

pytorch + visdom 处理简单分类问题

这篇文章主要介绍了关于pytorch + visdom 处理简单分类问题,有着一定的参考价值,现在分享给大家,有需要的朋友可以参考一下
环境
系统 : win 10
显卡:gtx965m
cpu :i7-6700HQ
python 3.61
pytorch 0.3
包引用
import torch from torch.autograd import Variable import torch.nn.functional as F import numpy as np import visdom import time from torch import nn,optim
数据准备
use_gpu = True ones = np.ones((500,2)) x1 = torch.normal(6*torch.from_numpy(ones),2) y1 = torch.zeros(500) x2 = torch.normal(6*torch.from_numpy(ones*[-1,1]),2) y2 = y1 +1 x3 = torch.normal(-6*torch.from_numpy(ones),2) y3 = y1 +2 x4 = torch.normal(6*torch.from_numpy(ones*[1,-1]),2) y4 = y1 +3 x = torch.cat((x1, x2, x3 ,x4), 0).float() y = torch.cat((y1, y2, y3, y4), ).long()
可视化如下看一下:
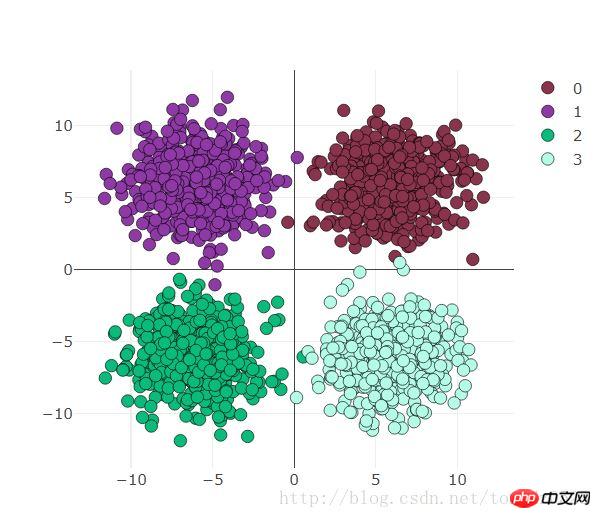
visdom可视化准备
先建立需要观察的windows
viz = visdom.Visdom()
colors = np.random.randint(0,255,(4,3)) #颜色随机
#线图用来观察loss 和 accuracy
line = viz.line(X=np.arange(1,10,1), Y=np.arange(1,10,1))
#散点图用来观察分类变化
scatter = viz.scatter(
X=x,
Y=y+1,
opts=dict(
markercolor = colors,
marksize = 5,
legend=["0","1","2","3"]),)
#text 窗口用来显示loss 、accuracy 、时间
text = viz.text("FOR TEST")
#散点图做对比
viz.scatter(
X=x,
Y=y+1,
opts=dict(
markercolor = colors,
marksize = 5,
legend=["0","1","2","3"]
),
)效果如下:
逻辑回归处理
输入2,输出4
logstic = nn.Sequential( nn.Linear(2,4) )
gpu还是cpu选择:
if use_gpu:
gpu_status = torch.cuda.is_available()
if gpu_status:
logstic = logstic.cuda()
# net = net.cuda()
print("###############使用gpu##############")
else : print("###############使用cpu##############")
else:
gpu_status = False
print("###############使用cpu##############")优化器和loss函数:
loss_f = nn.CrossEntropyLoss() optimizer_l = optim.SGD(logstic.parameters(), lr=0.001)
