

Python3实现爬虫抓取网易云音乐的热门评论分析(图)

这篇文章主要给大家介绍了关于Python3实战之爬虫抓取网易云音乐热评的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧。
前言
之前刚刚入门python爬虫,有大概半个月时间没有写python了,都快遗忘了。于是准备写个简单的爬虫练练手,我觉得网易云音乐最优特色的就是其精准的歌曲推荐和独具特色的用户评论,于是写了这个抓取网易云音乐热歌榜里的热评的爬虫。我也是刚刚入门爬虫,有什么意见和问题欢迎提出,大家一起共同进步。
废话就不多说了~下面来一起看看详细的介绍吧。
我们的目标是爬取网易云中的热歌排行榜中所有歌曲的热门评论。
这样既可以减少我们需要爬取的工作量,又可以保存到高质量的评论。
实现分析
首先,我们打开网易云网页版,如图:
点击排行榜,然后点击左侧云音乐热歌榜,如图:
我们先随便打开一个歌曲,找到如何抓取指定的歌曲的热门歌评的方法,如图,我选了一个最近我比较喜欢的歌曲为例:
进去后我们会看到歌评就在这个页面的下面,接下来我们就要想办法获取这些评论。
接下来打开web控制台(chrom的话打开开发者工具,如果是其他浏览器应该也是类似),chrom下按F12,如图:
选则Network,然后我们按F5刷新一下,刷新之后得到的数据如下图所示:
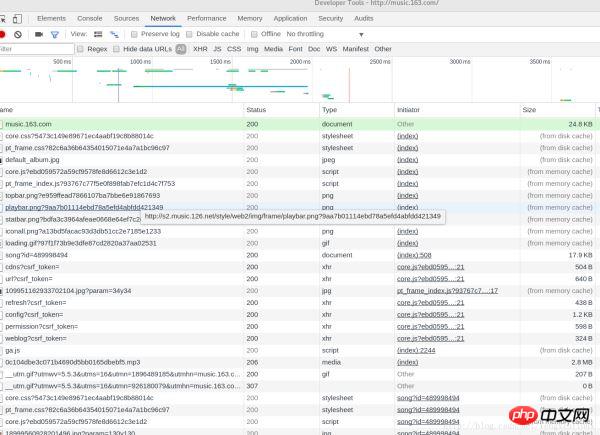
可以看到浏览器发送了非常多的信息,那么哪一个才是我们想要的呢?这里我们可以通过状态码做一个初步的判断,status code(状态码)标志了服务器请求的状态,这里状态码为200即表示请求正常,而304则表示不正常(状态码种类非常多,如果要想详细了解可以自行搜索,这里不说304具体的含义了)。所以我们一般只用看状态码为200的请求就可以了,还有就是,我们可以通过右边栏的预览来粗略观察服务器返回了什么信息(或者查看响应)。通过这两种方法结合一般我们就可以快速找到我们想要分析的请求。通过反复的查找,终于找到了含有歌评的请求,如图:
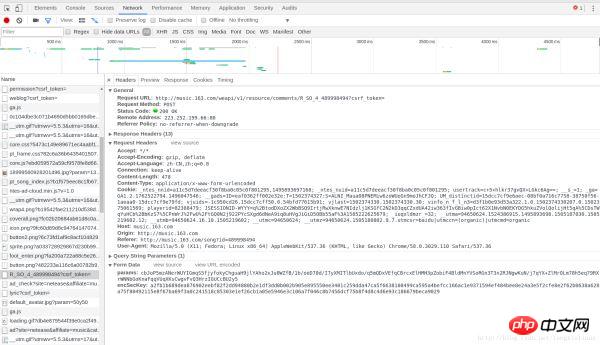
可能截图在CSDN上不是很清楚,我们在一个Name为R_SO_4_489998494?csrf_token=的POST请求中找到了包含这首歌的歌评。我们把这个分块截图发出来,这样可以看的清楚一些:
请求基本信息:

请求头部:
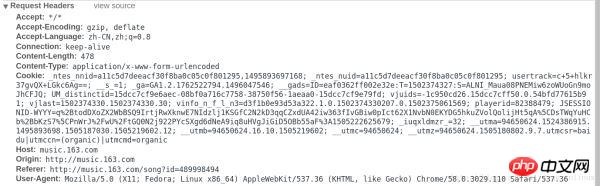
请求中的表单数据:

我们可以看到,包含这首歌歌评的请求url为http://music.163.com/weapi/v1/resource/comments/R_SO_4_489998494?csrf_token= ,我们换了几首歌后发现,这个请求的前部分都是一样的,只是R_SO_4_后面紧跟的一串数字不一样。我们可以推测出,每一首歌都有一个指定的id,R_SO_4_后面紧跟的就是这首歌的id。
我们再看一下提交的表单数据,我们会发现表单中需要填两个数据,名称为params和encSecKey。后面紧跟的是一大串字符,换几首歌会发现,每首歌的params和encSecKey都是不一样的,因此,这两个数据可能经过一个特定的算法进行加密过的。
服务器返回的和评论相关的数据为json格式的,里面含有非常丰富的信息(比如有关评论者的信息,评论日期,点赞数,评论内容等等),其中hotComments就是我们要找的热门评论,总共15条,如图所示:
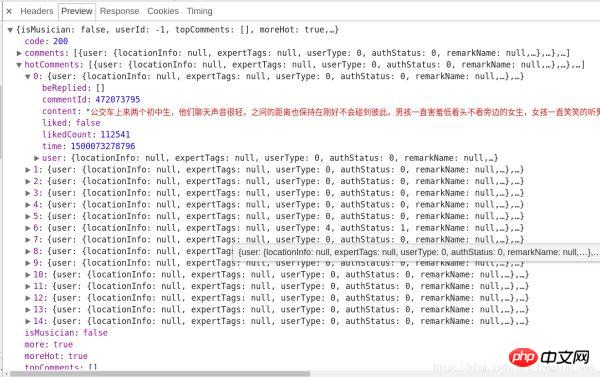
