

造成网页乱码的根本性原因是什么
先看段代码:
<!DOCTYPE HTML> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <title>网页编码</title> </head> <body> </body> </html>
HTML代码中的 指定了网页的编码为utf-8。
网页编码涉及的知识点比较多,总的说来它也是一个历史遗留问题。
第一台计算机(ENIAC)于1946年2月诞生于美国,当时美国只考虑自己使用,并在计算机诞生后的几年里制定了一套ASCII码标准(American Standard Code for Information Interchange,美国信息交换标准代码),它是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。
ASCII码使用8位二进制数组合来表示256种可能的字符(2的8次方=256),包含了大小写字母,数字0到9,标点符号,以及在美式英语中使用的特殊控制字符。一个字符占1个字节。ASCII码表部分编码如下:
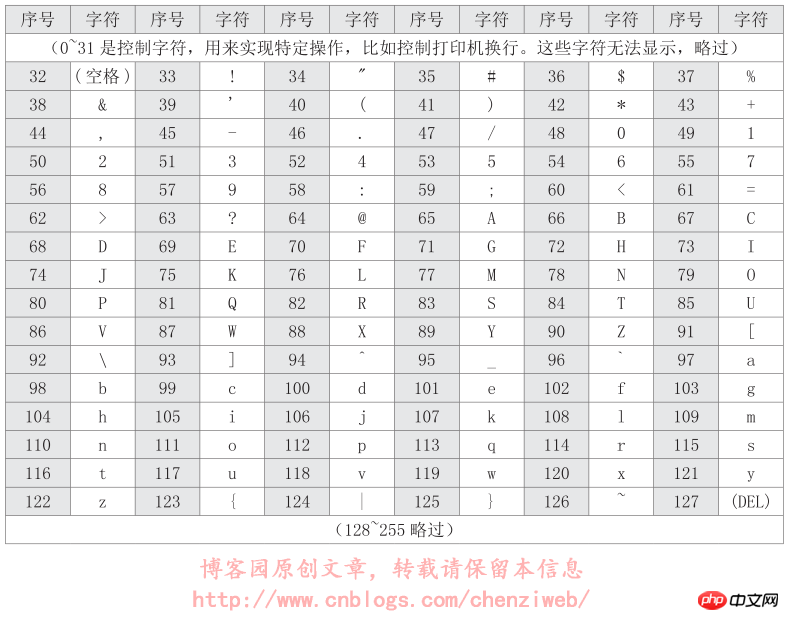
HTML的转义符(字符实体),比如符号“<”的转义符为“<”或“<”,其中的数字编号“60”即是ASCII码表的第60序号。类似的,大写字母“K”也可以转义为“K”。
我们使用转义符做个试验: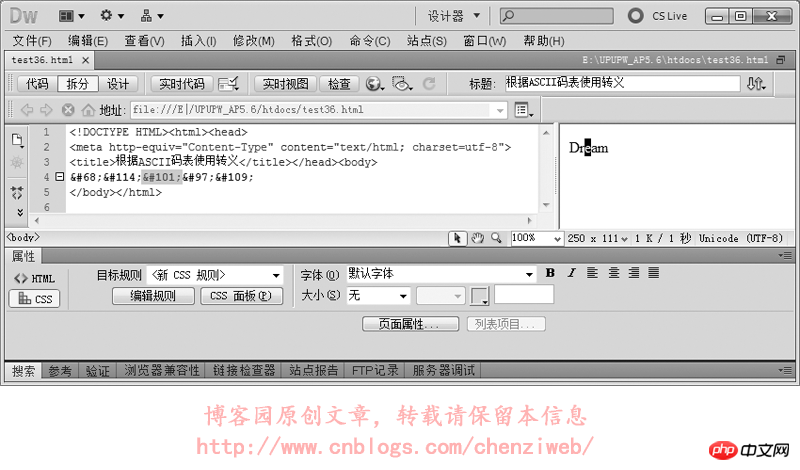
美国制定ASCII码的意思是:ASCII码可以满足在计算机领域所有字符和表示上的需要。不过这只是美国自己的意思,毕竟所有的英文单词都可以拆分来自26个英文字母,ASCII码表能表达256个字符,确实足够美国使用。
后来世界各地也都开始使用计算机,很多国家的语言文字并不是英文,这些国家的文字都没被包含在ASCII码表里。以我们中国为例,汉字近10万个,根本无法排进ASCII码表。于是我们国家对ASCII码表进行拓展并形成自己的的一套标准,在标准中一个汉字占2个字节,新的码表可以表达65536个汉字。但一开始并没有将码表全部填充使用完,只收录了常用的6000多个汉字、英文及其它符号,这套标准称为GB2312(信息交换用汉字编码字符集,GB是“国家标准”的简化词“国标”的拼音首字母缩写,2312是国标序号)。后来又制定了一套收录更多汉字的标准(收录的汉字有2万多个),称为GBK(汉字编码扩展规范,K是“扩”的拼音首字母)。
在GB2312或GBK里,许多标点符号都使用2个字节进行了重新编码,这类占2个字节的标点符号称为“全角”字符(“全角”也称“全形”或“全宽”或“全码”),原来ASCII码表中占1个字节的标点符号则称为“半角”字符(“半角”也称“半形”或“半宽”或“半码”)。全角的逗号、括号、句号等与半角是不一样的:
