
这次给大家带来PHP实现Huffman编码/解码步骤详解,PHP实现Huffman编码/解码的注意事项有哪些,下面就是实战案例,一起来看一下。
本文就来用 PHP 来实践一下 Huffman 编码和解码。
1. 编码
字数统计
Huffman编码的第一步就是要统计文档中每个字符出现的次数,PHP的内置函数 count_chars() 就可以做到:
$input = file_get_contents('input.txt'); $stat = count_chars($input, 1);
构造Huffman树
接下来根据统计结果构造Huffman树,构造方法在 Wikipedia 有详细的描述。这里用PHP写了一个简易版的:
$huffmanTree = [];
foreach ($stat as $char => $count) {
$huffmanTree[] = [
'k' => chr($char),
'v' => $count,
'left' => null,
'right' => null,
];
}
// 构造树的层级关系,思想见wiki:https://zh.wikipedia.org/wiki/%E9%9C%8D%E5%A4%AB%E6%9B%BC%E7%BC%96%E7%A0%81
$size = count($huffmanTree);
for ($i = 0; $i !== $size - 1; $i++) {
uasort($huffmanTree, function ($a, $b) {
if ($a['v'] === $b['v']) {
return 0;
}
return $a['v'] < $b['v'] ? -1 : 1;
});
$a = array_shift($huffmanTree);
$b = array_shift($huffmanTree);
$huffmanTree[] = [
'v' => $a['v'] + $b['v'],
'left' => $b,
'right' => $a,
];
}
$root = current($huffmanTree);经过计算之后,$root 就会指向 Huffman 树的根节点
根据Huffman树生成编码字典
有了 Huffman 树,就可以生成用于编码的字典:
function buildDict($elem, $code = '', &$dict) {
if (isset($elem['k'])) {
$dict[$elem['k']] = $code;
} else {
buildDict($elem['left'], $code.'0', $dict);
buildDict($elem['right'], $code.'1', $dict);
}
}
$dict = [];
buildDict($root, '', $dict);写文件
运用字典将文件内容进行编码,并写入文件。将Huffman编码写入文件的有几个注意的地方:
将编码字典和编码内容一起写入文件后,就没法区分他们的边界了,因此需要在文件开始写入他们各自占用的字节数
PHP提供的 fwrite() 函数一次能写入 8-bit(一个字节)或者是 8的整数倍个bit。但Huffman编码中,一个字符可能只使用 1-bit 表示,PHP不支持只往文件中写入 1-bit 这种操作。所以需要我们自行对编码进行拼接,每凑齐 8-bit 才写入文件。
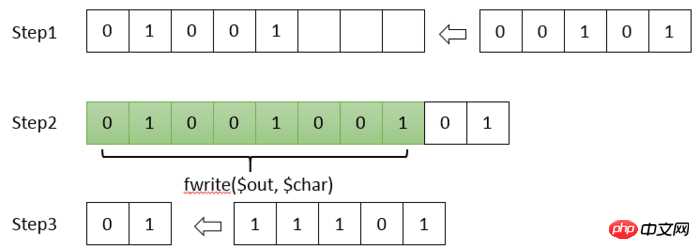
每凑齐8-bit才写入
与第二条类似,最终形成的文件大小一定是 8-bit 的整数倍。所以如果整个编码的大小是 8001-bit的话,还要在末尾补上 7个 0
$dictString = serialize($dict);
// 写入字典和编码各自占用的字节数
$header = pack('VV', strlen($dictString), strlen($input));
fwrite($outFile, $header);
// 写入字典本身
fwrite($outFile, $dictString);
// 写入编码的内容
$buffer = '';
$i = 0;
while (isset($input[$i])) {
$buffer .= $dict[$input[$i]];
while (isset($buffer[7])) {
$char = bindec(substr($buffer, 0, 8));
fwrite($outFile, chr($char));
$buffer = substr($buffer, 8);
}
$i++;
}
// 末尾的内容如果没有凑齐 8-bit,需要自行补齐
if (!empty($buffer)) {
$char = bindec(str_pad($buffer, 8, '0'));
fwrite($outFile, chr($char));
}
fclose($outFile);解码
Huffman编码的解码相对简单:先读取编码字典,然后根据字典解码出原始字符。
解码过程有个问题需要注意:由于我们在编码过程中,在文件末尾补齐了几个0-bit,如果这些 0-bit 在字典中恰巧是某个字符的编码时,就会造成错误的解码。
所以解码过程中,当已解码的字符数达到文档长度时,就要停止解码。
<?php
$content = file_get_contents('a.out');
// 读出字典长度和编码内容长度
$header = unpack('VdictLen/VcontentLen', $content);
$dict = unserialize(substr($content, 8, $header['dictLen']));
$dict = array_flip($dict);
$bin = substr($content, 8 + $header['dictLen']);
$output = '';
$key = '';
$decodedLen = 0;
$i = 0;
while (isset($bin[$i]) && $decodedLen !== $header['contentLen']) {
$bits = decbin(ord($bin[$i]));
$bits = str_pad($bits, 8, '0', STR_PAD_LEFT);
for ($j = 0; $j !== 8; $j++) {
// 每拼接上 1-bit,就去与字典比对是否能解码出字符
$key .= $bits[$j];
if (isset($dict[$key])) {
$output .= $dict[$key];
$key = '';
$decodedLen++;
if ($decodedLen === $header['contentLen']) {
break;
}
}
}
$i++;
}
echo $output;试验
我们将Huffman编码Wiki页 的HTML代码保存到本地,进行Huffman编码测试,试验结果:
编码前: 418,504 字节
编码后: 280,127 字节
空间节省了 33%,如果原文的重复内容较多,Huffman编码节省的空间可以达到 50% 以上.
除了文本内容,我们再尝试将一个二进制文件进行Huffman编码,比如 f.lux的安装程序 ,试验结果如下:
编码前: 770,384 字节
编码后: 773,076 字节
编码后反而占用了更大的空间,一方面是由于我们存储字典时,并没有做额外的处理,占用了不少空间。另一方面,二进制文件中,各个字符出现的概率相对比较平均,无法发挥Huffman编码的优势。
相信看了本文案例你已经掌握了方法,更多精彩请关注php中文网其它相关文章!
推荐阅读:
Atas ialah kandungan terperinci PHP实现Huffman编码/解码步骤详解. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk membuka fail php
Bagaimana untuk membuka fail php
 Bagaimana untuk mengalih keluar beberapa elemen pertama tatasusunan dalam php
Bagaimana untuk mengalih keluar beberapa elemen pertama tatasusunan dalam php
 Apa yang perlu dilakukan jika penyahserialisasian php gagal
Apa yang perlu dilakukan jika penyahserialisasian php gagal
 Bagaimana untuk menyambungkan php ke pangkalan data mssql
Bagaimana untuk menyambungkan php ke pangkalan data mssql
 Bagaimana untuk menyambung php ke pangkalan data mssql
Bagaimana untuk menyambung php ke pangkalan data mssql
 Bagaimana untuk memuat naik html
Bagaimana untuk memuat naik html
 Bagaimana untuk menyelesaikan aksara bercelaru dalam PHP
Bagaimana untuk menyelesaikan aksara bercelaru dalam PHP
 Bagaimana untuk membuka fail php pada telefon bimbit
Bagaimana untuk membuka fail php pada telefon bimbit








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