训练2000次:
start_time = time.time()
time_point, loss_point, accuracy_point = [], [], []
for t in range(2000):
if gpu_status:
train_x = Variable(x).cuda()
train_y = Variable(y).cuda()
else:
train_x = Variable(x)
train_y = Variable(y)
# out = net(train_x)
out_l = logstic(train_x)
loss = loss_f(out_l,train_y)
optimizer_l.zero_grad()
loss.backward()
optimizer_l.step()训练过成观察及可视化:
if t % 10 == 0:
prediction = torch.max(F.softmax(out_l, 1), 1)[1]
pred_y = prediction.data
accuracy = sum(pred_y ==train_y.data)/float(2000.0)
loss_point.append(loss.data[0])
accuracy_point.append(accuracy)
time_point.append(time.time()-start_time)
print("[{}/{}] | accuracy : {:.3f} | loss : {:.3f} | time : {:.2f} ".format(t + 1, 2000, accuracy, loss.data[0],
time.time() - start_time))
viz.line(X=np.column_stack((np.array(time_point),np.array(time_point))),
Y=np.column_stack((np.array(loss_point),np.array(accuracy_point))),
win=line,
opts=dict(legend=["loss", "accuracy"]))
#这里的数据如果用gpu跑会出错,要把数据换成cpu的数据 .cpu()即可
viz.scatter(X=train_x.cpu().data, Y=pred_y.cpu()+1, win=scatter,name="add",
opts=dict(markercolor=colors,legend=["0", "1", "2", "3"]))
viz.text("<h3 align='center' style='color:blue'>accuracy : {}</h3><br><h3 align='center' style='color:pink'>"
"loss : {:.4f}</h3><br><h3 align ='center' style='color:green'>time : {:.1f}</h3>"
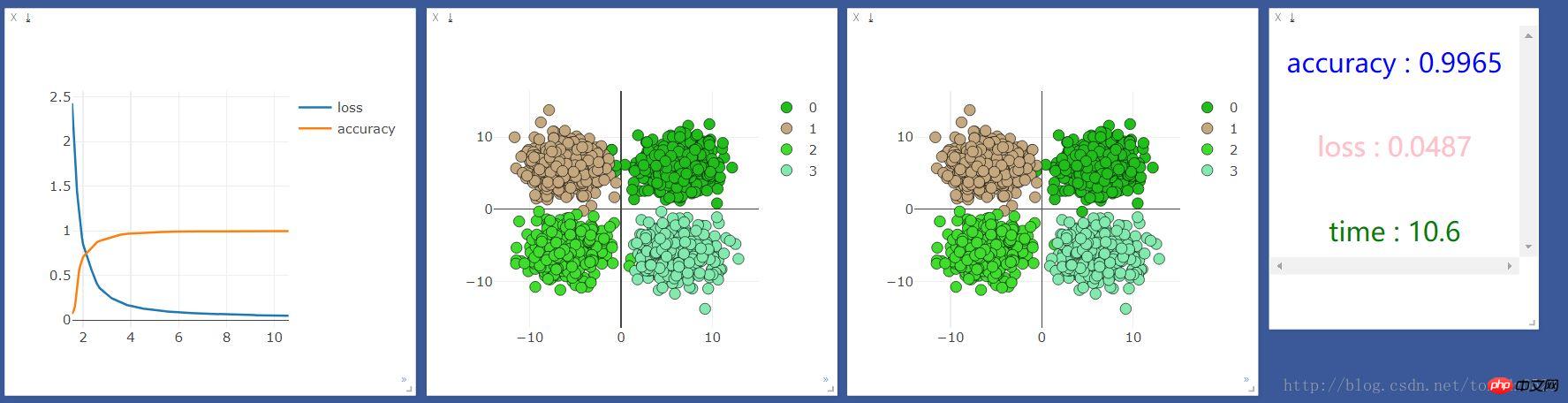
.format(accuracy,loss.data[0],time.time()-start_time),win =text)我们先用cpu运行一次,结果如下:
然后用gpu运行一下,结果如下:
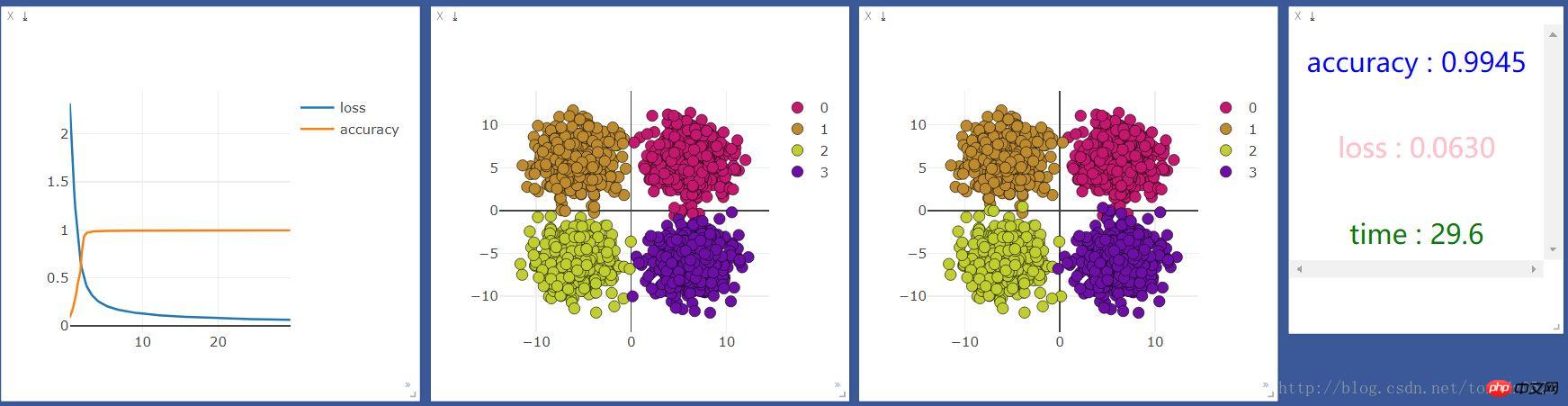
发现cpu的速度比gpu快很多,但是我听说机器学习应该是gpu更快啊,百度了一下,知乎上的答案是:

我的理解就是gpu在处理图片识别大量矩阵运算等方面运算能力远高于cpu,在处理一些输入和输出都很少的,还是cpu更具优势。
添加神经层:
net = nn.Sequential( nn.Linear(2, 10), nn.ReLU(), #激活函数 nn.Linear(10, 4) )
添加一层10单元神经层,看看效果是否会有所提升:
使用cpu:
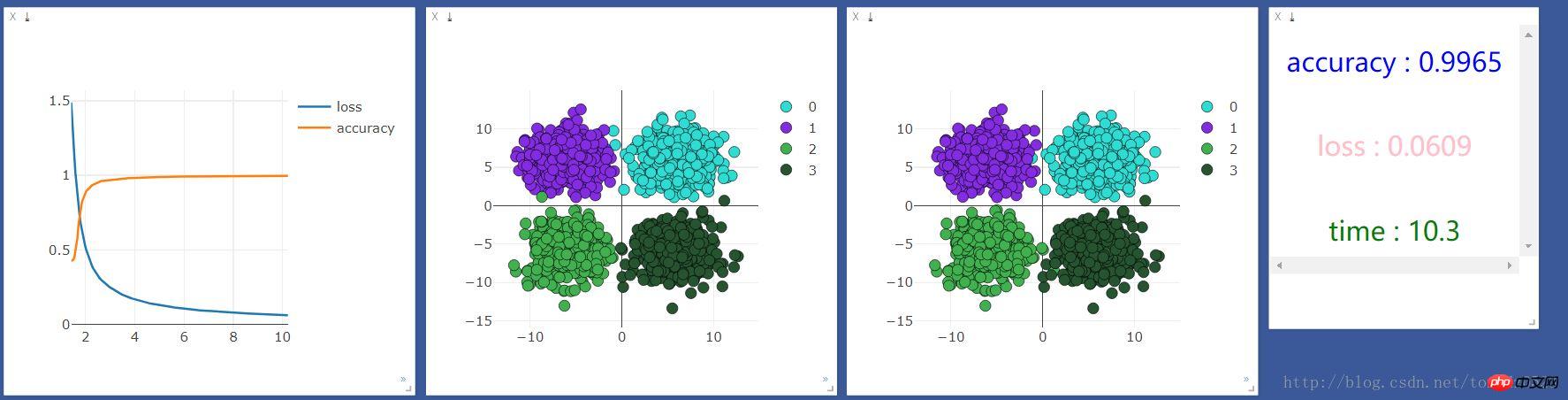
使用gpu:
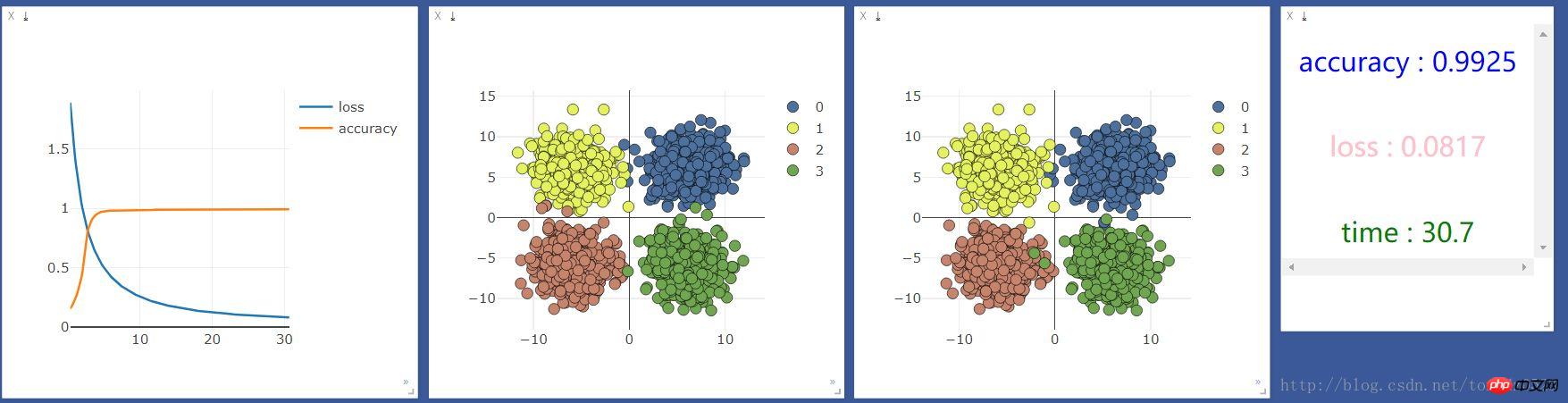
比较观察,似乎并没有什么区别,看来处理简单分类问题(输入,输出少)的问题,神经层和gpu不会对机器学习加持。
相关推荐:
Atas ialah kandungan terperinci pytorch + visdom 处理简单分类问题. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 iFlytek: Huawei Ascend 910B pada asasnya setanding dengan NVIDIA A100 dalam keupayaan, dan mereka bekerjasama untuk mencipta pangkalan baharu untuk kecerdasan buatan umum negara saya
Oct 22, 2023 pm 06:13 PM
iFlytek: Huawei Ascend 910B pada asasnya setanding dengan NVIDIA A100 dalam keupayaan, dan mereka bekerjasama untuk mencipta pangkalan baharu untuk kecerdasan buatan umum negara saya
Oct 22, 2023 pm 06:13 PM
Laman web ini melaporkan pada 22 Oktober bahawa pada suku ketiga tahun ini, iFlytek mencapai keuntungan bersih sebanyak 25.79 juta yuan, penurunan tahun ke tahun sebanyak 81.86% dalam tiga suku pertama ialah 99.36 juta yuan, a penurunan tahun ke tahun sebanyak 76.36%. Jiang Tao, naib presiden iFlytek, mendedahkan pada taklimat prestasi Q3 bahawa iFlytek telah melancarkan projek penyelidikan khas dengan Huawei Shengteng pada awal 2023, dan bersama-sama membangunkan perpustakaan pengendali berprestasi tinggi dengan Huawei untuk bersama-sama mewujudkan pangkalan baharu bagi buatan am China. kecerdasan untuk membenarkan model skala besar domestik Seni bina adalah berdasarkan perisian dan perkakasan inovatif secara bebas. Beliau menegaskan bahawa keupayaan semasa Huawei Ascend 910B pada asasnya setanding dengan Nvidia A100. Pada Festival Pembangun Global iFlytek 1024 yang akan datang, iFlytek dan Huawei akan membuat pengumuman bersama selanjutnya mengenai pangkalan kuasa pengkomputeran kecerdasan buatan. Beliau juga menyebut,