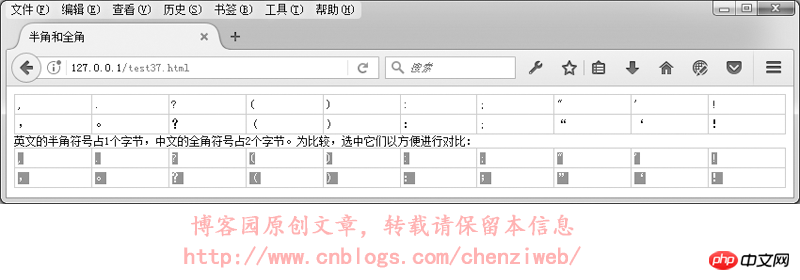
在中文输入法下,默认的标点符号是全角字符;在英文输入法下,标点符号则是半角字符。
我们接着讲故事:随着使用计算机的国家越来越多,各个国家制定自己的计算机编码标准的情况也越来越多,导致的结果是:各国计算机的编码互不支持、认识。比如在美国的计算机里要显示汉字,则必须安装汉字系统才可以,否则中文文件在美国系统的计算机中打开便是乱码。
就这样,在这个时期催生出了一个叫ISO的国际组织(International Organization for Standardization,国际标准化组织),着手解决各国的编码问题。ISO统一制作了一个称为UNICODE(统一码、万国码、单一码,Universal Multiple-Octet Coded Character Set,又简称为UCS)的编码方案,用于收录地球上所有文字和符号。UNICODE字符分为17组编排,每组编排称为平面(Plane),每个平面拥有65536个码位,共计可以收录1114112个字符(111万个字符,足够大的容量)。UNICODE编码统一一个字符占2个字节。
但UNICODE在很长一段时间内无法推广,直到互联网的出现,数据的传输与交换使各国之间的编码进行统一化成为迫切的需要。但早期的硬盘和网络流量都非常昂贵,UNICODE编码里的每个字符却占用了2个字节的容量,于是为了节省文件存储时所占的硬盘空间,也为了节省字符在网络传输过程中所占用的网络流量,又制定了基于UNICODE、面向传输的众多标准,这些面向传输的标准统称为UTF(UCS Transfer Format)。UNICODE编码与UTF编码并不是直接的一一对应,而是要通过一些算法和规则来转换。UNICODE与UTF的关系是:UNICODE是根本、基础、目的,而UTF只是一种实现UNICODE的手段、方法、过程。
常见的UTF格式有:UTF-8,UTF-16,UTF-32。其中UTF-8是互联网上使用最广的一种UNICODE的实现方式,它专为传输而设计。正因为UTF-8是基于UNICODE而设计的传输实现方式,所以它能使编码无国界,任意国家的文字都能在任意国家的电脑浏览器中里正常显示。UTF-8最大的一个特点是:它是一种变长的编码方式,它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度,当能够使用1字节表示一个符号时,便使用1个字节来表示,如果需要2字节才能表示的符号,便使用2个字节来表示,类推,直到4个字节,从而节省硬盘存储空间和网络流量。
所以我们的网站在开发时如果使用GB2312或GBK编码,当别的国家的电脑不支持汉字编码,那么看到的将是乱码,显示出来类似这样:口口口口口。而网站如果使用UTF-8编码,则任意国家的电脑在打开网站时其内容会自动转换成UNICODE编码,并且由于现在的电脑都支持UNICODE编码,从而能正常显示任意文字!
