
这篇文章主要介绍了网页爬虫之cookie自动获取及过期自动更新的实现方法,需要的朋友可以参考下
本文实现cookie的自动获取,及cookie过期自动更新。
社交网站中的很多信息需要登录才能获取到,以微博为例,不登录账号,只能看到大V的前十条微博。保持登录状态,必须要用到Cookie。以登录www.weibo.cn 为例:
在chrome中输入:http://login.weibo.cn/login/
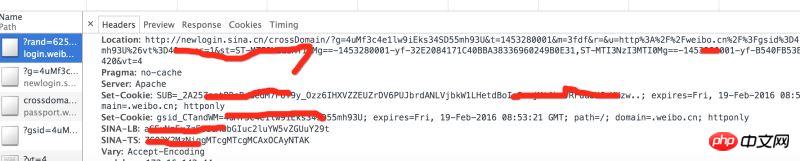
分析控制台的Headers的请求返回,会看到weibo.cn有几组返回的cookie。
实现步骤:
1,采用selenium自动登录获取cookie,保存到文件;
2,读取cookie,比较cookie的有效期,若过期则再次执行步骤1;
3,在请求其他网页时,填入cookie,实现登录状态的保持。
1,在线获取cookie
采用selenium + PhantomJS 模拟浏览器登录,获取cookie;
cookies一般会有多个,逐个将cookie存入以.weibo后缀的文件。
def get_cookie_from_network():
from selenium import webdriver
url_login = 'http://login.weibo.cn/login/'
driver = webdriver.PhantomJS()
driver.get(url_login)
driver.find_element_by_xpath('//input[@type="text"]').send_keys('your_weibo_accout') # 改成你的微博账号
driver.find_element_by_xpath('//input[@type="password"]').send_keys('your_weibo_password') # 改成你的微博密码
driver.find_element_by_xpath('//input[@type="submit"]').click() # 点击登录
# 获得 cookie信息
cookie_list = driver.get_cookies()
print cookie_list
cookie_dict = {}
for cookie in cookie_list:
#写入文件
f = open(cookie['name']+'.weibo','w')
pickle.dump(cookie, f)
f.close()
if cookie.has_key('name') and cookie.has_key('value'):
cookie_dict[cookie['name']] = cookie['value']
return cookie_dict2,从文件中获取cookie
从当前目录中遍历以.weibo结尾的文件,即cookie文件。采用pickle解包成dict,比较expiry值与当前时间,若过期则返回为空;
def get_cookie_from_cache():
cookie_dict = {}
for parent, dirnames, filenames in os.walk('./'):
for filename in filenames:
if filename.endswith('.weibo'):
print filename
with open(self.dir_temp + filename, 'r') as f:
d = pickle.load(f)
if d.has_key('name') and d.has_key('value') and d.has_key('expiry'):
expiry_date = int(d['expiry'])
if expiry_date > (int)(time.time()):
cookie_dict[d['name']] = d['value']
else:
return {}
return cookie_dict3,若缓存cookie过期,则再次从网络获取cookie
def get_cookie(): cookie_dict = get_cookie_from_cache() if not cookie_dict: cookie_dict = get_cookie_from_network() return cookie_dict
4,带cookie请求微博其他主页
def get_weibo_list(self, user_id):
import requests
from bs4 import BeautifulSoup as bs
cookdic = get_cookie()
url = 'http://weibo.cn/stocknews88'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.57 Safari/537.36'}
timeout = 5
r = requests.get(url, headers=headers, cookies=cookdic,timeout=timeout)
soup = bs(r.text, 'lxml')
...
# 用BeautifulSoup 解析网页
...上面是我整理给大家的,希望今后会对大家有帮助。
相关文章:
vue2.0 computed 计算list循环后累加值的实例
Atas ialah kandungan terperinci 通过网页爬虫中cookie自动获取及过期自动更新(详细教程). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 biskut
biskut
 Bagaimana untuk menyelesaikan masalah yang document.cookie tidak boleh diperolehi
Bagaimana untuk menyelesaikan masalah yang document.cookie tidak boleh diperolehi
 iaitu jalan pintas tidak boleh dipadam
iaitu jalan pintas tidak boleh dipadam
 Apakah maksud menyekat semua kuki?
Apakah maksud menyekat semua kuki?
 Bagaimana untuk menyelesaikan masalah bahawa pintasan IE tidak boleh dipadamkan
Bagaimana untuk menyelesaikan masalah bahawa pintasan IE tidak boleh dipadamkan
 Kelas utama tidak ditemui atau tidak dapat dimuatkan
Kelas utama tidak ditemui atau tidak dapat dimuatkan
 Apakah perbezaan antara ibatis dan mybatis
Apakah perbezaan antara ibatis dan mybatis
 Apakah alat ujian java?
Apakah alat ujian java?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



