

有时候因为工作、自身的需求,我们都会去浏览不同网站去获取我们需要的数据,于是爬虫应运而生,下面是开发一个简单爬虫的经过与遇到的问题。开发一个爬虫,首先你要知道你的这个爬虫是要用来做什么的。我是要用来去不同网站找特定关键字的文章,并获取它的链接,以便我快速阅读。
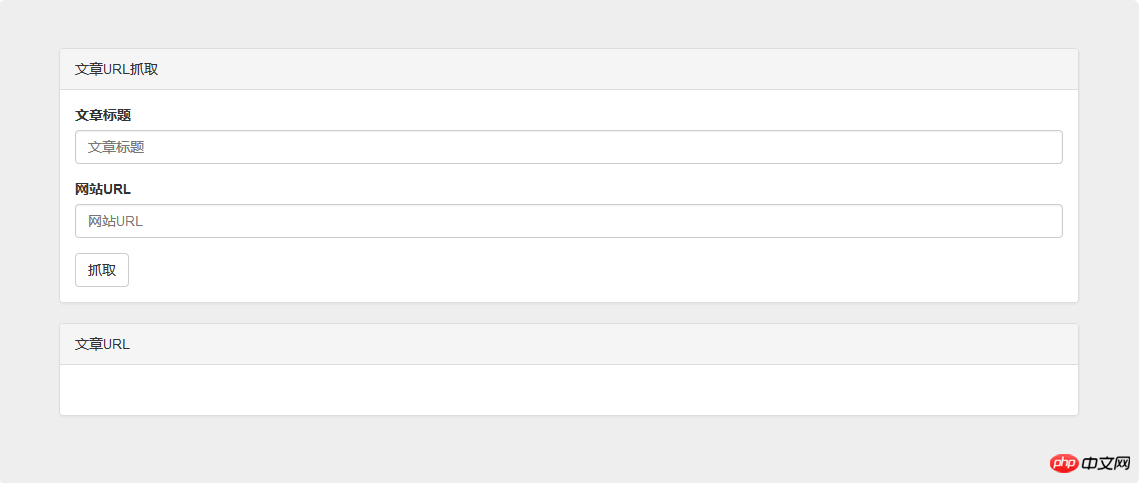
按照个人习惯,我首先要写一个界面,理清下思路。
1、去不同网站。那么我们需要一个url输入框。
2、找特定关键字的文章。那么我们需要一个文章标题输入框。
3、获取文章链接。那么我们需要一个搜索结果的显示容器。
[xhtml] view plain copy
<p class="jumbotron" id="mainJumbotron">
<p class="panel panel-default">
<p class="panel-heading">文章URL抓取</p>
<p class="panel-body">
<p class="form-group">
<label for="article_title">文章标题</label>
<input type="text" class="form-control" id="article_title" placeholder="文章标题">
</p>
<p class="form-group">
<label for="website_url">网站URL</label>
<input type="text" class="form-control" id="website_url" placeholder="网站URL">
</p>
<button type="submit" class="btn btn-default">抓取</button>
</p>
</p>
<p class="panel panel-default">
<p class="panel-heading">文章URL</p>
<p class="panel-body">
<h3></h3>
</p>
</p>
</p>直接上代码,然后加上自己的一些样式调整,界面就完成啦:
那么接下来就是功能的实现了,我用PHP来写,首先第一步就是获取网站的html代码,获取html代码的方式也有很多,我就不一一介绍了,这里用了curl来获取,传入网站url就能得到html代码啦:
[xhtml] view plain copy
private function get_html($url){
$ch = curl_init();
$timeout = 10;
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36');
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout);
$html = curl_exec($ch);
return $html;
}虽然得到了html代码,但是很快你会遇到一个问题,那就是编码问题,这可能让你下一步的匹配无功而返,我们这里统一把得到的html内容转为utf8编码:
[php] view plain copy $coding = mb_detect_encoding($html); if ($coding != "UTF-8" || !mb_check_encoding($html, "UTF-8")) $html = mb_convert_encoding($html, 'utf-8', 'GBK,UTF-8,ASCII');
得到网站的html,要获取文章的url,那么下一步就是要匹配该网页下的所有a标签,需要用到正则表达式,经过多次测试,最终得到一个比较靠谱的正则表达式,不管a标签下结构多复杂,只要是a标签的都不放过:(最关键的一步)
[php] view plain copy $pattern = '|<a[^>]*>(.*)</a>|isU'; preg_match_all($pattern, $html, $matches);
匹配的结果在$matches中,它大概是这样的一个多维素组;
[js] view plain copy
array(2) {
[0]=>
array(*) {
[0]=>
string(*) "完整的a标签"
.
.
.
}
[1]=>
array(*) {
[0]=>
string(*) "与上面下标相对应的a标签中的内容"
}
}只要能得到这个数据,其他就完全可以操作啦,你可以遍历这个素组,找到你想要a标签,然后获取a标签相应的属性,想怎么操作就怎么操作啦,下面推荐一个类,让你更方便操作a标签:
[php] view plain copy
$dom = new DOMDocument();
@$dom->loadHTML($a);//$a是上面得到的一些a标签
$url = new DOMXPath($dom);
$hrefs = $url->evaluate('//a');
for ($i = 0; $i < $hrefs->length; $i++) {
$href = $hrefs->item($i);
$url = $href->getAttribute('href'); //这里获取a标签的href属性
}当然,这只是一种方式,你也可以通过正则表达式匹配你想要的信息,把数据玩出新花样。
得到并匹配得出你想要的结果,下一步当然就是传回前端将他们显示出来啦,把接口写好,然后前端用js获取数据,用jquery动态添加内容显示出来:
[php] view plain copy
var website_url = '你的接口地址';
$.getJSON(website_url,function(data){
if(data){
if(data.text == ''){
$('#article_url').html('<p><p>暂无该文章链接</p></p>');
return;
}
var string = '';
var list = data.text;
for (var j in list) {
var content = list[j].url_content;
for (var i in content) {
if (content[i].title != '') {
string += '<p class="item">' +
'<em>[<a href="http://' + list[j].website.web_url + '" target="_blank">' + list[j].website.web_name + '</a>]</em>' +
'<a href=" ' + content[i].url + '" target="_blank" class="web_url">' + content[i].title + '</a>' +
'</p>';
}
}
}
$('#article_url').html(string);
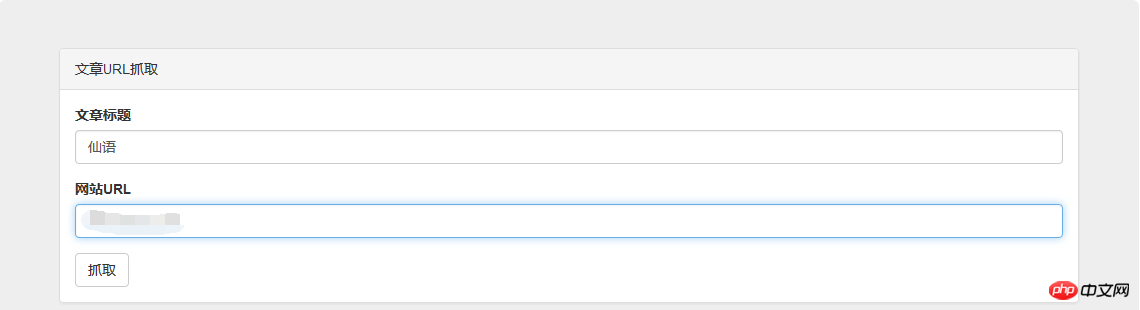
});上最终效果图:

Atas ialah kandungan terperinci PHP如何开发简单爬虫. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk membuka fail php
Bagaimana untuk membuka fail php
 Nodejs melaksanakan perangkak
Nodejs melaksanakan perangkak
 Bagaimana untuk mengalih keluar beberapa elemen pertama tatasusunan dalam php
Bagaimana untuk mengalih keluar beberapa elemen pertama tatasusunan dalam php
 Apa yang perlu dilakukan jika penyahserialisasian php gagal
Apa yang perlu dilakukan jika penyahserialisasian php gagal
 Bagaimana untuk menyambungkan php ke pangkalan data mssql
Bagaimana untuk menyambungkan php ke pangkalan data mssql
 Bagaimana untuk menyambung php ke pangkalan data mssql
Bagaimana untuk menyambung php ke pangkalan data mssql
 Bagaimana untuk memuat naik html
Bagaimana untuk memuat naik html
 Bagaimana untuk menyelesaikan aksara bercelaru dalam PHP
Bagaimana untuk menyelesaikan aksara bercelaru dalam PHP








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



