

python爬取安居客二手房网站数据方法分享

本文主要为大家带来一篇python爬取安居客二手房网站数据(实例讲解)。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧,希望能帮助到大家。
现在开始正式进行爬虫书写首先,需要分析一下要爬取的网站的结构:作为一名河南的学生,那就看看郑州的二手房信息吧!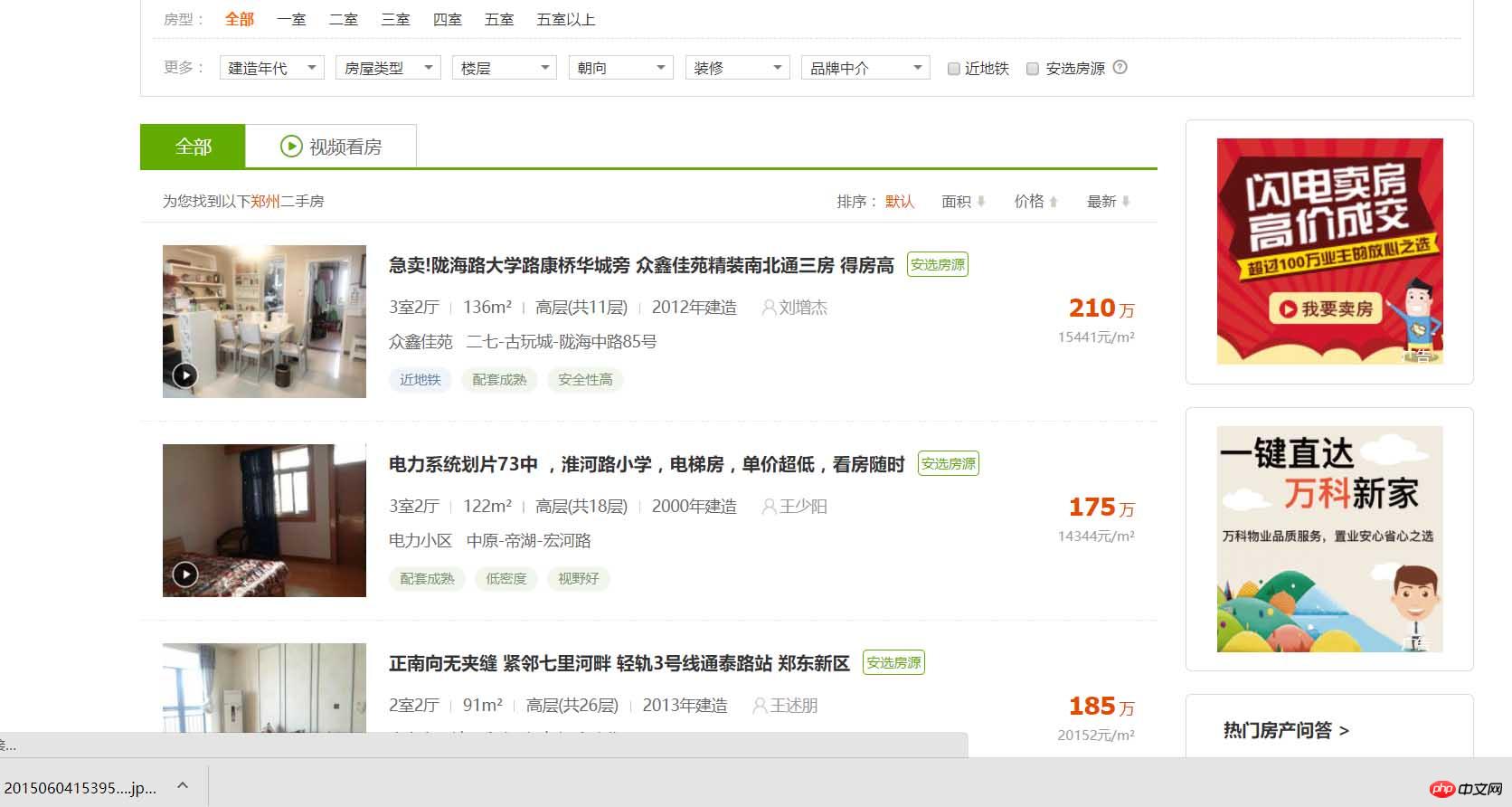
在上面这个页面中,我们可以看到一条条的房源信息,由上可以看到网页一条条的房源信息,点击进去后就会发现:
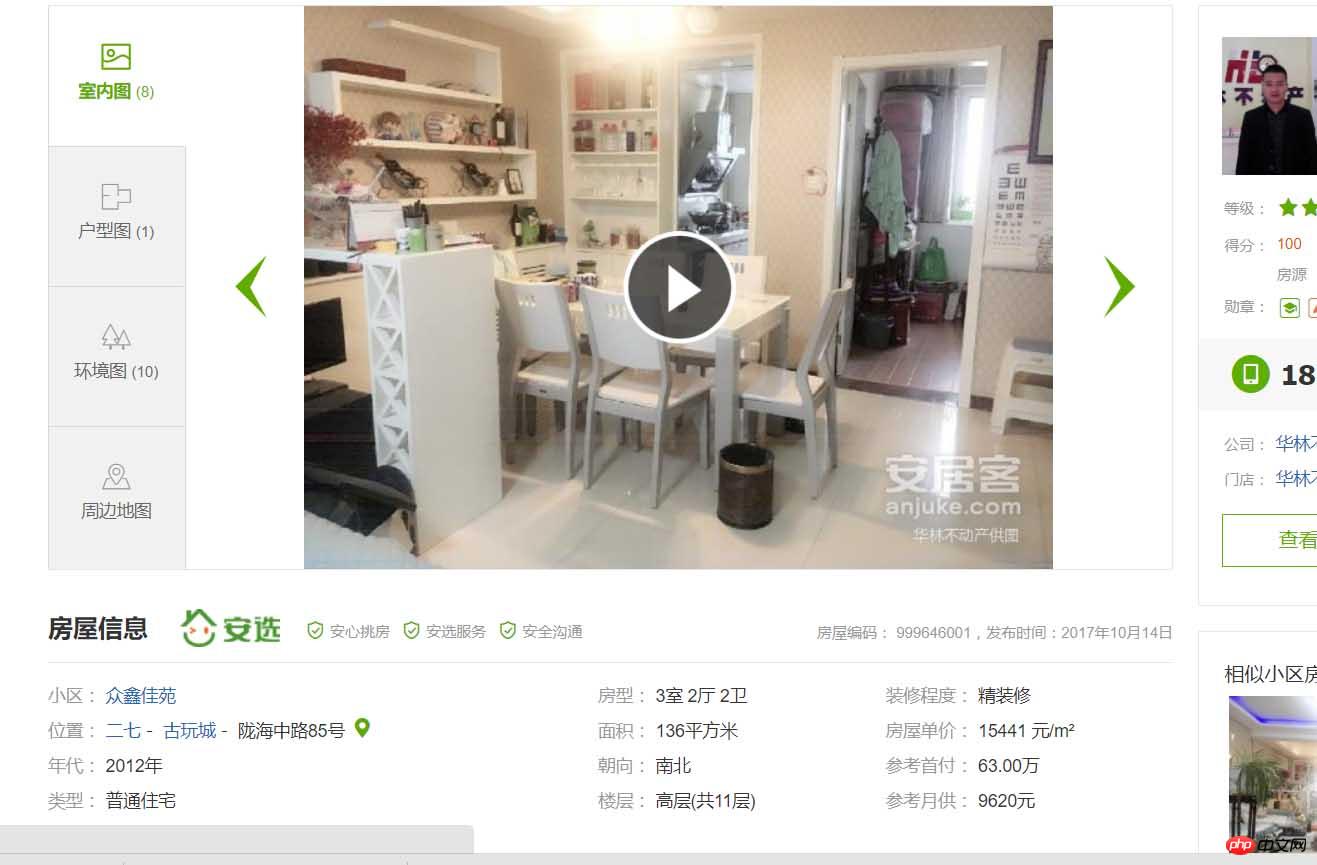
房源的详细信息。OK!那么我们要干嘛呢,就是把郑州这个地区的二手房房源信息都能拿到手,可以保存到数据库中,用来干嘛呢,作为一个地理人,还是有点用处的,这次就不说了好,正式开始,首先我采用python3.6 中的requests,BeautifulSoup模块来进行爬取页面,首先由requests模块进行请求:
# 网页的请求头
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
}
# url链接
url = 'https://zhengzhou.anjuke.com/sale/'
response = requests.get(url, headers=header)
print(response.text)执行后就会得到这个网站的html代码了
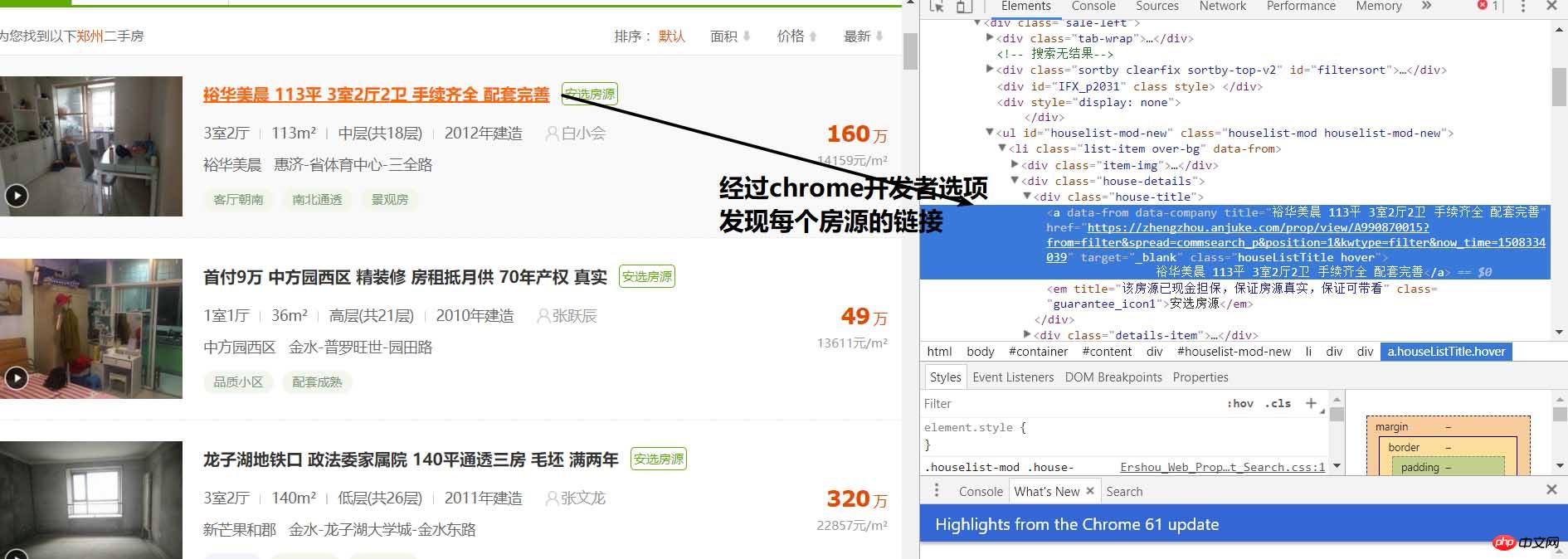
 通过分析可以得到每个房源都在class="list-item"的 li 标签中,那么我们就可以根据BeautifulSoup包进行提取
通过分析可以得到每个房源都在class="list-item"的 li 标签中,那么我们就可以根据BeautifulSoup包进行提取
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup = BeautifulSoup(response.text, 'html.parser')
result_li = soup.find_all('li', {'class': 'list-item'})
for i in result_li:
print(i)通过打印就能进一步减少了code量,好,继续提取
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup = BeautifulSoup(response.text, 'html.parser')
result_li = soup.find_all('li', {'class': 'list-item'})