至此,我们已经确定了方向了,即只需要确定params和encSecKey这两个参数值即可。但是这两个参数是经过特定的算法进行加密的,怎么办呢?我发现了一个规律,http://music.163.com/weapi/v1/resource/comments/R_SO_4_489998494?csrf_token= 中 R_SO_4_后面的数字就是这首歌的id值,而对于不同的歌曲的param和encSecKey值,如果把一首歌比如A的这两个参数值传给B这首歌,那么对于相同的页数,这种参数是通用的,即A的第一页的两个参数值传给其他任何一首歌的两个参数,都可以获得相应歌曲的第一页的评论,对于第二页,第三页等也是类似。
而我们其实只需要获取第一页的15条热门评论,所以我们只需要随便找一首歌,将这首歌第一页中的该请求中的params和encSecKey这两个参数值复制下来,就可以使用了。
关于这两个参数如何解密,强大的知乎上其实已经有答案的了,感兴趣的朋友可以进去看一下(https://www.zhihu.com/question/36081767),我们在这里就只需要用我们这种偷懒的办法就可以完成需求了,xixi。
到此为止,我们如何抓取网易云音乐的热门评论已经分析完了,我们再分析一下如何获取云音乐热歌榜中所有歌曲的信息。
我们需要获取云音乐热歌榜中的所有歌曲的歌曲名和对应的id值。
跟上面的分析步骤类似,我们先进入热歌榜的网址,如图:
按F12,进入WEB工作台,如图:
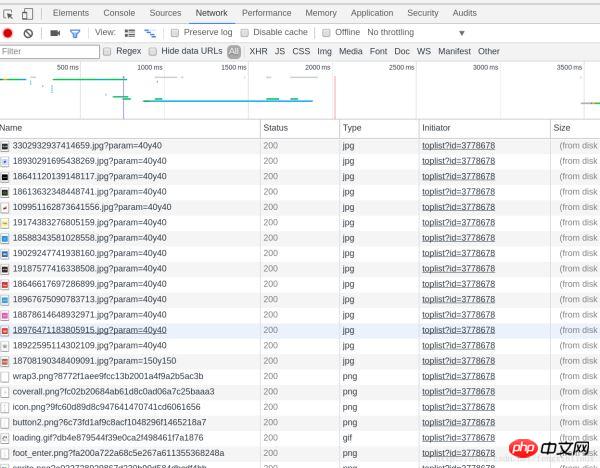
我们在一个名为toplist?id=3778678的GET请求中,找到了该榜单的所有歌曲信息。
请求对应的信息如图:
我们预览一下该请求返回的结果,如图:
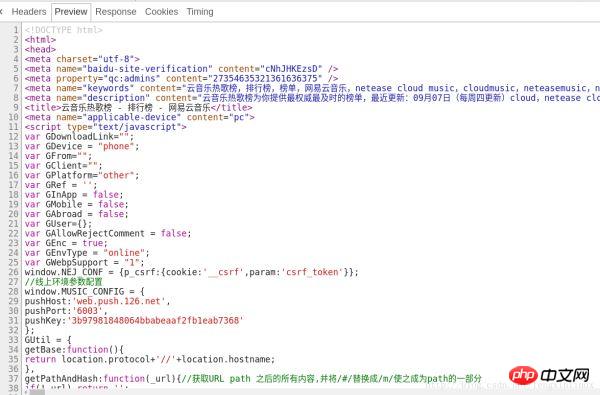
我们在代码的第524行我们找到了包含歌曲信息的代码,如图:
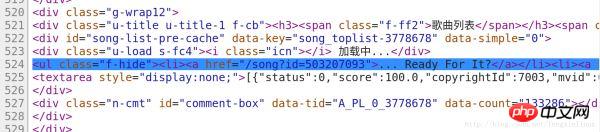
因此,我们只需要将该请求的代码中,将包含信息的代码筛选出来。
我们在这里使用正则表达式进行数据筛选。
通过观察特点,我们可以通过两次正则表达式的筛选,将我们需要的歌曲信息提取出来。
第一次正则表达式我们将该请求返回的所有代码中,提取出第525行代码。
第一次正则表达式如下:
<ul class="f-hide"> <li> <a href="/song\?id=\d*?" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >.*</a> </li> </ul>
第二次正则表达式我们将该第524行中我们需要的歌曲信息提取出来,我们需要歌曲的歌名和id,对应的正则表达式如下:
获取歌名:
<li><a href="/song\?id=\d*?" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >(.*?)</a></li>
获取歌曲的id:
<li><a href="/song\?id=(\d*?)" rel="external nofollow" rel="external nofollow" >.*?</a></li>
到此,我们整个过程已经分析完了,上代码看具体细节~~
代码如下:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import re
import urllib.request
import urllib.error
import urllib.parse
import json
def get_all_hotSong(): #获取热歌榜所有歌曲名称和id
