

正则模拟读取INI文件的步奏详解
这次给大家带来正则模拟读取INI文件的步奏详解,使用正则模拟读取INI文件的注意事项有哪些,下面就是实战案例,一起来看一下。
废话不多说了,直接给大家贴代码了,具体代码如下所示:
#include "stdio.h"
#include <sstream>
#include <iostream>
#include <fstream>
#include <regex>
using namespace std;
void Trim(char * str);
void lTrim(char * str);
void rTrim(char * str);
// 测试sscanf 和 正则表达式
// sscanf提供的这个扩展功能其实并不能真正称为正则表达式,因为他的书写还是离不开%
// []表示字符范围,{}表示重复次数,^表示取非,*表示跳过。所以上面这个url的解析可以写成下面这个样子:
//
//char url[] = "dv://192.168.1.253:65001/1/1"
//
//sscanf(url, "%[^://]%*c%*c%*c%[^:]%*c%d%*c%d%*c%d", protocol, ip, port, chn, type);
//
//解释一下
//先取得一个最长的字符串,但不包括字串 ://,于是protocol="dv\0";
//然后跳过三个字符,(%*c)其实就是跳过 ://
// 接着取一个字符串不包括字符串 : ,于是ip = 192.168.1.253,这里简化处理了,IP就当个字符串来弄,而且不做检查
// 然后跳过冒号取端口到port,再跳过 / 取通道号到chn,再跳过 / 取码流类型到type。
// c语言实现上例
void test1()
{
char url[] = "dv://192.168.1.253:65001/1/1";
char protocol[10];
char ip[17];
int port;
int chn;
int type;
sscanf(url, "%[^://]%*c%*c%*c%[^:]%*c%d%*c%d%*c%d", protocol, ip, &port, &chn, &type);
printf("%s, %s, %d, %d, %d\n", protocol, ip, port, chn, type);
}
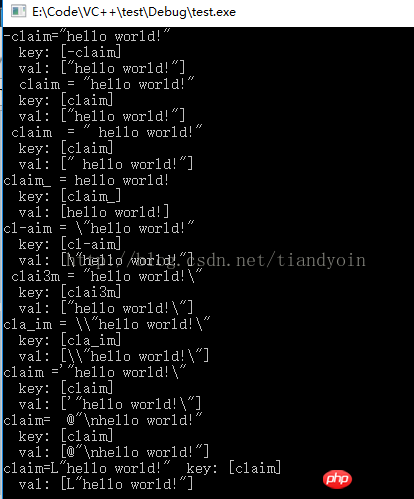
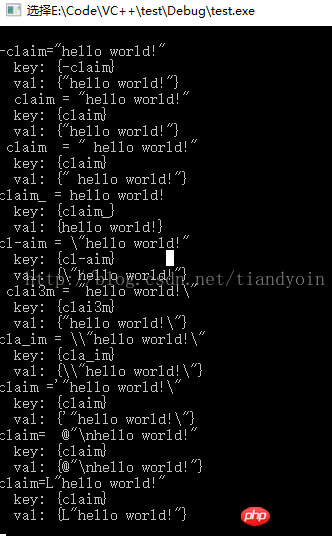
// 读取ini里某行字符串, 得到: hello world!
// 正常串1: -claim="hello world!"
// 正常串2: claim = "hello world!"
// 正常串3: claim = " hello world!"
// 正常串4: claim_ = hello world!
// 干扰串1: cl-aim = \"hello world!"
// 干扰串2: clai3m = "hello world!\"
// 干扰串3: cla_im = \\"hello world!\"
// 干扰串4: claim ='"hello world!\"
// 干扰串5: claim= @"\nhello world!"
// 干扰串6: claim=L"hello world!"
// 未处理1: claim[1] = 1
// 未处理1: claim[2] = 1
void test2()
{
char line[1000] = { 0 };
char val[1000] = { 0 };
char key[1000] = { 0 };
FILE *fp = fopen("1.txt", "r");
if (NULL == fp)
{
printf("failed to open 1.txt\n");
return ;
}
while (!feof(fp))
{
memset(line, 0, sizeof(line));
fgets(line, sizeof(line) - 1, fp); // 包含了每行的\n
printf("%s", line);
Trim(line);
// 提取等号之前的内容
memset(key, 0, sizeof(key));
// sscanf使用的format不是正则表达式,不能用 \\s 表示各种空白符,即空格或\t,\n,\r,\f
sscanf(line, "%[^ \t\n\r\f=]", key);
//sscanf(line, "%*[^a-zA-Z0-9_-]%[^ \t\n\r\f=]", key);
printf(" key: [%s]\n", key);
// 提取等号之后的内容
memset(val, 0, sizeof(val));
sscanf(line, "%*[^=]%*c%[^\n]", val); // 不包含了每行的换行符
Trim(val);
printf(" val: [%s]\n", val);
// 去除两边双引号
// ...