# 进行循环遍历其中的房源详细列表
for i in result_li:
# 由于BeautifulSoup传入的必须为字符串,所以进行转换
page_url = str(i)
soup = BeautifulSoup(page_url, 'html.parser')
# 由于通过class解析的为一个列表,所以只需要第一个参数
result_href = soup.find_all('a', {'class': 'houseListTitle'})[0]
print(result_href.attrs['href'])这样,我们就能看到一个个的url了,是不是很喜欢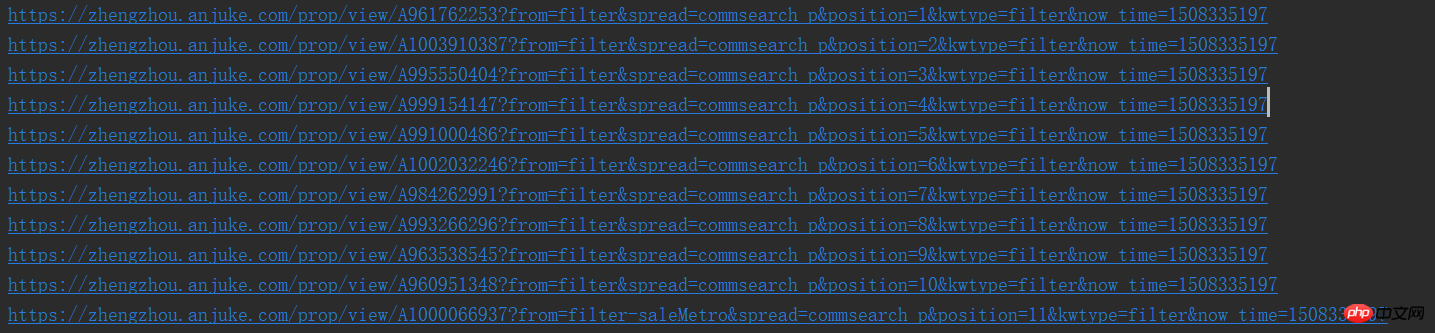
好了,按正常的逻辑就要进入页面开始分析详细页面了,但是爬取完后如何进行下一页的爬取呢所以,我们就需要先分析该页面是否有下一页
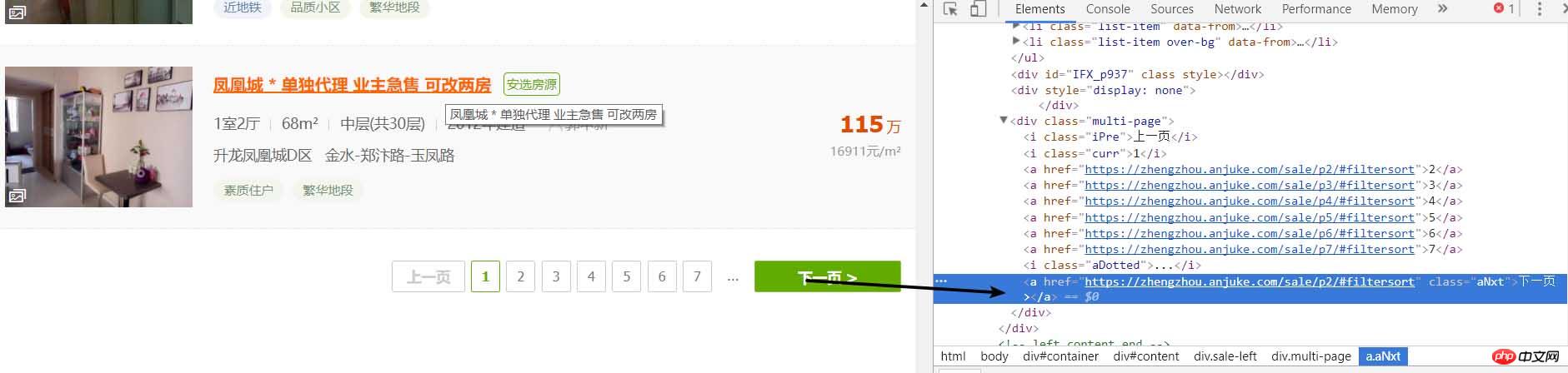
同样的方法就可以发现下一页同样是如此的简单,那么咱们就可以还是按原来的配方原来的味道继续
# 进行下一页的爬取
result_next_page = soup.find_all('a', {'class': 'aNxt'})
if len(result_next_page) != 0:
print(result_next_page[0].attrs['href'])
else:
print('没有下一页了')因为当存在下一页的时候,网页中就是一个a标签,如果没有的话,就会成为i标签了,所以这样的就行,因此,我们就能完善一下,将以上这些封装为一个函数
import requests
from bs4 import BeautifulSoup
# 网页的请求头
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
}
def get_page(url):
response = requests.get(url, headers=header)
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup = BeautifulSoup(response.text, 'html.parser')
result_li = soup.find_all('li', {'class': 'list-item'})
# 进行下一页的爬取
result_next_page = soup.find_all('a', {'class': 'aNxt'})
if len(result_next_page) != 0:
# 函数进行递归
get_page(result_next_page[0].attrs['href'])
else:
print('没有下一页了')
