

本文主要和大家介绍Web技术如何实现移动监测,移动侦测,一般也叫运动检测,常用于无人值守监控录像和自动报警。通过摄像头按照不同帧率采集得到的图像会被 CPU 按照一定算法进行计算和比较,当画面有变化时,如有人走过,镜头被移动,计算比较结果得出的数字会超过阈值并指示系统能自动作出相应的处理
Web技术实现移动监测的介绍
由上述引用语句可得出“移动监测”需要以下要素:
一个拥有摄像头的计算机用于判断移动的算法移动后的处理
注:本文涉及的所有案例均基于 PC/Mac 较新版本的 Chrome / Firefox 浏览器,部分案例需配合摄像头完成,所有截图均保存在本地。
对方不想和你说话,并向你扔来一个链接:
综合案例
该案例有以下两个功能:
拍好 POST 后的 1 秒会进行拍照静止 1 秒后音乐会停止,产生移动会恢复播放状态
上述案例也许并不能直接体现出『移动监测』的实际效果和原理,下面再看看这个案例。
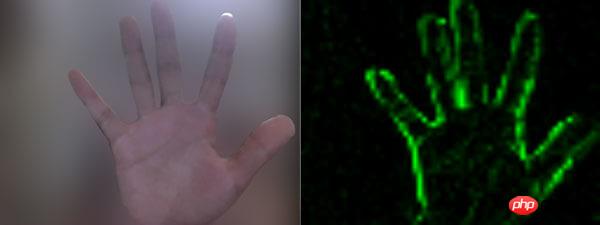
像素差异
案例的左侧是视频源,而右侧则是移动后的像素处理(像素化、判断移动和只保留绿色等)。
因为是基于 Web 技术,所以视频源采用 WebRTC,像素处理则采用 Canvas。
视频源
不依赖 Flash 或 Silverlight,我们使用 WebRTC (Web Real-Time Communications) 中的 navigator.getUserMedia() API,该 API 允许 Web 应用获取用户的摄像头与麦克风流(stream)。
示例代码如下:
<!-- 若不加 autoplay,则会停留在第一帧 -->
<video id="video" autoplay></video>
// 具体参数含义可看相关文档。
const constraints = {
audio: false,
video: {
width: 640,
height: 480
}
}
navigator.mediaDevices.getUserMedia(constraints)
.then(stream => {
// 将视频源展示在 video 中
video.srcObject = stream
})
.catch(err => {
console.log(err)
})对于兼容性问题,Safari 11 开始支持 WebRTC 了。具体可查看 caniuse。
像素处理
在得到视频源后,我们就有了判断物体是否移动的素材。当然,这里并没有采用什么高深的识别算法,只是利用连续两帧截图的像素差异来判断物体是否发生移动(严格来说,是画面的变化)。
截图
获取视频源截图的示例代码:
const video = document.getElementById('video')
const canvas = document.createElement('canvas')
const ctx = canvas.getContext('2d')
canvas.width = 640
canvas.height = 480
// 获取视频中的一帧
function capture () {
ctx.drawImage(video, 0, 0, canvas.width, canvas.height)
// ...其它操作
}得出截图间的差异
对于两张图的像素差异,在 凹凸实验室 的 《“等一下,我碰!”——常见的2D碰撞检测》 这篇博文中所提及的“像素检测”碰撞算法是解决办法之一。该算法是通过遍历两个离屏画布(offscreen canvas)同一位置的像素点的透明度是否同时大于 0,来判断碰撞与否。当然,这里要改为『同一位置的像素点是否不同(或差异小于某阈值)』来判断移动与否。
但上述方式稍显麻烦和低效,这里我们采用 ctx.globalCompositeOperation = 'difference' 指定画布新增元素(即第二张截图与第一张截图)的合成方式,得出两张截图的差异部分。
体验链接>>
示例代码:
function diffTwoImage () {
// 设置新增元素的合成方式
ctx.globalCompositeOperation = 'difference'
// 清除画布
ctx.clearRect(0, 0, canvas.width, canvas.height)
// 假设两张图像尺寸相等
ctx.drawImage(firstImg, 0, 0)
ctx.drawImage(secondImg, 0, 0)
}
两张图的差异
体验上述案例后,是否有种当年玩“QQ游戏《大家来找茬》”的感觉。另外,这个案例可能还适用于以下两种情况:
当你不知道设计师前后两次给你的设计稿有何差异时
想查看两个浏览器对同一个网页的渲染有何差异时何时为一个“动作”
由上述“两张图像差异”的案例中可得:黑色代表该位置上的像素未发生改变,而像素越明亮则代表该点的“动作”越大。因此,当连续两帧截图合成后有明亮的像素存在时,即为一个“动作”的产生。但为了让程序不那么“敏感”,我们可以设定一个阈值。当明亮像素的个数大于该阈值时,才认为产生了一个“动作”。当然,我们也可以剔除“不足够明亮”的像素,以尽可能避免外界环境(如灯光等)的影响。
想要获取 Canvas 的像素信息,需要通过 ctx.getImageData(sx, sy, sw, sh),该 API 会返回你所指定画布区域的像素对象。该对象包含 data、width、height。其中 data 是一个含有每个像素点 RGBA 信息的一维数组,如下图所示。

