

本文主要为大家分享一篇如何完整写一个爬虫框架的请求方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧,希望能帮助到大家。
产生爬虫框架:
1、建立一个scrapy爬虫工程
2、在工程中产生一个scrapy爬虫
3、配置spider爬虫
4、运行爬虫,获取网页
具体操作:
1、建立工程
定义一个工程,名称为:python123demo
方法:
在cmd中,d: 进入d盘, cd pycodes 进入文件pycodes
然后输入
scrapy startproject python123demo
在pycodes中会生成一个文件:


_init_.py不需要用户编写


2、在工程中产生一个scrapy爬虫
执行一条命令,给出爬虫名字和爬取的网站
产生爬虫:

生成一个名称为 demo 的spider
仅限生成 demo.py,其内容为:

name = 'demo' 当前爬虫名字为demo
allowed_domains = " 爬取该网站域名以下的链接,该域名由cmd命令台输入
start_urls = [] 爬取的初始页面
parse()用于处理相应,解析内容形成字典,发现新的url爬取请求
3、配置产生的spider爬虫,使之满足我们的需求
将解析的页面保存成文件
修改demo.py文件

4、运行爬虫,获取网页
打开cmd输入命令行进行爬虫

然后我的电脑上出现了一个错误
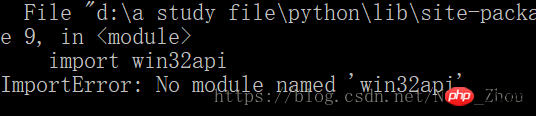
windows系统上出现这个问题的解决需要安装Py32Win模块,但是直接通过官网链接装exe会出现几百个错误,更方便的做法是
pip3 install pypiwin32
这是py3的解决方案
注意:py3版本如果用 pip install pypiwin32指令会发生错误
安装完成后,重新进行爬虫,成功!撒花!
捕获页面存储在 demo.html文件中

demo.py 所对应的完整代码:

两版本等价:

Atas ialah kandungan terperinci 如何完整写一个爬虫框架. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