// 插入map
// map[key]=value;
// string 转 其它类型
// atoi, atol, atof
}
printf("\n");
fclose(fp);
}
// 上例的C++实现
template<class T1, class T2>
inline T1 parseTo(const T2 t)
{
static stringstream sstream;
T1 r;
sstream << t;
sstream >> r;
sstream.clear();
return r;
}
void test3()
{
char val[1000] = { 0 };
char key[1000] = { 0 };
ifstream fin("1.txt");
string line;
if (fin)
{
while (getline(fin, line)) // line中不包括每行的换行符
{
cout << line << endl;
/// 提取等号之前的内容
// 第1组()表示任意个空格字符,第2组()表示单词(可带_或-),
// 第3组()表示1个以上的空格字符(或=),最后以任意字符串结尾
regex reg("^([\\s]*)([\\w\\-\\_]+)([\\s=]+).*$");
// 取第2组代替原串
string key = regex_replace(line, reg, "$2");
cout << " key: {" << key << "}" << endl;
/// 提取等号之后的内容
// 第1组()表示任意个空格字符,第2组()表示单词(可带_或-),
// 第3组()表示1个以上的空格字符(或=),第4组()表示任意个字符,
// 第5组()表示以任意个空格字符(或回车换行符)结尾。
reg = regex("^([\\s]*)([\\w\\-\\_]+)([\\s=]+)(.*)([\\s\\r\\n]*)$");
// 取第4组代替原串
string val = regex_replace(line, reg, "$4");
cout << " val: {" << val << "}" << endl;
// 去除两边双引号
// ...
// 插入map
// map[key]=value;
// string 转 其它类型
// int i = parseTo<int>("123");
// float f = parseTo<float>("1.23");
// string str = parseTo<string>(123);
}
}
else // 没有该文件
{
cout << "no such file" << endl;
}
}
void main()
{
//test1();
test2();
test3();
}
void lTrim(char * str)
{
int i, len;
len = strlen(str);
for (i = 0; i<len; i++)
{
if (str[i] != ' ' && str[i] != '\t' && str[i] != '\n' && str[i] != '\r' && str[i] != '\f') break;
}
memmove(str, str + i, len - i + 1);
return;
}
void rTrim(char * str)
{
int i, len;
len = strlen(str);
for (i = len - 1; i >= 0; i--)
{
if ((str[i] != ' ') && (str[i] != 0x0a) && (str[i] != 0x0d) && (str[i] != '\t') && (str[i] != '\f')) break;
}
str[i + 1] = 0;
return;
}
void Trim(char * str)
{
int i, len;
//先去除左边的空格
len = strlen(str);
for (i = 0; i<len; i++)
{
if (str[i] != ' ' && str[i] != '\t' && str[i] != '\n' && str[i] != '\r' && str[i] != '\f') break;
}
memmove(str, str + i, len - i + 1);
//再去除右边的空格
len = strlen(str);
for (i = len - 1; i >= 0; i--)
{
if (str[i] != ' ' && str[i] != '\t' && str[i] != '\n' && str[i] != '\r' && str[i] != '\f') break;
}
str[i + 1] = 0;
return;
}
/*
void Trim(char * str)
{
lTrim(str);
rTrim(str);
}
*/

相信看了本文案例你已经掌握了方法,更多精彩请关注php中文网其它相关文章!
推荐阅读:
Atas ialah kandungan terperinci 正则模拟读取INI文件的步奏详解. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Apa yang perlu dilakukan jika kod ralat 0x80004005 muncul Editor akan mengajar anda cara menyelesaikan kod ralat 0x80004005.
Mar 21, 2024 pm 09:17 PM
Apa yang perlu dilakukan jika kod ralat 0x80004005 muncul Editor akan mengajar anda cara menyelesaikan kod ralat 0x80004005.