含有 RGBA 信息的一维数组
获取到特定区域的像素后,我们就能对每个像素进行处理(如各种滤镜效果)。处理完后,则可通过 ctx.putImageData() 将其渲染在指定的 Canvas 上。
扩展:由于 Canvas 目前没有提供“历史记录”的功能,如需实现“返回上一步”操作,则可通过 getImageData 保存上一步操作,当需要时则可通过 putImageData 进行复原。
示例代码:
let imageScore = 0
const rgba = imageData.data
for (let i = 0; i < rgba.length; i += 4) {
const r = rgba[i] / 3
const g = rgba[i + 1] / 3
const b = rgba[i + 2] / 3
const pixelScore = r + g + b
// 如果该像素足够明亮
if (pixelScore >= PIXEL_SCORE_THRESHOLD) {
imageScore++
}
}
// 如果明亮的像素数量满足一定条件
if (imageScore >= IMAGE_SCORE_THRESHOLD) {
// 产生了移动
}在上述案例中,你也许会注意到画面是『绿色』的。其实,我们只需将每个像素的红和蓝设置为 0,即将 RGBA 的 r = 0; b = 0 即可。这样就会像电影的某些镜头一样,增加了科技感和神秘感。
体验地址>>
const rgba = imageData.data
for (let i = 0; i < rgba.length; i += 4) {
rgba[i] = 0 // red
rgba[i + 2] = 0 // blue
}
ctx.putImageData(imageData, 0, 0)
将 RGBA 中的 R 和 B 置为 0
跟踪“移动物体”
有了明亮的像素后,我们就要找出其 x 坐标的最小值与 y 坐标的最小值,以表示跟踪矩形的左上角。同理,x 坐标的最大值与 y 坐标的最大值则表示跟踪矩形的右下角。至此,我们就能绘制出一个能包围所有明亮像素的矩形,从而实现跟踪移动物体的效果。
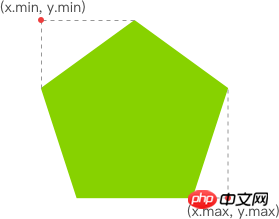
找出跟踪矩形的左上角和右下角
体验链接>>
示例代码:
function processDiff (imageData) {
const rgba = imageData.data
let score = 0
let pixelScore = 0
let motionBox = 0
// 遍历整个 canvas 的像素,以找出明亮的点
for (let i = 0; i < rgba.length; i += 4) {
pixelScore = (rgba[i] + rgba[i+1] + rgba[i+2]) / 3
// 若该像素足够明亮
if (pixelScore >= 80) {
score++
coord = calcCoord(i)
motionBox = calcMotionBox(montionBox, coord.x, coord.y)
}
}
return {
score,
motionBox
}
}
// 得到左上角和右下角两个坐标值
function calcMotionBox (curMotionBox, x, y) {
const motionBox = curMotionBox || {
x: { min: coord.x, max: x },
y: { min: coord.y, max: y }
}
motionBox.x.min = Math.min(motionBox.x.min, x)
motionBox.x.max = Math.max(motionBox.x.max, x)
motionBox.y.min = Math.min(motionBox.y.min, y)
motionBox.y.max = Math.max(motionBox.y.max, y)
return motionBox
}
// imageData.data 是一个含有每个像素点 rgba 信息的一维数组。
// 该函数是将上述一维数组的任意下标转为 (x,y) 二维坐标。
function calcCoord(i) {
return {
x: (i / 4) % diffWidth,
y: Math.floor((i / 4) / diffWidth)
}
}在得到跟踪矩形的左上角和右下角的坐标值后,通过 ctx.strokeRect(x, y, width, height) API 绘制出矩形即可。
ctx.lineWidth = 6 ctx.strokeRect( diff.motionBox.x.min + 0.5, diff.motionBox.y.min + 0.5, diff.motionBox.x.max - diff.motionBox.x.min, diff.motionBox.y.max - diff.motionBox.y.min )

