age name 0 18 Jack 1 19 Lucy 2 21 Coke
#获取name一列 print p1['name']
0 Jack 1 Lucy 2 Coke Name: name, dtype: object
#获取姓名的第一个 print p1['name'][0]
Jack
#使用p1[0]不能获取第一行,但是可以使用iloc print p1.iloc[0]
age 18 name Jack Name: 0, dtype: object
总结:
获取一列使用p1[‘name']这种索引
获取一行使用p1.iloc[0]
3、apply使用
apply可以操作Pandas里面的元素,当库里面没用对应的方法时,可以通过apply来进行封装
def func(value): return value * 3 pd1 = pd.Series([1, 2, 5])
print pd1.apply(func)
0 3 1 6 2 15 dtype: int64
同样可以在DataFrame上使用:
pd2 = pd.DataFrame({
'name': ['Jack', 'Lucy', 'Coke'],
'age': [18, 19, 21]
})
print pd2.apply(func)age name 0 54 JackJackJack 1 57 LucyLucyLucy 2 63 CokeCokeCoke
4、axis参数
Pandas设置axis时,与Numpy有点区别:
当设置axis为'columns'时,是计算每一行的值
当设置axis为'index'时,是计算每一列的值
pd2 = pd.DataFrame({
'weight': [120, 130, 150],
'age': [18, 19, 21]
})0 138 1 149 2 171 dtype: int64
#计算每一行的值 print pd2.sum(axis='columns')
0 138 1 149 2 171 dtype: int64
#计算每一列的值 print pd2.sum(axis='index')
age 58 weight 400 dtype: int64
5、分组
pd2 = pd.DataFrame({
'name': ['Jack', 'Lucy', 'Coke', 'Pol', 'Tude'],
'age': [18, 19, 21, 21, 19]
})
#以年龄分组
print pd2.groupby('age').groups{18: Int64Index([0], dtype='int64'), 19: Int64Index([1, 4], dtype='int64'), 21: Int64Index([2, 3], dtype='int64')}6、向量运算
需要注意的是,索引数组相加时,对应的索引相加
pd1 = pd.Series( [1, 2, 3], index = ['a', 'b', 'c'] ) pd2 = pd.Series( [1, 2, 3], index = ['a', 'c', 'd'] )
print pd1 + pd2
a 2.0 b NaN c 5.0 d NaN dtype: float64
出现了NAN值,如果我们期望NAN不出现,如何处理?使用add函数,并设置fill_value参数
print pd1.add(pd2, fill_value=0)
a 2.0 b 2.0 c 5.0 d 3.0 dtype: float64
同样,它可以应用在Pandas的dataFrame中,只是需要注意列与行都要对应起来。
总结
这一周学习了优达学城上分析基础的课程,使用的是Numpy与Pandas。对于Numpy,以前在Tensorflow中用过,但是很不明白,这次学习之后,才知道那么简单,算是有一定的收获。
Atas ialah kandungan terperinci python之Numpy和Pandas的使用介绍. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