Mar 21, 2024 pm 09:17 PM
Apabila memadam atau menyahmampat folder pada komputer anda, kadangkala kotak dialog segera "Ralat 0x80004005: Ralat Tidak Ditentukan" akan muncul Bagaimana anda harus menyelesaikan situasi ini? Sebenarnya terdapat banyak sebab mengapa kod ralat 0x80004005 digesa, tetapi kebanyakannya disebabkan oleh virus. Kami boleh mendaftarkan semula dll untuk menyelesaikan masalah tersebut . Sesetengah pengguna digesa dengan kod ralat 0X80004005 apabila menggunakan komputer mereka Ralat 0x80004005 disebabkan terutamanya oleh komputer tidak mendaftarkan fail perpustakaan pautan dinamik tertentu dengan betul, atau oleh tembok api yang tidak membenarkan sambungan HTTPS antara komputer dan Internet. Jadi bagaimana pula
 Bagaimana untuk memindahkan fail dari Cakera Awan Quark ke Cakera Awan Baidu?
Mar 14, 2024 pm 02:07 PM
Bagaimana untuk memindahkan fail dari Cakera Awan Quark ke Cakera Awan Baidu?
Mar 14, 2024 pm 02:07 PM
Quark Netdisk dan Baidu Netdisk pada masa ini merupakan perisian Netdisk yang paling biasa digunakan untuk menyimpan fail Jika anda ingin menyimpan fail dalam Quark Netdisk ke Baidu Netdisk, bagaimana anda melakukannya? Dalam isu ini, editor telah menyusun langkah tutorial untuk memindahkan fail dari komputer Quark Network Disk ke Baidu Network Disk Mari kita lihat cara mengendalikannya. Bagaimana untuk menyimpan fail dari Cakera Rangkaian Quark ke Cakera Rangkaian Baidu? Untuk memindahkan fail daripada Cakera Rangkaian Quark ke Cakera Rangkaian Baidu, anda perlu memuat turun fail yang diperlukan terlebih dahulu daripada Cakera Rangkaian Quark, kemudian pilih folder sasaran dalam klien Cakera Rangkaian Baidu dan bukanya. Kemudian, seret dan lepaskan fail yang dimuat turun daripada Cakera Awan Quark ke dalam folder yang dibuka oleh klien Cakera Awan Baidu, atau gunakan fungsi muat naik untuk menambah fail pada Cakera Awan Baidu. Pastikan anda menyemak sama ada fail telah berjaya dipindahkan dalam Cakera Awan Baidu selepas muat naik selesai. Itu sahaja
 Apakah fail hiberfil.sys? Bolehkah hiberfil.sys dipadamkan?
Mar 15, 2024 am 09:49 AM
Apakah fail hiberfil.sys? Bolehkah hiberfil.sys dipadamkan?
Mar 15, 2024 am 09:49 AM
Baru-baru ini, ramai netizen bertanya kepada editor, apakah itu fail hiberfil.sys? Bolehkah hiberfil.sys mengambil banyak ruang pemacu C dan dipadamkan? Editor boleh memberitahu anda bahawa fail hiberfil.sys boleh dipadamkan. Mari kita lihat butiran di bawah. hiberfil.sys ialah fail tersembunyi dalam sistem Windows dan juga fail hibernasi sistem. Ia biasanya disimpan dalam direktori akar pemacu C, dan saiznya bersamaan dengan saiz memori yang dipasang sistem. Fail ini digunakan apabila komputer sedang hibernasi dan mengandungi data memori sistem semasa supaya ia boleh dipulihkan dengan cepat kepada keadaan sebelumnya semasa pemulihan. Oleh kerana saiznya adalah sama dengan kapasiti memori, ia mungkin mengambil jumlah ruang cakera keras yang lebih besar. hiber
 Penggunaan garis miring dan garis miring belakang yang berbeza dalam laluan fail
Feb 26, 2024 pm 04:36 PM
Penggunaan garis miring dan garis miring belakang yang berbeza dalam laluan fail
Feb 26, 2024 pm 04:36 PM
Laluan fail ialah rentetan yang digunakan oleh sistem pengendalian untuk mengenal pasti dan mencari fail atau folder. Dalam laluan fail, terdapat dua simbol biasa yang memisahkan laluan, iaitu garis miring ke hadapan (/) dan garis miring ke belakang (). Kedua-dua simbol ini mempunyai kegunaan dan makna yang berbeza dalam sistem pengendalian yang berbeza. Garis miring ke hadapan (/) ialah pemisah laluan yang biasa digunakan dalam sistem Unix dan Linux. Pada sistem ini, laluan fail bermula dari direktori akar (/) dan dipisahkan oleh garis miring ke hadapan antara setiap direktori. Sebagai contoh, laluan /home/user/Docume