url='http://music.163.com/discover/toplist?id=3778678' #网易云云音乐热歌榜url
html=urllib.request.urlopen(url).read().decode('utf8') #打开url
html=str(html) #转换成str
pat1=r'<ul class="f-hide"><li><a href="/song\?id=\d*?">.*</a></li></ul>' #进行第一次筛选的正则表达式
result=re.compile(pat1).findall(html) #用正则表达式进行筛选
result=result[0] #获取tuple的第一个元素
pat2=r'<li><a href="/song\?id=\d*?">(.*?)</a></li>' #进行歌名筛选的正则表达式
pat3=r'<li><a href="/song\?id=(\d*?)">.*?</a></li>' #进行歌ID筛选的正则表达式
hot_song_name=re.compile(pat2).findall(result) #获取所有热门歌曲名称
hot_song_id=re.compile(pat3).findall(result) #获取所有热门歌曲对应的Id
return hot_song_name,hot_song_id
def get_hotComments(hot_song_name,hot_song_id):
url='http://music.163.com/weapi/v1/resource/comments/R_SO_4_' + hot_song_id + '?csrf_token=' #歌评url
header={ #请求头部
'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
#post请求表单数据
data={'params':'zC7fzWBKxxsm6TZ3PiRjd056g9iGHtbtc8vjTpBXshKIboaPnUyAXKze+KNi9QiEz/IieyRnZfNztp7yvTFyBXOlVQP/JdYNZw2+GRQDg7grOR2ZjroqoOU2z0TNhy+qDHKSV8ZXOnxUF93w3DA51ADDQHB0IngL+v6N8KthdVZeZBe0d3EsUFS8ZJltNRUJ','encSecKey':'4801507e42c326dfc6b50539395a4fe417594f7cf122cf3d061d1447372ba3aa804541a8ae3b3811c081eb0f2b71827850af59af411a10a1795f7a16a5189d163bc9f67b3d1907f5e6fac652f7ef66e5a1f12d6949be851fcf4f39a0c2379580a040dc53b306d5c807bf313cc0e8f39bf7d35de691c497cda1d436b808549acc'}
postdata=urllib.parse.urlencode(data).encode('utf8') #进行编码
request=urllib.request.Request(url,headers=header,data=postdata)
reponse=urllib.request.urlopen(request).read().decode('utf8')
json_dict=json.loads(reponse) #获取json
hot_commit=json_dict['hotComments'] #获取json中的热门评论