# 进行循环遍历其中的房源详细列表
for i in result_li:
# 由于BeautifulSoup传入的必须为字符串,所以进行转换
page_url = str(i)
soup = BeautifulSoup(page_url, 'html.parser')
# 由于通过class解析的为一个列表,所以只需要第一个参数
result_href = soup.find_all('a', {'class': 'houseListTitle'})[0]
# 先不做分析,等一会进行详细页面函数完成后进行调用
print(result_href.attrs['href'])
if __name__ == '__main__':
# url链接
url = 'https://zhengzhou.anjuke.com/sale/'
# 页面爬取函数调用
get_page(url)好了,那么咱们就开始详细页面的爬取了
哎,怎么动不动就要断电了,大学的坑啊,先把结果附上,闲了在补充,
import requests
from bs4 import BeautifulSoup
# 网页的请求头
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
}
def get_page(url):
response = requests.get(url, headers=header)
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup_idex = BeautifulSoup(response.text, 'html.parser')
result_li = soup_idex.find_all('li', {'class': 'list-item'})
# 进行循环遍历其中的房源详细列表
for i in result_li:
# 由于BeautifulSoup传入的必须为字符串,所以进行转换
page_url = str(i)
soup = BeautifulSoup(page_url, 'html.parser')
# 由于通过class解析的为一个列表,所以只需要第一个参数
result_href = soup.find_all('a', {'class': 'houseListTitle'})[0]
# 详细页面的函数调用
get_page_detail(result_href.attrs['href'])
# 进行下一页的爬取
result_next_page = soup_idex.find_all('a', {'class': 'aNxt'})
if len(result_next_page) != 0:
# 函数进行递归
get_page(result_next_page[0].attrs['href'])
else:
print('没有下一页了')
# 进行字符串中空格,换行,tab键的替换及删除字符串两边的空格删除
def my_strip(s):
return str(s).replace(" ", "").replace("\n", "").replace("\t", "").strip()
# 由于频繁进行BeautifulSoup的使用,封装一下,很鸡肋
def my_Beautifulsoup(response):
return BeautifulSoup(str(response), 'html.parser')
# 详细页面的爬取
def get_page_detail(url):
response = requests.get(url, headers=header)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# 标题什么的一大堆,哈哈
result_title = soup.find_all('h3', {'class': 'long-title'})[0]
result_price = soup.find_all('span', {'class': 'light info-tag'})[0]
result_house_1 = soup.find_all('p', {'class': 'first-col detail-col'})
result_house_2 = soup.find_all('p', {'class': 'second-col detail-col'})
result_house_3 = soup.find_all('p', {'class': 'third-col detail-col'})
soup_1 = my_Beautifulsoup(result_house_1)
soup_2 = my_Beautifulsoup(result_house_2)
soup_3 = my_Beautifulsoup(result_house_3)
result_house_tar_1 = soup_1.find_all('dd')
result_house_tar_2 = soup_2.find_all('dd')
result_house_tar_3 = soup_3.find_all('dd')
'''
文博公寓,省实验中学,首付只需70万,大三房,诚心卖,价可谈 270万
宇泰文博公寓 金水-花园路-文博东路4号 2010年 普通住宅
3室2厅2卫 140平方米 南北 中层(共32层)
精装修 19285元/m² 81.00万
'''
print(my_strip(result_title.text), my_strip(result_price.text))
print(my_strip(result_house_tar_1[0].text),