 Penjelasan terperinci tentang mendapatkan hak pentadbir dalam Win11
Mar 08, 2024 pm 03:06 PM
Penjelasan terperinci tentang mendapatkan hak pentadbir dalam Win11
Mar 08, 2024 pm 03:06 PM
Sistem pengendalian Windows ialah salah satu sistem pengendalian yang paling popular di dunia, dan versi baharunya Win11 telah menarik perhatian ramai. Dalam sistem Win11, mendapatkan hak pentadbir adalah operasi penting Hak pentadbir membolehkan pengguna melakukan lebih banyak operasi dan tetapan pada sistem. Artikel ini akan memperkenalkan secara terperinci cara mendapatkan kebenaran pentadbir dalam sistem Win11 dan cara mengurus kebenaran dengan berkesan. Dalam sistem Win11, hak pentadbir dibahagikan kepada dua jenis: pentadbir tempatan dan pentadbir domain. Pentadbir tempatan mempunyai hak pentadbiran penuh ke atas komputer tempatan
 Penjelasan terperinci tentang operasi bahagian dalam Oracle SQL
Mar 10, 2024 am 09:51 AM
Penjelasan terperinci tentang operasi bahagian dalam Oracle SQL
Mar 10, 2024 am 09:51 AM
Penjelasan terperinci tentang operasi bahagi dalam OracleSQL Dalam OracleSQL, operasi bahagi ialah operasi matematik yang biasa dan penting, digunakan untuk mengira hasil pembahagian dua nombor. Bahagian sering digunakan dalam pertanyaan pangkalan data, jadi memahami operasi bahagian dan penggunaannya dalam OracleSQL adalah salah satu kemahiran penting untuk pembangun pangkalan data. Artikel ini akan membincangkan pengetahuan berkaitan operasi bahagian dalam OracleSQL secara terperinci dan menyediakan contoh kod khusus untuk rujukan pembaca. 1. Operasi bahagian dalam OracleSQL
 Penjelasan terperinci tentang peranan fail .ibd dalam MySQL dan langkah berjaga-jaga yang berkaitan
Mar 15, 2024 am 08:00 AM
Penjelasan terperinci tentang peranan fail .ibd dalam MySQL dan langkah berjaga-jaga yang berkaitan
Mar 15, 2024 am 08:00 AM
Penjelasan terperinci tentang peranan fail .ibd dalam MySQL dan langkah berjaga-jaga yang berkaitan MySQL ialah sistem pengurusan pangkalan data hubungan yang popular, dan data dalam pangkalan data disimpan dalam fail yang berbeza. Antaranya, fail .ibd ialah fail data dalam enjin storan InnoDB, digunakan untuk menyimpan data dan indeks dalam jadual. Artikel ini akan menyediakan analisis terperinci tentang peranan fail .ibd dalam MySQL dan menyediakan contoh kod yang berkaitan untuk membantu pembaca memahami dengan lebih baik. 1. Peranan fail .ibd: menyimpan data: fail .ibd ialah storan InnoDB
 Penjelasan terperinci tentang peranan dan penggunaan pengendali modulo PHP
Mar 19, 2024 pm 04:33 PM
Penjelasan terperinci tentang peranan dan penggunaan pengendali modulo PHP
Mar 19, 2024 pm 04:33 PM
Operator modulo (%) dalam PHP digunakan untuk mendapatkan baki pembahagian dua nombor. Dalam artikel ini, kami akan membincangkan peranan dan penggunaan pengendali modulo secara terperinci, dan memberikan contoh kod khusus untuk membantu pembaca memahami dengan lebih baik. 1. Peranan pengendali modulo Dalam matematik, apabila kita membahagi integer dengan integer lain, kita mendapat hasil bagi dan baki. Sebagai contoh, apabila kita membahagi 10 dengan 3, hasil bahagi ialah 3 dan selebihnya ialah 1. Operator modulo digunakan untuk mendapatkan baki ini. 2. Penggunaan operator modulo Dalam PHP, gunakan simbol % untuk mewakili modulus