但是国内很多的网站仍然使用GB2312或GBK编码,这类网站通常只面对国内用户提供服务,面对国内用户不会有显示上的问题。只是如果面对其他国家的浏览者,这类网站被打开时很大程度上将呈现乱码。
为了网站的高兼容性与国际化,推荐网站使用UTF-8编码,而不是使用GB2312或GBK编码。
指定网页为UTF-8、GB2312和GBK的标签分别为:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <meta http-equiv="Content-Type" content="text/html; charset=gb2312"> <meta http-equiv="Content-Type" content="text/html; charset=gbk">
那么有一个问题出现了:网页各种编码的区别,仅仅是在于这一行meta标签的设置差别吗?仅仅是“utf-8”这5个字符换成“gb2312”这6个字符之类的这种“小差别”吗?
不是的,差别不仅仅是这几个字符的差别。当网页指定meta标签中的编码为utf-8后,DreamWeaver在保存网页时会自动将网页文件保存为utf-8的编码格式(二进制码使用utf-8的编码格式),meta标签中的utf-8编码是为了告诉浏览器:这个网页用的是utf-8编码,请在显示时使用utf-8编码的格式解析并呈现出来;而如果meta标签中指定编码为gb2312,DreamWeaver在保存网页时会自动将网页文件保存为gb2312的编码格式(二进制码使用gb2312的编码格式),同样,meta标签中的gb2312编码只是为了告诉浏览器:这个网页用的是gb2312编码,请在显示时使用gb2312编码的格式解析并呈现出来。我们做个试验,将一个文本文件分别保存为utf-8格式(打开记事本新建文本文件,输入内容后,选择菜单:文件→另存为,编码选择为UTF-8)和gb2312格式(另存时编码选择为ANSI,ANSI代表当前操作系统的默认编码,在简体中文Windows操作系统中,ANSI 编码代表 GBK 编码;在繁体中文Windows操作系统中,ANSI编码代表Big5;在日文Windows操作系统中,ANSI 编码代表 Shift_JIS 编码,类推),对比其二进制数据。这里使用UltraEdit-32文件编辑器对文本文件进行16进制查看,即使用16进制查看文件的二进制数据: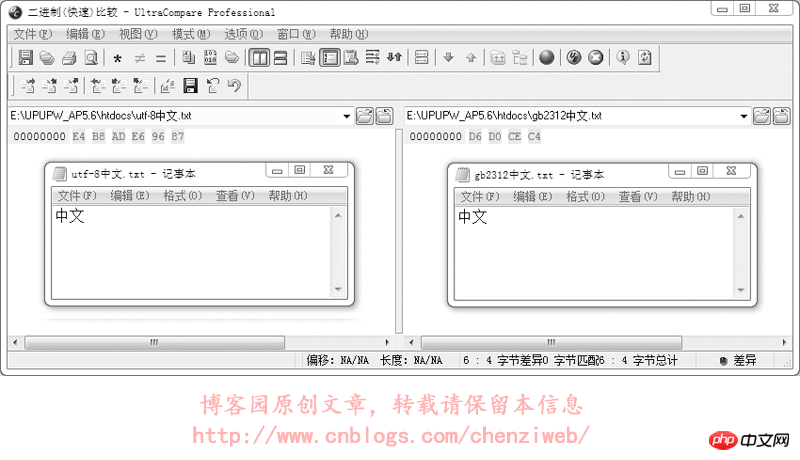
从上图中可以看到,使用utf-8编码和使用gb2312编码保存的文件,其二进制数据是不一样的,即这两个文件的二进制数据内容是不一样的。记事本软件在打开文本文件时,会尝试识别文件的编码并进行解析和显示,即文字保存在记事本里,无论保存成utf-8编码还是gb2312编码,通常情况下记事本都能正常识别和显示,不需要在文件里额外记录数据以告知记事本该文件是什么编码。但很多软件却无法做到智能识别文本文件的编码,这就要求文本文件在保存时,必须附带一些特殊的内容(额外的数据)以告知该文件是什么编码。UNICODE规范中有一个BOM(Byte Order Mark)的概念,就是字节序标记,在文件头部开始位置写入三个字节(EF BB BF)以告知该文件是utf-8编码格式。但这个BOM又带出了新的问题:不是所有的软件或处理程序都支持BOM,即不是所有的软件或处理程序都能识别文件开头的(EF BB BF)这三个字节。当不支持识别时,这三个字节又会被当成文件的实际数据内容。早期的火狐不支持对BOM的识别,当遇到BOM时会对这三个字节显示出特殊的乱码符号;而到目前为止,PHP处理程序仍然不支持BOM,即当一个PHP文件保存为utf-8时,如果附带了BOM,那么PHP处理程序会将BOM解析为PHP文件的实际数据内容而导致出错!在DreamWeaver中,选择软件头部菜单:修改→页面属性(也可以直接按快捷键ctrl+j),在弹出的页面属性面板中点选“标题/编码”,即可看到可供选择的编码。通常在改变网页的编码时,使用这种方式改变。如下图: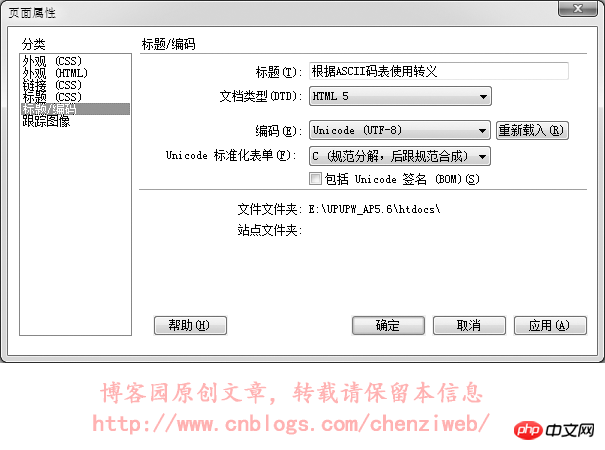