这是理想效果,实际效果请打开 体验链接
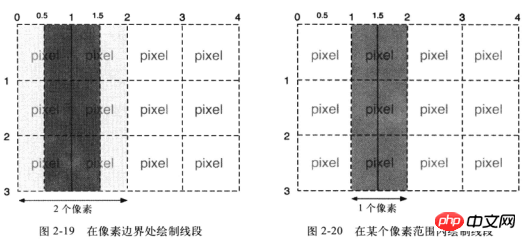
扩展:为什么上述绘制矩形的代码中的
x、y要加0.5呢?一图胜千言:
性能缩小尺寸
在上一个章节提到,我们需要通过对 Canvas 每个像素进行处理,假设 Canvas 的宽为 640,高为 480,那么就需要遍历 640 * 480 = 307200 个像素。而在监测效果可接受的前提下,我们可以将需要进行像素处理的 Canvas 缩小尺寸,如缩小 10 倍。这样需要遍历的像素数量就降低 100 倍,从而提升性能。
体验地址>>
示例代码:
const motionCanvas // 展示给用户看 const backgroundCanvas // offscreen canvas 背后处理数据 motionCanvas.width = 640 motionCanvas.height = 480 backgroundCanvas.width = 64 backgroundCanvas.height = 48

尺寸缩小 10 倍
定时器
我们都知道,当游戏以『每秒60帧』运行时才能保证一定的体验。但对于我们目前的案例来说,帧率并不是我们追求的第一位。因此,每 100 毫秒(具体数值取决于实际情况)取当前帧与前一帧进行比较即可。
另外,因为我们的动作一般具有连贯性,所以可取该连贯动作中幅度最大的(即“分数”最高)或最后一帧动作进行处理即可(如存储到本地或分享到朋友圈)。
延伸
至此,用 Web 技术实现简易的“移动监测”效果已基本讲述完毕。由于算法、设备等因素的限制,该效果只能以 2D 画面为基础来判断物体是否发生“移动”。而微软的 Xbox、索尼的 PS、任天堂的 Wii 等游戏设备上的体感游戏则依赖于硬件。以微软的 Kinect 为例,它为开发者提供了可跟踪最多六个完整骨骼和每人 25 个关节等强大功能。利用这些详细的人体参数,我们就能实现各种隔空的『手势操作』,如画圈圈诅咒某人。
下面几个是通过 Web 使用 Kinect 的库:
DepthJS:以浏览器插件形式提供数据访问。
Node-Kinect2: 以 Nodejs 搭建服务器端,提供数据比较完整,实例较多。
ZigFu:支持 H5、U3D、Flash,API较为完整。
Kinect-HTML5:Kinect-HTML5 用 C# 搭建服务端,提供色彩数据、深度数据和骨骼数据。
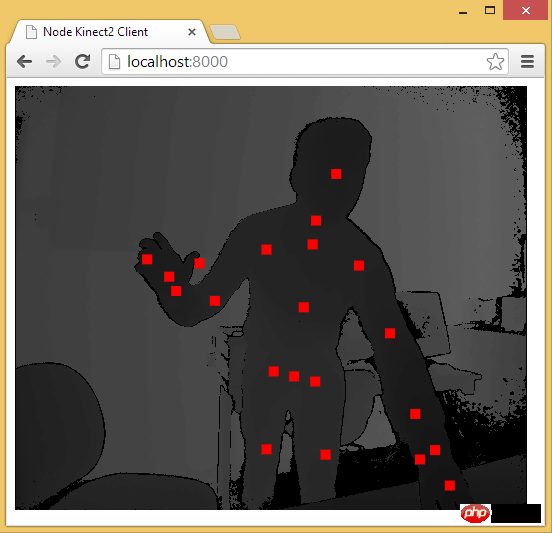
通过 Node-Kinect2 获取骨骼数据
相关推荐:
Atas ialah kandungan terperinci Web技术如何实现移动监测. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Perbezaan antara MATE60 dan MATE60PRO
Perbezaan antara MATE60 dan MATE60PRO
 Bagaimana pula dengan Ouyi Exchange?
Bagaimana pula dengan Ouyi Exchange?
 Apakah yang perlu saya lakukan jika video web tidak boleh dibuka?
Apakah yang perlu saya lakukan jika video web tidak boleh dibuka?
 Ringkasan pengetahuan asas java
Ringkasan pengetahuan asas java
 laluan tambah pengenalan arahan
laluan tambah pengenalan arahan
 Buka folder rumah pada mac
Buka folder rumah pada mac
 gt540
gt540
 Penggunaan asas pernyataan sisipan
Penggunaan asas pernyataan sisipan
 Bagaimana untuk mendapatkan Douyin Xiaohuoren
Bagaimana untuk mendapatkan Douyin Xiaohuoren








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