num=0
fhandle=open('./song_comments','a') #写入文件
fhandle.write(hot_song_name+':'+'\n')
for item in hot_commit:
num+=1
fhandle.write(str(num)+'.'+item['content']+'\n')
fhandle.write('\n==============================================\n\n')
fhandle.close()
hot_song_name,hot_song_id=get_all_hotSong() #获取热歌榜所有歌曲名称和id
num=0
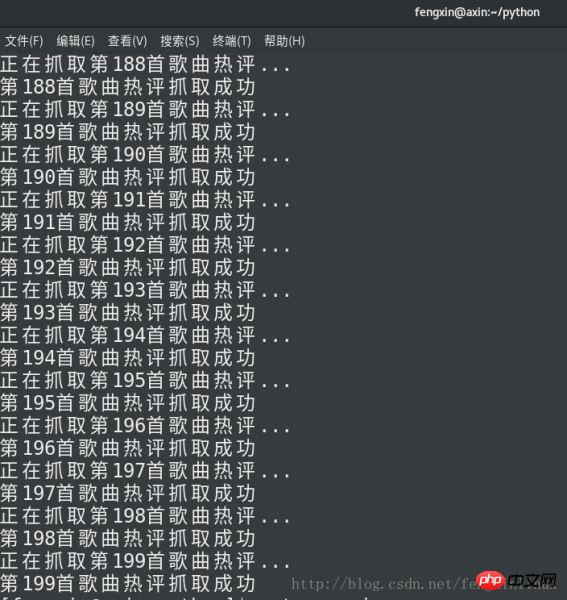
while num < len(hot_song_name): #保存所有热歌榜中的热评
print('正在抓取第%d首歌曲热评...'%(num+1))
get_hotComments(hot_song_name[num],hot_song_id[num])
print('第%d首歌曲热评抓取成功'%(num+1))
num+=1码运行结果如下:
对比一下网页上《如果我爱你》这首歌的歌评和我们保存下的歌评:
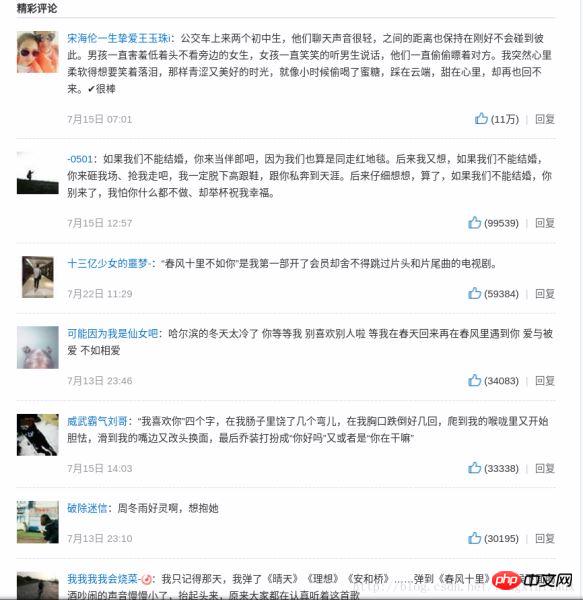

信息无误~
总结
Atas ialah kandungan terperinci Python3实现爬虫抓取网易云音乐的热门评论分析(图). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 NetEase yang pertama! Tempahan untuk permainan mudah alih menembak kemahiran berbilang wira 5V5 'Operasi Apocalypse' kini dibuka!
Mar 16, 2024 am 08:01 AM
NetEase yang pertama! Tempahan untuk permainan mudah alih menembak kemahiran berbilang wira 5V5 'Operasi Apocalypse' kini dibuka!
Mar 16, 2024 am 08:01 AM
Sejak keluaran versi permainan domestik pada bulan Februari, permainan menembak misteri NetEase "Operation Apocalypse" telah menarik rasa ingin tahu ramai pemain. Seperti yang kita semua tahu, walaupun NetEase juga mempunyai beberapa permainan menembak pada tahun-tahun awal, nampaknya kecuali untuk "Hari Selepas Esok" dan "Knives Out", tidak banyak permainan yang boleh dimainkan. Dalam tahun-tahun kebelakangan ini, kerja-kerja yang dilancarkan oleh NetEase telah mendapat momentum dan telah mencapai hasil yang besar dalam banyak trek