所以:当我们在meta标签中设置为utf-8编码格式时,网页文件就必须要存储为utf-8格式,这样浏览器才能正常显示网页而不是显示乱码。如果在meta标签中设置utf-8编码格式,网页文件却保存为gbk或其它格式,那么在打开网页时浏览器会接到网页meta标签中格式的通知:使用utf-8编码格式来解析和显示网页,而网页的二进制码(数据内容)却为gbk编码或其它格式,显示出来就会是乱码!这好比相亲时,红娘手里的资料有误,错误的告知男方:女方讲英语(meta标签中设置为utf-8编码)。结果女方却不懂英语(文件却不是utf-8编码)。男方开口一句“Hello”就让女方不知所谓了(乱码)。
我们来实验一下,网页指定meta标签中的编码为utf-8,文件却保存为gbk格式:我们先用DreamWeaver编辑一个utf-8格式的网页并保存,然后再用记事本打开该网页,另存为,编码选择为ANSI。
<!DOCTYPE HTML> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <title>中文</title> </head> <body> 本文件使用dreamweaver保存后,再使用记事本打开,并另存为ANSI编码。 </body> </html>
在浏览器中的执行结果如下:
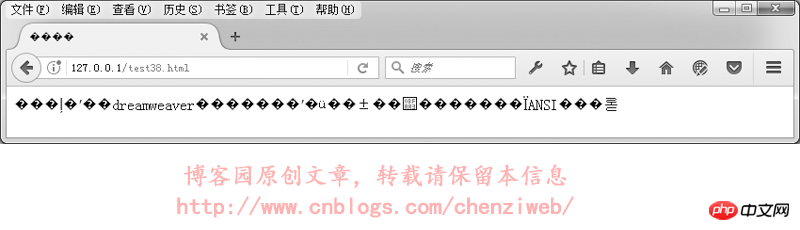
综上所述:网页开发时,尽量使用utf-8编码格式,并且在保存文件时,保存为utf-8编码。(dreamweaver在保存网页文件时,会根据所指定的编码自动保存为正确的对应编码,但如果使用其它网站代码编辑器,比如记事本、Editplus等,就需要注意,在保存文件时要选择为正确的编码)。
Atas ialah kandungan terperinci 造成网页乱码的根本性原因是什么. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Bagaimana untuk menyelesaikan aksara Cina yang kacau dalam Linux
Feb 21, 2024 am 10:48 AM
Bagaimana untuk menyelesaikan aksara Cina yang kacau dalam Linux
Feb 21, 2024 am 10:48 AM
Masalah bercelaru Cina Linux adalah masalah biasa apabila menggunakan set aksara Cina dan pengekodan. Watak bercelaru mungkin disebabkan oleh tetapan pengekodan fail yang salah, tempat sistem tidak dipasang atau ditetapkan, dan ralat konfigurasi paparan terminal, dsb. Artikel ini akan memperkenalkan beberapa penyelesaian biasa dan memberikan contoh kod khusus. 1. Periksa tetapan pengekodan fail Gunakan arahan fail untuk melihat pengekodan fail Gunakan perintah fail dalam terminal untuk melihat pengekodan fail: nama fail-fail jika terdapat "charset".