my_strip(my_Beautifulsoup(result_house_tar_1[1]).find_all('p')[0].text),
my_strip(result_house_tar_1[2].text), my_strip(result_house_tar_1[3].text))
print(my_strip(result_house_tar_2[0].text), my_strip(result_house_tar_2[1].text),
my_strip(result_house_tar_2[2].text), my_strip(result_house_tar_2[3].text))
print(my_strip(result_house_tar_3[0].text), my_strip(result_house_tar_3[1].text),
my_strip(result_house_tar_3[2].text))
if __name__ == '__main__':
# url链接
url = 'https://zhengzhou.anjuke.com/sale/'
# 页面爬取函数调用
get_page(url)由于自己边写博客,边写的代码,所以get_page函数中进行了一些改变,就是下一页的递归调用需要放在函数后面,以及进行封装了两个函数没有介绍,
而且数据存储到mysql也没有写,所以后期会继续跟进的,thank you!!!
相关推荐:
Atas ialah kandungan terperinci python爬取安居客二手房网站数据方法分享. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1359
1359
 52
52

 Apakah fungsi jumlah bahasa C?
Apr 03, 2025 pm 02:21 PM
Apakah fungsi jumlah bahasa C?
Apr 03, 2025 pm 02:21 PM
Tiada fungsi jumlah terbina dalam dalam bahasa C, jadi ia perlu ditulis sendiri. Jumlah boleh dicapai dengan melintasi unsur -unsur array dan terkumpul: Versi gelung: SUM dikira menggunakan panjang gelung dan panjang. Versi Pointer: Gunakan petunjuk untuk menunjuk kepada unsur-unsur array, dan penjumlahan yang cekap dicapai