 Gabungan sempurna PyCharm dan PyTorch: langkah pemasangan dan konfigurasi terperinci
Feb 21, 2024 pm 12:00 PM
Gabungan sempurna PyCharm dan PyTorch: langkah pemasangan dan konfigurasi terperinci
Feb 21, 2024 pm 12:00 PM
PyCharm ialah persekitaran pembangunan bersepadu (IDE) yang berkuasa dan PyTorch ialah rangka kerja sumber terbuka yang popular dalam bidang pembelajaran mendalam. Dalam bidang pembelajaran mesin dan pembelajaran mendalam, menggunakan PyCharm dan PyTorch untuk pembangunan boleh meningkatkan kecekapan pembangunan dan kualiti kod. Artikel ini akan memperkenalkan secara terperinci cara memasang dan mengkonfigurasi PyTorch dalam PyCharm, dan melampirkan contoh kod khusus untuk membantu pembaca menggunakan fungsi berkuasa kedua-dua ini dengan lebih baik. Langkah 1: Pasang PyCharm dan Python
 Pengenalan kepada lima kaedah pensampelan dalam tugas penjanaan bahasa semula jadi dan pelaksanaan kod Pytorch
Feb 20, 2024 am 08:50 AM
Pengenalan kepada lima kaedah pensampelan dalam tugas penjanaan bahasa semula jadi dan pelaksanaan kod Pytorch
Feb 20, 2024 am 08:50 AM
Dalam tugas penjanaan bahasa semula jadi, kaedah pensampelan ialah teknik untuk mendapatkan output teks daripada model generatif. Artikel ini akan membincangkan 5 kaedah biasa dan melaksanakannya menggunakan PyTorch. 