 Apakah sebab mengapa penyiaran skrin gagal? 'Mesti dibaca untuk pemula: Bagaimana untuk menyelesaikan masalah sambungan penyiaran wayarles yang tidak berjaya'
Feb 07, 2024 pm 05:03 PM
Apakah sebab mengapa penyiaran skrin gagal? 'Mesti dibaca untuk pemula: Bagaimana untuk menyelesaikan masalah sambungan penyiaran wayarles yang tidak berjaya'
Feb 07, 2024 pm 05:03 PM
Mengapa siaran skrin wayarles gagal disambungkan? Sesetengah rakan telah melaporkan bahawa sambungan gagal apabila menggunakan pencerminan skrin wayarles Apakah yang sedang berlaku? Apakah yang perlu saya lakukan jika sambungan pencerminan skrin wayarles gagal? Sila sahkan sama ada komputer, TV dan telefon mudah alih anda disambungkan ke rangkaian WiFi yang sama. Perisian pencerminan skrin memerlukan peranti berada pada rangkaian yang sama untuk berfungsi dengan betul, dan Pencerminan Skrin Pantas tidak terkecuali. Oleh itu, sila semak tetapan rangkaian anda dengan cepat. Adalah penting untuk menentukan sama ada fungsi pencerminan skrin disokong. TV pintar dan telefon mudah alih biasanya menyokong fungsi DLNA atau AirPlay. Jika fungsi siaran skrin tidak disokong, siaran skrin tidak akan dapat dilakukan. Sahkan sama ada peranti disambungkan dengan betul: Mungkin terdapat berbilang peranti di bawah WiFi yang sama Pastikan anda menyambung ke peranti yang ingin anda kongsikan skrin. 4. Pastikan rangkaian
 Apakah yang menyebabkan Pejabat WPS tidak dapat memulakan kerja cetakan?