khusus. Hakikat bahawa "Operasi Apocalypse", yang tidak pernah didedahkan sebelum ini, diletakkan sebagai pukulan pertama NetEase pada tahun baru sudah cukup untuk membuat orang ramai mengangkat kening Adakah ini isyarat bahawa NetEase akan melancarkan serangan ke atas penggambaran track? Pemain tidak sabar-sabar menantikan permainan menembak mudah alih baharu , pada 13 Mac, permainan mudah alih menembak kemahiran berbilang wira 5V5 ini yang dibangunkan oleh NetEase akhirnya mendedahkan misterinya dan secara rasmi melancarkan demonstrasi langsung pertamanya.
 NetEase
Mar 28, 2024 pm 12:50 PM
NetEase
Mar 28, 2024 pm 12:50 PM
Pada 27 Mac 2024, waktu Beijing, NetEase Games dan Marvel Games secara rasmi mengumumkan permainan baharu: permainan menembak pasukan PVP adiwira "Marvel Rivals". Pemain boleh memilih watak kegemaran mereka daripada barisan wira-wira dan penjahat super yang kaya dan pelbagai untuk membentuk pasukan bertaraf bintang, dan menggunakan kuasa besar unik mereka untuk terlibat dalam pertempuran yang menarik pada pelbagai peta yang boleh dipecahkan dalam multiverse Marvel. "Kami sangat teruja untuk membawa "Konfrontasi Marvel" kepada pemain di seluruh dunia. Kami sentiasa menyukai Marvel Universe dan wataknya, dan kami teruja untuk membangunkan permainan ini, pasukan kreatif utama "Peraduan Marvel" berkata, " Inilah permainan yang kami impikan untuk mencipta, dan kami amat berbangga kerana dapat mengubahnya daripada mimpi menjadi kenyataan." "NetEase
 NetEase mengumumkan penggantungan 'Marvel Super War', yang merupakan permainan MOBA pertama Marvel!
