
给大家讲解了微信公众号文章采集的入口历史消息页信息获取方法,有需要的朋友参考一下本内容。
采集微信文章和采集网站内容一样,都需要从一个列表页开始。而微信文章的列表页就是公众号里的查看历史消息页。现在网络上的其它微信采集器有的是利用搜狗搜索,采集方式虽然简单多了,但是内容不全。所以我们还是要从最标准最全面的公众号历史消息页来采集。
因为微信的限制,我们能复制到的链接是不完整的,在浏览器中无法打开看到内容。所以我们需要通过上一篇文章介绍的方法,使用anyproxy获取到一个完整的微信公众号历史消息页面的链接地址。
http://mp.weixin.qq.com/mp/getmasssendmsg?__biz=MjM5NDAwMTA2MA==&uin=NzM4MTk1ODgx&key=bf9387c4d02682e186a298a18276d8e0555e3ab51d81ca46de339e6082eb767343bef610edd80c9e1bfda66c2b62751511f7cc091a33a029709e94f0d1604e11220fc099a27b2e2d29db75cc0849d4bf&devicetype=android-17&version=26031c34&lang=zh_CN&nettype=WIFI&ascene=3&pass_ticket=Iox5ZdpRhrSxGYEeopVJwTBP7kZj51GYyEL24AT5Zyx%2BBoEMdPDBtOun1F%2F9ENSz&wx_header=1
前一篇文章提到过,biz参数是公众号的ID,uin是用户的ID,目前来看uin是在所有公众号之间唯一的。其它两个重要参数key和pass_ticket是微信客户端补充上的参数。
所以在这个地址失效之前我们是可以通过浏览器查看原文的方法获取到历史消息的文章列表的,如果希望自动化分析内容,也可以制作一个程序,将这个带有尚未失效的key和pass_ticket的链接地址提交进去,再通过例如php程序来获取到文章列表。
最近有朋友跟我说他的采集目标就是单一的一个公众号,我觉得这样就没必要用上一篇文章写的批量采集的方法了。所以我们接下来看看历史消息页里面是怎样获取到文章列表的,通过分析文章列表,就可以得到这个公众号所有的内容链接地址,然后再采集内容就可以了。
在anyproxy的web界面中如果证书配置正确,是可以显示出https的内容的。web界面的地址是http://localhost:8002 其中localhost可以替换成自己的IP地址或域名。从列表中找到getmasssendmsg开头的记录,点击之后右侧就会显示出这条记录的详情:
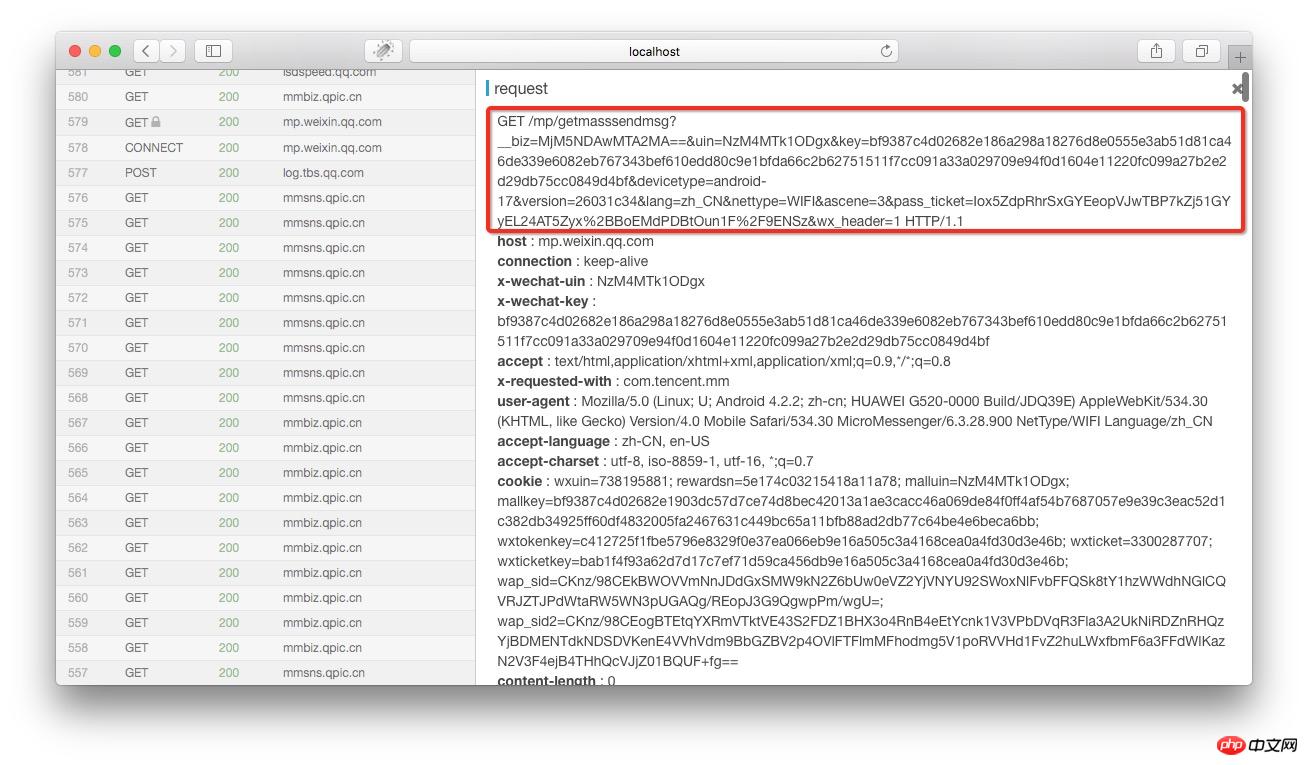
红框部分就是完整的链接地址,将微信公众平台这个域名拼接在前面之后就可以在浏览器中打开了。
然后将页面向下拉,到html内容的结尾部分,我们可以看到一个json的变量就是历史消息的文章列表:
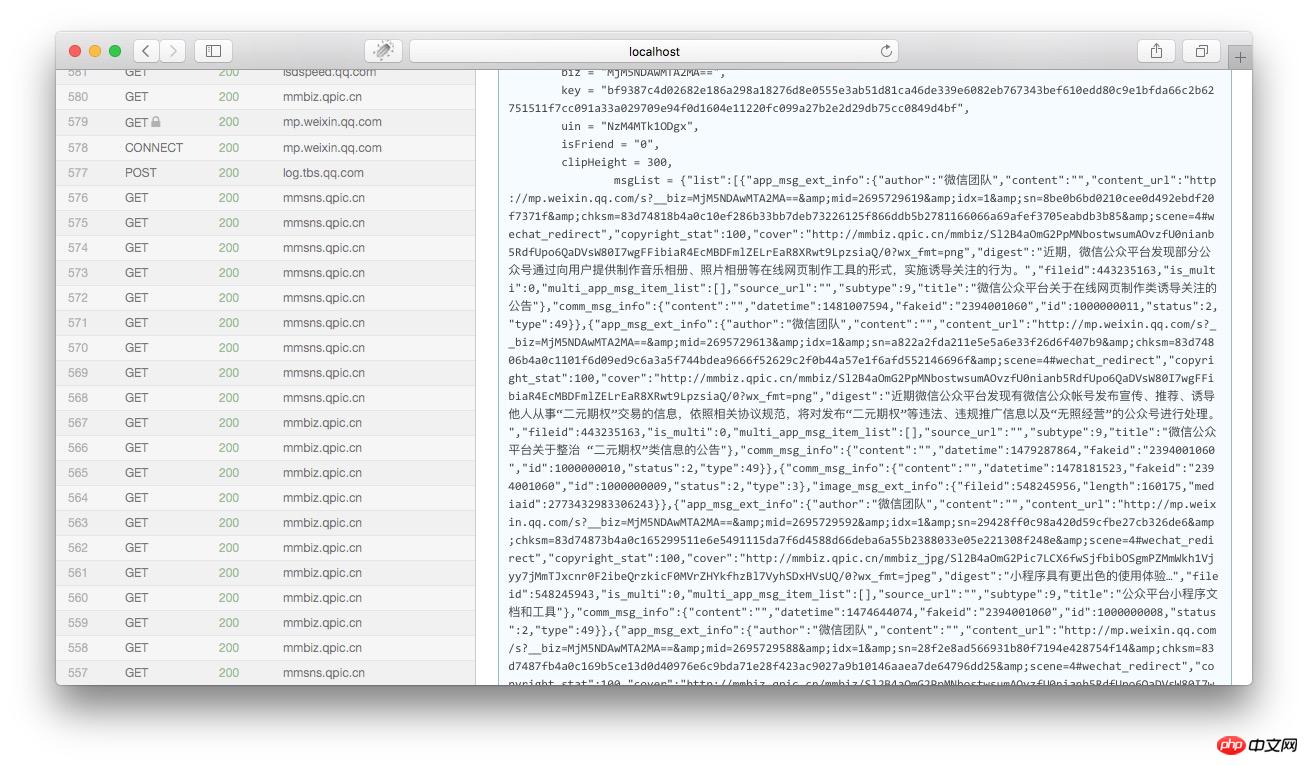