Mar 20, 2024 am 09:52 AM
Apakah yang menyebabkan Pejabat WPS tidak dapat memulakan kerja cetakan?
Mar 20, 2024 am 09:52 AM
Apabila menyambungkan pencetak ke rangkaian kawasan setempat dan memulakan kerja cetakan, beberapa situasi kecil mungkin berlaku Contohnya, masalah "wpsoffice tidak boleh memulakan kerja cetakan..." kadang-kadang berlaku, mengakibatkan ketidakupayaan untuk mencetak fail, dsb. ., menangguhkan kerja dan kajian kami, dan menyebabkan kesan buruk , izinkan saya memberitahu anda bagaimana untuk menyelesaikan masalah bahawa wpsoffice tidak boleh memulakan kerja cetakan? Sudah tentu, anda boleh menaik taraf perisian atau pemacu untuk menyelesaikan masalah, tetapi ini akan membawa anda masa yang lama. Di bawah ini saya akan memberikan anda penyelesaian yang boleh diselesaikan dalam beberapa minit. Pertama sekali, saya perhatikan bahawa wpsoffice tidak boleh memulakan kerja cetakan, mengakibatkan ketidakupayaan untuk mencetak. Untuk menyelesaikan masalah ini, kita perlu menyiasat satu persatu. Juga, pastikan pencetak dihidupkan dan disambungkan. Secara amnya, sambungan tidak normal akan menyebabkan
 Panduan Komprehensif untuk Ralat PHP 500: Punca, Diagnosis dan Pembetulan
Mar 22, 2024 pm 12:45 PM
Panduan Komprehensif untuk Ralat PHP 500: Punca, Diagnosis dan Pembetulan
Mar 22, 2024 pm 12:45 PM
Panduan Komprehensif untuk Ralat PHP 500: Punca, Diagnosis dan Pembetulan Semasa pembangunan PHP, kami sering menghadapi ralat dengan kod status HTTP 500. Ralat ini biasanya dipanggil "500InternalServerError", yang bermaksud bahawa beberapa ralat yang tidak diketahui berlaku semasa memproses permintaan di bahagian pelayan. Dalam artikel ini, kami akan meneroka punca biasa ralat PHP500, cara mendiagnosisnya dan cara membetulkannya serta memberikan contoh kod khusus untuk rujukan. Punca biasa 1.500 ralat 1.
 Bagaimana untuk menyelesaikan masalah aksara Cina yang kacau dalam Windows 10
Jan 16, 2024 pm 02:21 PM
Bagaimana untuk menyelesaikan masalah aksara Cina yang kacau dalam Windows 10
Jan 16, 2024 pm 02:21 PM
Dalam sistem Windows 10, aksara bercelaru adalah perkara biasa. Sebab di sebalik ini selalunya ialah sistem pengendalian tidak menyediakan sokongan lalai untuk beberapa set aksara, atau terdapat ralat dalam pilihan set aksara yang ditetapkan. Untuk menetapkan ubat yang betul, kami akan menganalisis prosedur operasi sebenar secara terperinci di bawah. Bagaimana untuk menyelesaikan kod kacau Windows 10 1. Buka tetapan dan cari "Masa dan Bahasa" 2. Kemudian cari "Bahasa" 3. Cari "Urus Tetapan Bahasa" 4. Klik "Tukar Tetapan Wilayah Sistem" di sini 5. Semak seperti yang ditunjukkan dan klik Hanya pastikan.
 Mengapa telefon mudah alih Apple mengecas dengan perlahan?
