

CSS选择器字段解析的实现方法

根据上面所学的CSS基础语法知识,现在来实现字段的解析。首先还是解析标题。打开网页开发者工具,找到标题所对应的源代码。本文主要介绍了CSS选择器实现字段解析的相关资料,需要的朋友可以参考下,希望能帮助到大家
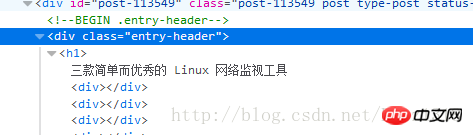
发现是在p class="entry-header"下面的h1节点中,于是打开scrapy shell 进行调试

但是我不想要
这种标签该咋办,这时候就要使用CSS选择器中的伪类方法。如下所示。

注意的是两个冒号。使用CSS选择器真的很方便。同理我用CSS实现字段解析。代码如下
# -*- coding: utf-8 -*-
import scrapy
import re
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/113549/']
def parse(self, response):
# title = response.xpath('//p[@class = "entry-header"]/h1/text()').extract()[0]
# create_date = response.xpath("//p[@class = 'entry-meta-hide-on-mobile']/text()").extract()[0].strip().replace("·","").strip()
# praise_numbers = response.xpath("//span[contains(@class,'vote-post-up')]/h10/text()").extract()[0]
# fav_nums = response.xpath("//span[contains(@class,'bookmark-btn')]/text()").extract()[0]
# match_re = re.match(".*?(\d+).*",fav_nums)
# if match_re:
# fav_nums = match_re.group(1)
# comment_nums = response.xpath("//a[@href='#article-comment']/span").extract()[0]
# match_re = re.match(".*?(\d+).*", comment_nums)
# if match_re:
# comment_nums = match_re.group(1)
# content = response.xpath("//p[@class='entry']").extract()[0]
#通过CSS选择器提取字段
title = response.css(".entry-header h1::text").extract()[0]
create_date = response.css(".entry-meta-hide-on-mobile::text").extract()[0].strip().replace("·","").strip()
praise_numbers = response.css(".vote-post-up h10::text").extract()[0]
fav_nums = response.css("span.bookmark-btn::text").extract()[0]
match_re = re.match(".*?(\d+).*", fav_nums)
if match_re:
fav_nums = match_re.group(1)
comment_nums = response.css("a[href='#article-comment'] span::text").extract()[0]
match_re = re.match(".*?(\d+).*", comment_nums)
if match_re:
comment_nums = match_re.group(1)
content = response.css("p.entry").extract()[0]
tags = response.css("p.entry-meta-hide-on-mobile a::text").extract()[0]
pass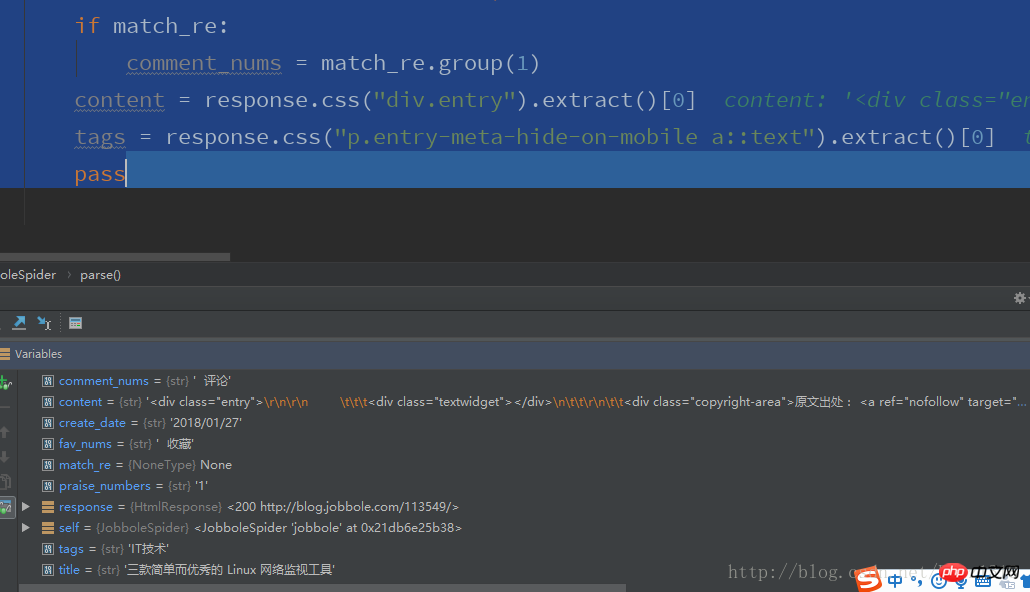
相关推荐:
Atas ialah kandungan terperinci CSS选择器字段解析的实现方法. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Cara memasukkan gambar di bootstrap
Apr 07, 2025 pm 03:30 PM
Cara memasukkan gambar di bootstrap
Apr 07, 2025 pm 03:30 PM
Terdapat beberapa cara untuk memasukkan imej dalam bootstrap: masukkan imej secara langsung, menggunakan tag HTML IMG. Dengan komponen imej bootstrap, anda boleh memberikan imej yang responsif dan lebih banyak gaya. Tetapkan saiz imej, gunakan kelas IMG-cecair untuk membuat imej boleh disesuaikan. Tetapkan sempadan, menggunakan kelas IMG-Sempadan. Tetapkan sudut bulat dan gunakan kelas IMG-bulat. Tetapkan bayangan, gunakan kelas bayangan. Saiz semula dan letakkan imej, menggunakan gaya CSS. Menggunakan imej latar belakang, gunakan harta CSS imej latar belakang.