1. GreedyDecoding Dalam penyahkodan tamak, model generatif meramalkan perkataan urutan keluaran berdasarkan urutan input masa langkah demi masa. Pada setiap langkah masa, model mengira taburan kebarangkalian bersyarat bagi setiap perkataan, dan kemudian memilih perkataan dengan kebarangkalian bersyarat tertinggi sebagai output langkah masa semasa. Perkataan ini menjadi input kepada langkah masa seterusnya, dan proses penjanaan diteruskan sehingga beberapa syarat penamatan dipenuhi, seperti urutan panjang tertentu atau penanda akhir khas. Ciri GreedyDecoding ialah setiap kali kebarangkalian bersyarat semasa adalah yang terbaik
 Melaksanakan model resapan penyingkiran hingar menggunakan PyTorch
Jan 14, 2024 pm 10:33 PM
Melaksanakan model resapan penyingkiran hingar menggunakan PyTorch
Jan 14, 2024 pm 10:33 PM
Sebelum kita memahami prinsip kerja Model Kebarangkalian Penyebaran Denoising (DDPM) secara terperinci, mari kita fahami dahulu beberapa perkembangan kecerdasan buatan generatif, yang juga merupakan salah satu penyelidikan asas DDPM. VAEVAE menggunakan pengekod, ruang terpendam kemungkinan dan penyahkod. Semasa latihan, pengekod meramalkan min dan varians setiap imej dan sampel nilai ini daripada taburan Gaussian. Hasil pensampelan dihantar ke penyahkod, yang menukar imej input ke dalam bentuk yang serupa dengan imej output. KL divergence digunakan untuk mengira kerugian. Kelebihan ketara VAE ialah keupayaannya untuk menghasilkan imej yang pelbagai. Dalam peringkat persampelan, seseorang boleh membuat sampel terus daripada taburan Gaussian dan menjana imej baharu melalui penyahkod. GAN telah mencapai kemajuan besar dalam pengekod auto variasi (VAE) dalam masa satu tahun sahaja.