Mar 08, 2024 pm 06:28 PM
Mengapa telefon mudah alih Apple mengecas dengan perlahan?
Mar 08, 2024 pm 06:28 PM
Sesetengah pengguna mungkin menghadapi kelajuan pengecasan yang perlahan apabila menggunakan telefon Apple. Terdapat banyak sebab untuk masalah ini Ia mungkin disebabkan oleh kuasa rendah peranti pengecasan, kegagalan peranti, masalah dengan antara muka USB telefon bimbit, atau penuaan bateri dan faktor lain. Mengapa telefon bimbit Apple mengecas dengan sangat perlahan Jawapan: masalah peralatan mengecas, masalah perkakasan telefon bimbit, masalah sistem telefon bimbit. 1. Apabila pengguna menggunakan peralatan pengecasan dengan kuasa yang agak rendah, kelajuan pengecasan telefon bimbit akan menjadi sangat perlahan. 2. Menggunakan pengecas inferior pihak ketiga atau kabel pengecasan juga akan menyebabkan pengecasan perlahan. 3. Adalah disyorkan bahawa pengguna menggunakan pengecas asal rasmi, atau menggantikannya dengan pengecas kuasa tinggi yang diperakui biasa. 4. Terdapat masalah dengan perkakasan telefon bimbit pengguna Sebagai contoh, antara muka USB telefon bimbit tidak boleh dihubungi.
 Mendedahkan punca utama skrin biru win11
Jan 04, 2024 pm 05:32 PM
Mendedahkan punca utama skrin biru win11
Jan 04, 2024 pm 05:32 PM
Saya percaya ramai rakan telah menghadapi masalah skrin biru sistem, tetapi saya tidak tahu apa punca skrin biru win11 Sebenarnya, terdapat banyak sebab untuk skrin biru sistem, dan kami boleh menyiasat dan menyelesaikannya dengan teratur. Sebab skrin biru win11: 1. Memori tidak mencukupi 1. Ia mungkin berlaku apabila menjalankan terlalu banyak perisian atau permainan menggunakan terlalu banyak memori. 2. Terutama sekarang terdapat pepijat limpahan memori dalam win11, jadi kemungkinan besar akan dihadapi. 3. Pada masa ini, anda boleh cuba menyediakan memori maya untuk menyelesaikan masalah, tetapi cara terbaik ialah menaik taraf modul memori. 2. CPU overclocking dan overheating 1. Punca masalah CPU sebenarnya serupa dengan memori. 2. Ia biasanya berlaku apabila menggunakan pemprosesan pasca, pemodelan dan perisian lain, atau semasa bermain permainan berskala besar. 3. Jika penggunaan CPU terlalu tinggi, skrin biru akan muncul.
 Kaedah penyuntingan untuk menyelesaikan masalah aksara bercelaru semasa membuka fail dll
Jan 06, 2024 pm 07:53 PM
Kaedah penyuntingan untuk menyelesaikan masalah aksara bercelaru semasa membuka fail dll
Jan 06, 2024 pm 07:53 PM
Apabila ramai pengguna menggunakan komputer, mereka akan mendapati terdapat banyak fail dengan akhiran dll, tetapi ramai pengguna tidak tahu bagaimana untuk membuka fail tersebut Pengguna yang ingin tahu, sila lihat butiran berikut Tutorial~Cara membuka dan edit fail dll: 1. Muat turun perisian yang dipanggil "exescope" dan muat turun dan pasangnya. 2. Kemudian klik kanan fail dll dan pilih "Edit sumber dengan exescope". 3. Kemudian klik "OK" dalam kotak gesaan ralat timbul. 4. Kemudian pada panel kanan, klik tanda "+" di hadapan setiap kumpulan untuk melihat kandungan yang terkandung di dalamnya. 5. Klik pada fail dll yang anda ingin lihat, kemudian klik "Fail" dan pilih "Eksport". 6. Kemudian anda boleh