melalui penunjuk diri sendiri. Secara dinamik memperuntukkan versi Array: Perlawanan secara dinamik dan uruskan memori sendiri, memastikan memori yang diperuntukkan dibebaskan untuk mengelakkan kebocoran ingatan.
 Siapa yang dibayar lebih banyak Python atau JavaScript?
Apr 04, 2025 am 12:09 AM
Siapa yang dibayar lebih banyak Python atau JavaScript?
Apr 04, 2025 am 12:09 AM
Tidak ada gaji mutlak untuk pemaju Python dan JavaScript, bergantung kepada kemahiran dan keperluan industri. 1. Python boleh dibayar lebih banyak dalam sains data dan pembelajaran mesin. 2. JavaScript mempunyai permintaan yang besar dalam perkembangan depan dan stack penuh, dan gajinya juga cukup besar. 3. Faktor mempengaruhi termasuk pengalaman, lokasi geografi, saiz syarikat dan kemahiran khusus.
 Cara menukar XML ke mp3
Apr 03, 2025 am 09:00 AM
Cara menukar XML ke mp3
Apr 03, 2025 am 09:00 AM
Langkah -langkah untuk menukar XML ke MP3 termasuk: Ekstrak data audio dari XML: menghuraikan fail XML, cari rentetan pengekodan base64 yang mengandungi data audio, dan ekodkannya ke dalam format binari. Kodkan data audio ke mp3: Pasang pengekod MP3 dan tetapkan parameter pengekodan, encang data audio binari ke format MP3, dan simpannya ke fail.
