

cookie的自动获取以及自动更新的方法
这次给大家带来cookie的自动获取以及自动更新的方法,cookie自动获取以及自动更新的注意事项有哪些,下面就是实战案例,一起来看一下。
社交网站中的很多信息需要登录才能获取到,以微博为例,不登录账号,只能看到大V的前十条微博。保持登录状态,必须要用到Cookie。以登录www.weibo.cn 为例:
分析控制台的Headers的请求返回,会看到weibo.cn有几组返回的cookie。
实现步骤:
1,采用selenium自动登录获取cookie,保存到文件;
2,读取cookie,比较cookie的有效期,若过期则再次执行步骤1;
3,在请求其他网页时,填入cookie,实现登录状态的保持。
1,在线获取cookie
采用selenium + PhantomJS 模拟浏览器登录,获取cookie;
cookies一般会有多个,逐个将cookie存入以.weibo后缀的文件。
def get_cookie_from_network():
from selenium import webdriver
url_login = 'http://login.weibo.cn/login/'
driver = webdriver.PhantomJS()
driver.get(url_login)
driver.find_element_by_xpath('//input[@type="text"]').send_keys('your_weibo_accout') # 改成你的微博账号
driver.find_element_by_xpath('//input[@type="password"]').send_keys('your_weibo_password') # 改成你的微博密码
driver.find_element_by_xpath('//input[@type="submit"]').click() # 点击登录
# 获得 cookie信息
cookie_list = driver.get_cookies()
print cookie_list
cookie_dict = {}
for cookie in cookie_list:
#写入文件
f = open(cookie['name']+'.weibo','w')
pickle.dump(cookie, f)
f.close()
if cookie.has_key('name') and cookie.has_key('value'):
cookie_dict[cookie['name']] = cookie['value']
return cookie_dict2,从文件中获取cookie
从当前目录中遍历以.weibo结尾的文件,即cookie文件。采用pickle解包成dict,比较expiry值与当前时间,若过期则返回为空;
def get_cookie_from_cache():
cookie_dict = {}
for parent, dirnames, filenames in os.walk('./'):
for filename in filenames:
if filename.endswith('.weibo'):
print filename
with open(self.dir_temp + filename, 'r') as f:
d = pickle.load(f)
if d.has_key('name') and d.has_key('value') and d.has_key('expiry'):
expiry_date = int(d['expiry'])
if expiry_date > (int)(time.time()):
cookie_dict[d['name']] = d['value']
else:
return {}
return cookie_dict3,若缓存cookie过期,则再次从网络获取cookie
def get_cookie(): cookie_dict = get_cookie_from_cache() if not cookie_dict: cookie_dict = get_cookie_from_network() return cookie_dict
4,带cookie请求微博其他主页
def get_weibo_list(self, user_id):
import requests
from bs4 import BeautifulSoup as bs
cookdic = get_cookie()
url = 'http://weibo.cn/stocknews88'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.57 Safari/537.36'}
timeout = 5
r = requests.get(url, headers=headers, cookies=cookdic,timeout=timeout)
soup = bs(r.text, 'lxml')
...
# 用BeautifulSoup 解析网页
...相信看了本文案例你已经掌握了方法,更多精彩请关注php中文网其它相关文章!
推荐阅读:
Atas ialah kandungan terperinci cookie的自动获取以及自动更新的方法. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Di manakah kuki disimpan?
Dec 20, 2023 pm 03:07 PM
Di manakah kuki disimpan?
Dec 20, 2023 pm 03:07 PM
Kuki biasanya disimpan dalam folder kuki penyemak imbas antara muka pengurusan kuki yang disediakan oleh penyemak imbas anda untuk melihat dan mengurus kuki.
 Di manakah kuki pada komputer anda?
Dec 22, 2023 pm 03:46 PM
Di manakah kuki pada komputer anda?
Dec 22, 2023 pm 03:46 PM
Kuki pada komputer anda disimpan di lokasi tertentu pada penyemak imbas anda, bergantung pada penyemak imbas dan sistem pengendalian yang digunakan: 1. Google Chrome, disimpan dalam C:\Users\YourUsername\AppData\Local\Google\Chrome\User Data\Default \Cookies dll.
 Di manakah kuki mudah alih?
Dec 22, 2023 pm 03:40 PM
Di manakah kuki mudah alih?
Dec 22, 2023 pm 03:40 PM
Kuki pada telefon mudah alih disimpan dalam aplikasi penyemak imbas peranti mudah alih: 1. Pada peranti iOS, Kuki disimpan dalam Tetapan -> Safari -> Lanjutan -> Data Laman Web pelayar Safari 2. Pada peranti Android, Kuki Disimpan; dalam Tetapan -> Tetapan tapak -> Kuki penyemak imbas Chrome, dsb.