我们将msgList的变量值拷贝出来,用json格式化工具分析一下,我们就可以看到这个json是以下这个结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s?__biz=MzA5MzEzNDg3MQ==&mid=2652767427&idx=1&sn=37da0d7208283bf90e9a4a536e0af0ea&chksm=8b882dbbbcffa4ad2f0b8a141cc988d16bace564274018e68e5c53ee6f354f8ad56c9b98bade&scene=4#wechat_redirect",
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/MofBAcBsJ6X0xGrQ2XK5yQjzwb2eswxkRNBTgLtcqGziaFqwibzvtZAHCDkMeJU1fGZHpjoeibanPJ8rziaq68Akkg/0?wx_fmt=jpeg",
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s?__biz=MzA5MzEzNDg3MQ==&mid=2652767427&idx=2&sn=449ef1a874a37fed2429e14f724b56ef&chksm=8b882dbbbcffa4ade48a7932cda4263687e34fca8ea3a5a6233d2589d448b9f6130d3890ce93&scene=4#wechat_redirect",
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png/MofBAcBsJ6XyaIn0qEDSSicBUBZbMYHYrhibia89ZnksCsUiaia2TLI1fyqjclibGa1hw3icP6oXeSpaWMjiabaghHl7yw/0?wx_fmt=png",
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/detail/ff764b0731b7465db03b56b998e1f2b8?detailReferrer=1&from=groupmessage&isappinstalled=0",
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}简要的分析一下这个json(这里只介绍一些重要的信息,其它的被省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]在这里还要提到一点就是如果希望获取到时间更久远一些的历史消息内容,就需要在手机或模拟器中将页面向下拉,当拉到最底下的时候,微信将自动读取下一页的内容。下一页的链接地址和历史消息页的链接地址同样是getmasssendmsg开头的地址。但是内容就是只有json了,没有html了。直接解析json就可以了。
这时可以通过上一篇文章介绍的方法,使用anyproxy将msgList变量值正则匹配出来之后,异步提交到服务器,再从服务器上使用php的json_decode解析json成为数组。然后遍历循环数组。我们就可以得到每一篇文章的标题和链接地址。