 Adakah distinctidistinguish berkaitan?
Apr 03, 2025 pm 10:30 PM
Adakah distinctidistinguish berkaitan?
Apr 03, 2025 pm 10:30 PM
Walaupun berbeza dan berbeza berkaitan dengan perbezaan, ia digunakan secara berbeza: berbeza (kata sifat) menggambarkan keunikan perkara itu sendiri dan digunakan untuk menekankan perbezaan antara perkara; Berbeza (kata kerja) mewakili tingkah laku atau keupayaan perbezaan, dan digunakan untuk menggambarkan proses diskriminasi. Dalam pengaturcaraan, berbeza sering digunakan untuk mewakili keunikan unsur -unsur dalam koleksi, seperti operasi deduplikasi; Berbeza dicerminkan dalam reka bentuk algoritma atau fungsi, seperti membezakan ganjil dan bahkan nombor. Apabila mengoptimumkan, operasi yang berbeza harus memilih algoritma dan struktur data yang sesuai, sementara operasi yang berbeza harus mengoptimumkan perbezaan antara kecekapan logik dan memberi perhatian untuk menulis kod yang jelas dan mudah dibaca.
 Bagaimana memahami! X dalam c?
Apr 03, 2025 pm 02:33 PM
Bagaimana memahami! X dalam c?
Apr 03, 2025 pm 02:33 PM
! X Memahami! X adalah bukan operator logik dalam bahasa C. Ia booleans nilai x, iaitu, perubahan benar kepada perubahan palsu, palsu kepada benar. Tetapi sedar bahawa kebenaran dan kepalsuan dalam C diwakili oleh nilai berangka dan bukannya jenis Boolean, bukan sifar dianggap sebagai benar, dan hanya 0 dianggap sebagai palsu. Oleh itu ,! X memperkatakan nombor negatif sama seperti nombor positif dan dianggap benar.
 Bolehkah Pengenal Pengguna Bahasa C mengandungi ruang?
Apr 03, 2025 pm 01:51 PM
Bolehkah Pengenal Pengguna Bahasa C mengandungi ruang?
Apr 03, 2025 pm 01:51 PM
Pengenal bahasa C tidak boleh mengandungi ruang kerana mereka boleh menyebabkan kekeliruan dan kesukaran dalam mengekalkan. Peraturan khusus adalah seperti berikut: mereka mesti bermula dengan huruf atau garis bawah. Boleh mengandungi huruf, nombor, atau garis bawah. Tidak boleh mengandungi watak haram (seperti simbol khas).
 Bagaimana cara menggunakan nomenclature ular dalam bahasa c?
Apr 03, 2025 pm 01:03 PM
Bagaimana cara menggunakan nomenclature ular dalam bahasa c?
Apr 03, 2025 pm 01:03 PM
Dalam bahasa C, nomenclature ular adalah konvensyen gaya pengekodan, yang menggunakan garis bawah untuk menyambungkan beberapa perkataan untuk membentuk nama pembolehubah atau nama fungsi untuk meningkatkan kebolehbacaan. Walaupun ia tidak akan menjejaskan kompilasi dan operasi, penamaan panjang, isu sokongan IDE, dan bagasi sejarah perlu dipertimbangkan.
 Apakah jumlah maksud dalam bahasa C?
Apr 03, 2025 pm 02:36 PM
Apakah jumlah maksud dalam bahasa C?
Apr 03, 2025 pm 02:36 PM
Tiada fungsi jumlah terbina dalam dalam C untuk jumlah, tetapi ia boleh dilaksanakan dengan: menggunakan gelung untuk mengumpul unsur-unsur satu demi satu; menggunakan penunjuk untuk mengakses dan mengumpul unsur -unsur satu demi satu; Untuk jumlah data yang besar, pertimbangkan pengiraan selari.