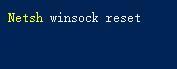 Apakah yang perlu saya lakukan jika win11 tidak boleh menggunakan pelayar ie11? (win11 tidak boleh menggunakan pelayar IE)
Feb 10, 2024 am 10:30 AM
Apakah yang perlu saya lakukan jika win11 tidak boleh menggunakan pelayar ie11? (win11 tidak boleh menggunakan pelayar IE)
Feb 10, 2024 am 10:30 AM
Semakin ramai pengguna mula menaik taraf sistem win11 Memandangkan setiap pengguna mempunyai tabiat penggunaan yang berbeza, ramai pengguna masih menggunakan pelayar ie11 Jadi apa yang perlu saya lakukan jika sistem win11 tidak boleh menggunakan pelayar ie. Adakah windows11 masih menyokong ie11? Mari kita lihat penyelesaiannya. Penyelesaian kepada masalah yang win11 tidak boleh menggunakan pelayar ie11 1. Pertama, klik kanan menu mula dan pilih "Command Prompt (Administrator)" untuk membukanya. 2. Selepas dibuka, terus masukkan "Netshwinsockreset" dan tekan Enter untuk mengesahkan. 3. Selepas pengesahan, masukkan "netshadvfirewallreset&rdqu
 Cara kuki berfungsi
Sep 20, 2023 pm 05:57 PM
Cara kuki berfungsi
Sep 20, 2023 pm 05:57 PM
Prinsip kerja kuki melibatkan pelayan menghantar kuki, pelayar menyimpan kuki, dan pelayar memproses dan menyimpan kuki. Pengenalan terperinci: 1. Pelayan menghantar kuki, dan pelayan menghantar pengepala respons HTTP yang mengandungi kuki ke penyemak imbas. Kuki ini mengandungi beberapa maklumat, seperti pengesahan identiti pengguna, keutamaan, atau kandungan troli beli-belah Selepas pelayar menerima kuki ini, ia akan disimpan pada komputer pengguna 2. Pelayar menyimpan kuki, dsb.
 Penjelasan terperinci tentang tempat kuki penyemak imbas disimpan
Jan 19, 2024 am 09:15 AM
Penjelasan terperinci tentang tempat kuki penyemak imbas disimpan
Jan 19, 2024 am 09:15 AM
Dengan populariti Internet, kami menggunakan pelayar untuk melayari Internet telah menjadi satu cara hidup. Dalam penggunaan harian penyemak imbas, kita sering menghadapi situasi di mana kita perlu memasukkan kata laluan akaun, seperti membeli-belah dalam talian, rangkaian sosial, e-mel, dsb. Maklumat ini perlu direkodkan oleh penyemak imbas supaya ia tidak perlu dimasukkan lagi pada kali berikutnya anda melawat. Ini adalah apabila kuki berguna. Apakah cookies? Kuki merujuk kepada fail data kecil yang dihantar oleh pelayan ke penyemak imbas pengguna dan disimpan secara setempat Ia mengandungi gelagat pengguna beberapa tapak web.
 Adakah pembersihan kuki mempunyai sebarang kesan?
Sep 20, 2023 pm 06:01 PM
Adakah pembersihan kuki mempunyai sebarang kesan?
Sep 20, 2023 pm 06:01 PM
Kesan mengosongkan kuki termasuk menetapkan semula tetapan dan pilihan pemperibadian, menjejaskan pengalaman iklan dan memusnahkan status log masuk dan fungsi mengingati kata laluan. Pengenalan terperinci: 1. Tetapkan semula tetapan dan pilihan yang diperibadikan Jika kuki dikosongkan, troli beli-belah akan ditetapkan semula kepada kosong dan produk perlu ditambah sekali lagi akan menyebabkan status log masuk pada platform media sosial hilang, memerlukan menambah semula. Masukkan nama pengguna dan kata laluan 2. Ia menjejaskan pengalaman pengiklanan Jika kuki dikosongkan, tapak web tidak akan dapat memahami minat dan pilihan kami, dan akan memaparkan iklan yang tidak berkaitan, dsb.
 Apakah bahaya kebocoran kuki?
Sep 20, 2023 pm 05:53 PM
Apakah bahaya kebocoran kuki?
Sep 20, 2023 pm 05:53 PM
Bahaya kebocoran kuki termasuk kecurian maklumat identiti peribadi, penjejakan tingkah laku dalam talian peribadi dan kecurian akaun. Pengenalan terperinci: 1. Maklumat identiti peribadi telah dicuri, seperti nama, alamat e-mel, nombor telefon, dsb. Maklumat ini boleh digunakan oleh penjenayah untuk menjalankan aktiviti haram seperti kecurian identiti dan penipuan 2. Tingkah laku dalam talian peribadi dikesan dan dianalisis melalui kuki Dengan data dalam akaun, penjenayah boleh mengetahui tentang sejarah penyemakan imbas pengguna, pilihan membeli-belah, hobi, dsb.;