如果只需要采集单一公众号的内容,完全可以在每天群发之后,通过anyproxy获取到完整的带有key和pass_ticket的链接地址。然后自己制作一个程序,手动将地址提交给自己的程序。使用例如php这样的语言来正则匹配到msgList,然后解析json。这样就不用修改anyproxy的rule,也不需要制作一个采集队列和跳转页面了。
相关推荐:
PHP+cURL获取微信公众号access_token步骤解析
Atas ialah kandungan terperinci 微信公众号历史消息获取方法. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah yang dimaksudkan apabila mesej telah dihantar tetapi ditolak oleh pihak lain?
Apakah yang dimaksudkan apabila mesej telah dihantar tetapi ditolak oleh pihak lain?
 Bagaimana untuk menyambung jalur lebar ke pelayan
Bagaimana untuk menyambung jalur lebar ke pelayan
 Bagaimana untuk mengkonfigurasi ruang maya jsp
Bagaimana untuk mengkonfigurasi ruang maya jsp
 Apakah jenis fail yang boleh dikenal pasti berdasarkan
Apakah jenis fail yang boleh dikenal pasti berdasarkan
 Bagaimana untuk menangani lag komputer yang perlahan dan tindak balas yang perlahan
Bagaimana untuk menangani lag komputer yang perlahan dan tindak balas yang perlahan
 nama penuh aplikasi
nama penuh aplikasi
 nampak bermakna
nampak bermakna
 Penyelesaian kepada pengecualian pengecualian perisian yang tidak diketahui dalam aplikasi komputer
Penyelesaian kepada pengecualian pengecualian perisian yang tidak diketahui dalam aplikasi komputer
 Penggunaan typedef dalam bahasa c
Penggunaan typedef dalam bahasa c








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