Apr 18, 2024 am 10:50 AM
NetEase mengumumkan penggantungan 'Marvel Super War', yang merupakan permainan MOBA pertama Marvel!
Apr 18, 2024 am 10:50 AM
"Marvel Super War" NetEase mengumumkan bahawa ia akan menamatkan operasi dan menutup pelayan permainan pada jam 15:00 pada 17 Jun 2024. Pintu masuk muat turun untuk semua platform kini telah ditutup, dan cas semula permainan dan pendaftaran pengguna baharu telah dihentikan. Sebagai permainan mudah alih MOBA pertama Marvel, permainan ini memaparkan ciri tempur wira-wira secara sahih dan memulihkan pandangan dunia yang hebat bagi alam semesta Marvel. Dalam permainan, anda akan dapat berkumpul di alam semesta selari dengan Avengers, X-Men, Fantastic Four dan ramai wira-wira serta penjahat super, dan bersaing dengan Iron Man, Captain America, Spider-Man, Loki, Thanos, Deadpool Wait untuk lebih daripada 60 watak Marvel klasik untuk bertarung bersama!
 Versi permainan Sora? Permainan mudah alih Nishuihan mengeluarkan alat penjanaan video AI, menyokong input menaip
Feb 26, 2024 pm 08:55 PM
Versi permainan Sora? Permainan mudah alih Nishuihan mengeluarkan alat penjanaan video AI, menyokong input menaip
Feb 26, 2024 pm 08:55 PM
Baru-baru ini, permainan mudah alih Nishuihan secara rasmi mengeluarkan alat penjanaan video AI baharu, yang melaluinya pemain boleh "menghasilkan blokbuster hanya dengan menaip." Menurut pengenalan rasmi, fungsi tersebut dilaksanakan berdasarkan permainan Nishuihan itu sendiri dan sangat terlibat dalam AI. Tidak memerlukan sebarang peralatan, pelakon atau kesan khas Anda hanya perlu menaip mana-mana imej watak, aksi dan baris, dan kandungan yang sepadan boleh dijana dalam masa nyata dalam permainan melalui AI dan difilemkan. Pada masa yang sama, pemain disokong untuk melaraskan butiran, termasuk pakaian watak, solek, gaya rambut, personaliti, suara, dsb. Fungsi ini juga menyokong muat naik gambar/video, tangkapan gerakan melalui AI, dan penjanaan pergerakan dan ekspresi masa nyata yang "tidak tersedia dalam permainan" dalam permainan. Pegawai menyatakan bahawa ciri ini mempunyai visi yang sama seperti Sora, iaitu untuk "menjadikan ruang kreatif tidak berkesudahan dan ambang kreatif menghampiri had".
 Pelayan nasional Blizzard kembali ke tempat kejadian untuk menonton, Valina menunjukkan kulitnya yang berkulit salji dan kaki yang panjang, dan Dva dalam skirt merah jambunya sangat comel!
Apr 11, 2024 pm 04:04 PM
Pelayan nasional Blizzard kembali ke tempat kejadian untuk menonton, Valina menunjukkan kulitnya yang berkulit salji dan kaki yang panjang, dan Dva dalam skirt merah jambunya sangat comel!
Apr 11, 2024 pm 04:04 PM
NetEase dan Microsoft Blizzard secara rasminya mengumumkan kembalinya pelayan nasional Blizzard juga mengadakan majlis sambutan di bawah bangunan ibu pejabat. Adegan telah disediakan pada awal pagi, dan semua permainan Blizzard disenaraikan, termasuk World of Warcraft, Hearthstone, Diablo 3, Heroes of the Storm, Overwatch, StarCraft 2, dll. Perhatikan pengumuman rasmi daripada Blizzard dan NetEase Heroes of the Storm tidak disebut, tetapi tiada poster langsung untuk permainan ini, jadi pemain yang suka Heroes of the Storm tidak perlu risau, seluruh keluarga Blizzard akan kembali. Kita juga harus memberi perhatian khusus kepada World of Warcraft Poster yang dipaparkan adalah untuk World of Warcraft 11.0 War for the Center of the Earth Jelas sekali, versi klasik di mana Mason secara peribadi menyalin pedang itu akan dimainkan pada pelayan Cina pada musim panas ini.
