
这次给大家带来Node.js爬取豆瓣数据实例,Node.js爬取豆瓣数据的注意事项有哪些,下面就是实战案例,一起来看一下。
一直自以为自己vue还可以,一直自以为webpack还可以,今天在慕课逛node的时候,才发现,自己还差的很远。众所周知,vue-cli基于webpack,而webpack基于node,对node不了解,谈什么了解webpack。所以就自己给自己出了一道题,爬取豆瓣数据,目前还处于初级阶段。今天就浅谈爬取到豆瓣的数据,再另一个页面用自己的方式展现,后续会跟进。
1、需要解决的问题
搭建服务
怎么处理爬到的数据
怎么自动打开默认浏览器
2、搭建服务
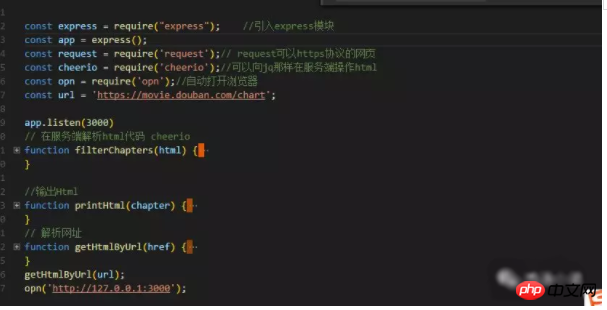
搭建服务有好几种方式,一开始我用的http,但是http有个弊端就是不能解析https协议的url,所以就用了express,解析https协议的网址我用了request包,豆瓣的网址是https的,
今天爬取的是https://movie.douban.com/chart这个网址;如下图,我要获取的有三个部分,图片、电影名字、电影链接.


3、怎么处理爬到的数据
我们用request爬到的数据,怎么处理呢?cheerio包可以让我们像Jq那样处理爬到的html数据。
①、首先解析数据,取到爬取网页的html数据;
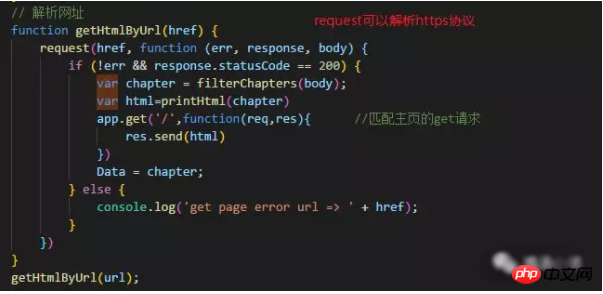
②、然后利用cheerio包操作爬到的数据,取到你想要的数据。
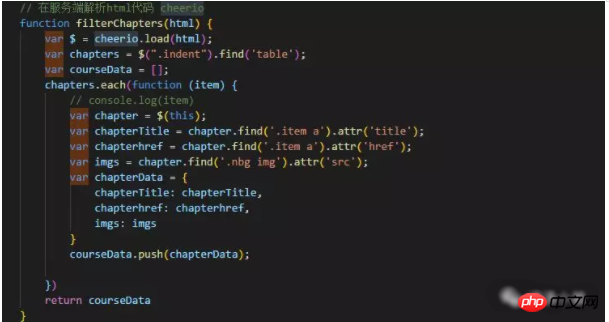
③、取到数据,创建html,输出到页面。如下图,我用的字符串拼接,办法有点笨,还没有找到更好的办法。
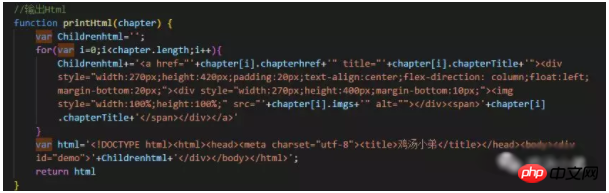
4、怎么自动打开默认浏览器
不知道你有没有看vue-cli中webpack的配置,自动打开浏览器,vue-cli用的opn包.

这个包用起来很方便,引入包,直接调用opn(url)即可;
5、展示
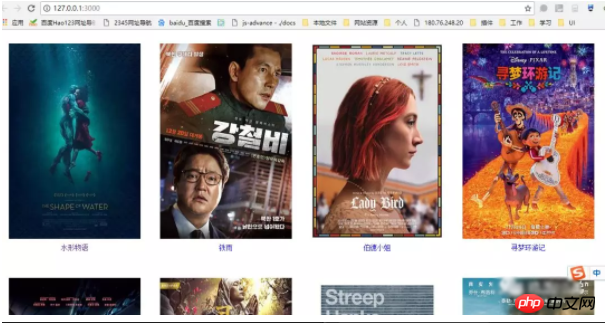
相信看了本文案例你已经掌握了方法,更多精彩请关注php中文网其它相关文章!
推荐阅读:
Atas ialah kandungan terperinci Node.js爬取豆瓣数据实例. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