 Tutorial memasang PyCharm dengan PyTorch
Feb 24, 2024 am 10:09 AM
Tutorial memasang PyCharm dengan PyTorch
Feb 24, 2024 am 10:09 AM
Sebagai rangka kerja pembelajaran mendalam yang berkuasa, PyTorch digunakan secara meluas dalam pelbagai projek pembelajaran mesin. Sebagai persekitaran pembangunan bersepadu Python yang berkuasa, PyCharm juga boleh memberikan sokongan yang baik apabila melaksanakan tugas pembelajaran mendalam. Artikel ini akan memperkenalkan secara terperinci cara memasang PyTorch dalam PyCharm dan menyediakan contoh kod khusus untuk membantu pembaca mula menggunakan PyTorch dengan cepat untuk tugasan pembelajaran mendalam. Langkah 1: Pasang PyCharm Mula-mula, kita perlu pastikan kita ada
 Pembelajaran Mendalam dengan PHP dan PyTorch
Jun 19, 2023 pm 02:43 PM
Pembelajaran Mendalam dengan PHP dan PyTorch
Jun 19, 2023 pm 02:43 PM
Pembelajaran mendalam merupakan satu cabang penting dalam bidang kecerdasan buatan dan semakin mendapat perhatian dan perhatian sejak beberapa tahun kebelakangan ini. Untuk dapat menjalankan penyelidikan dan aplikasi pembelajaran mendalam, selalunya perlu menggunakan beberapa rangka kerja pembelajaran mendalam untuk membantu melaksanakannya. Dalam artikel ini, kami akan memperkenalkan cara menggunakan PHP dan PyTorch untuk pembelajaran mendalam. 1. Apakah PyTorch? PyTorch ialah rangka kerja pembelajaran mesin sumber terbuka yang dibangunkan oleh Facebook Ia boleh membantu kami mencipta dan melatih model pembelajaran mendalam. PyTorc
 sangat laju! Kenali pertuturan video menjadi teks dalam beberapa minit sahaja dengan kurang daripada 10 baris kod
Feb 27, 2024 pm 01:55 PM
sangat laju! Kenali pertuturan video menjadi teks dalam beberapa minit sahaja dengan kurang daripada 10 baris kod
Feb 27, 2024 pm 01:55 PM
Hello semua, saya Kite Dua tahun lalu, keperluan untuk menukar fail audio dan video kepada kandungan teks adalah sukar dicapai, tetapi kini ia boleh diselesaikan dengan mudah dalam beberapa minit sahaja. Dikatakan bahawa untuk mendapatkan data latihan, beberapa syarikat telah merangkak sepenuhnya video pada platform video pendek seperti Douyin dan Kuaishou, dan kemudian mengekstrak audio daripada video dan menukarnya ke dalam bentuk teks untuk digunakan sebagai korpus latihan untuk data besar. model. Jika anda perlu menukar fail video atau audio kepada teks, anda boleh mencuba penyelesaian sumber terbuka yang tersedia hari ini. Sebagai contoh, anda boleh mencari titik masa tertentu apabila dialog dalam filem dan rancangan televisyen muncul. Tanpa berlengah lagi, mari kita ke intinya. Whisper ialah Whisper sumber terbuka OpenAI Sudah tentu ia ditulis dalam Python Ia hanya memerlukan beberapa pakej pemasangan yang mudah.
 Bagaimana untuk memasang pytorch dalam pycharm
Dec 08, 2023 pm 03:05 PM
Bagaimana untuk memasang pytorch dalam pycharm
Dec 08, 2023 pm 03:05 PM
Langkah pemasangan: 1. Buka PyCharm dan buat projek Python baharu 2. Di bar status bawah PyCharm, klik ikon "Terminal" untuk membuka tetingkap terminal 3. Dalam tetingkap terminal, gunakan arahan pip untuk memasang PyTorch , mengikut sistem dan keperluan, anda boleh memilih kaedah pemasangan yang berbeza 4. Selepas pemasangan selesai, anda boleh menulis kod dalam PyCharm dan mengimport perpustakaan PyTorch untuk menggunakannya.