 Tencent Photon H Studio sedang mengambil pekerja di Hangzhou dan merancang untuk membuat RPG dunia terbuka 3A
Feb 05, 2024 pm 01:45 PM
Tencent Photon H Studio sedang mengambil pekerja di Hangzhou dan merancang untuk membuat RPG dunia terbuka 3A
Feb 05, 2024 pm 01:45 PM
Baru-baru ini, Tencent Interactive Entertainment Recruitment mengeluarkan maklumat pengambilan, menunjukkan bahawa Photon H Studio komited untuk membangunkan projek RPG dunia terbuka peringkat AAA yang kaya kandungan. Jawatan pengambilan hangat meliputi pelbagai bidang seperti jurutera UE5, bahagian belakang, reka bentuk tahap, reka bentuk adegan aksi, pemodelan watak, kesan khas dan pengedaran, dll. Sasaran lokasi kerja jawatan ini adalah di Hangzhou, di mana NetEase beribu pejabat.
 Bolehkah NetEase Master mendaftar semula selepas log keluar?
Mar 07, 2024 pm 03:25 PM
Bolehkah NetEase Master mendaftar semula selepas log keluar?
Mar 07, 2024 pm 03:25 PM
NetEase Master APP ialah platform sosial untuk pemain boleh mendapatkan perundingan permainan di sini Ramai pengguna ingin mengetahui sama ada NetEase Master boleh mendaftar semula selepas log keluar. Bolehkah NetEase Master mendaftar semula selepas log keluar? 1. NetEase Master boleh mendaftar semula selepas log keluar. 2. Tetapi anda mesti mendaftar sekurang-kurangnya seminggu sebelum anda boleh memilih nombor ini untuk mendaftar. 3. Akaun tidak boleh dinyatakan, dan data sebelumnya akan dikosongkan. 4. Selepas pengguna log keluar, semua maklumat terdahulu dan baki berkaitan telah dibersihkan. Artikel berkaitan: Bagaimanakah induk NetEase menukar nombor telefon mudah alih yang terikat?
 Sempena pembukaan semula pelayan kebangsaan World of Warcraft, berikut ialah 4 panduan pemilihan versi utama, yang terakhir lebih sesuai untuk pemain kasual
Apr 13, 2024 am 09:16 AM
Sempena pembukaan semula pelayan kebangsaan World of Warcraft, berikut ialah 4 panduan pemilihan versi utama, yang terakhir lebih sesuai untuk pemain kasual
Apr 13, 2024 am 09:16 AM
Pada masa ini terdapat 4 versi World of Warcraft Pelayan nasional telah ditutup selama lebih daripada setahun. Dianggarkan ramai pemain tidak tahu di mana setiap versi telah dibangunkan. 1. Pada penghujung pelayan rasmi versi 10.0, sebelum penutupan pelayan nasional, versi 10.0 baru sahaja dimulakan pada versi 10.26. Akan ada versi 10.27 kemudian, dan pek pengembangan Age of Dragon akan tamat . Walaupun versi 10.0 telah menerima ulasan yang baik dalam pelayan asing dan telah memulihkan beberapa populariti untuk Blizzard, teras permainan dalam versi 10.0 tidak berubah sama sekali Ia masih mengenai rahsia besar dan serbuan, dan bilangan pemain PVP sangat banyak kecil. Dengan kemas kini berterusan versi pelayan rasmi, kecenderungan permainan pemain juga telah berubah daripada PVE dan PVP kepada pengumpulan.