 Cara Menyiapkan Kerangka untuk Bootstrap
Apr 07, 2025 pm 03:27 PM
Cara Menyiapkan Kerangka untuk Bootstrap
Apr 07, 2025 pm 03:27 PM
Untuk menubuhkan rangka kerja bootstrap, anda perlu mengikuti langkah -langkah ini: 1. Rujuk fail bootstrap melalui CDN; 2. Muat turun dan tuan rumah fail pada pelayan anda sendiri; 3. Sertakan fail bootstrap di HTML; 4. Menyusun sass/kurang seperti yang diperlukan; 5. Import fail tersuai (pilihan). Setelah persediaan selesai, anda boleh menggunakan sistem grid Bootstrap, komponen, dan gaya untuk membuat laman web dan aplikasi yang responsif.
 Cara menggunakan butang bootstrap
Apr 07, 2025 pm 03:09 PM
Cara menggunakan butang bootstrap
Apr 07, 2025 pm 03:09 PM
Bagaimana cara menggunakan butang bootstrap? Perkenalkan CSS bootstrap untuk membuat elemen butang dan tambahkan kelas butang bootstrap untuk menambah teks butang
 Cara Menulis Garis Pecah Di Bootstrap
Apr 07, 2025 pm 03:12 PM
Cara Menulis Garis Pecah Di Bootstrap
Apr 07, 2025 pm 03:12 PM
Terdapat dua cara untuk membuat garis perpecahan bootstrap: menggunakan tag, yang mewujudkan garis perpecahan mendatar. Gunakan harta sempadan CSS untuk membuat garis perpecahan gaya tersuai.
 Cara mengubah saiz bootstrap
Apr 07, 2025 pm 03:18 PM
Cara mengubah saiz bootstrap
Apr 07, 2025 pm 03:18 PM
Untuk menyesuaikan saiz unsur-unsur dalam bootstrap, anda boleh menggunakan kelas dimensi, yang termasuk: menyesuaikan lebar: .col-, .w-, .mw-adjust ketinggian: .h-, .min-h-, .max-h-
 Cara melihat tarikh bootstrap
Apr 07, 2025 pm 03:03 PM
Cara melihat tarikh bootstrap
Apr 07, 2025 pm 03:03 PM
Jawapan: Anda boleh menggunakan komponen pemetik tarikh bootstrap untuk melihat tarikh di halaman. Langkah -langkah: Memperkenalkan rangka kerja bootstrap. Buat kotak input pemilih Tarikh dalam HTML. Bootstrap secara automatik akan menambah gaya kepada pemilih. Gunakan JavaScript untuk mendapatkan tarikh yang dipilih.
 Peranan HTML, CSS, dan JavaScript: Tanggungjawab Teras
Apr 08, 2025 pm 07:05 PM
Peranan HTML, CSS, dan JavaScript: Tanggungjawab Teras
Apr 08, 2025 pm 07:05 PM
HTML mentakrifkan struktur web, CSS bertanggungjawab untuk gaya dan susun atur, dan JavaScript memberikan interaksi dinamik. Ketiga melaksanakan tugas mereka dalam pembangunan web dan bersama -sama membina laman web yang berwarna -warni.
 Cara menggunakan bootstrap di vue
Apr 07, 2025 pm 11:33 PM
Cara menggunakan bootstrap di vue
Apr 07, 2025 pm 11:33 PM
Menggunakan bootstrap dalam vue.js dibahagikan kepada lima langkah: Pasang bootstrap. Import bootstrap di main.js. Gunakan komponen bootstrap secara langsung dalam templat. Pilihan: Gaya tersuai. Pilihan: Gunakan pemalam.
