
mysql查询使用select命令,配合limit,offset参数可以读取指定范围的记录。本文将介绍mysql查询时,offset过大影响性能的原因及优化方法。
1.创建表
CREATE TABLE `member` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `name` varchar(10) NOT NULL COMMENT '姓名', `gender` tinyint(3) unsigned NOT NULL COMMENT '性别', PRIMARY KEY (`id`), KEY `gender` (`gender`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2.插入1000000条记录
<?php
$pdo = new PDO("mysql:host=localhost;dbname=user","root",'');for($i=0; $i<1000000; $i++){ $name = substr(md5(time().mt_rand(000,999)),0,10); $gender = mt_rand(1,2); $sqlstr = "insert into member(name,gender) values('".$name."','".$gender."')"; $stmt = $pdo->prepare($sqlstr); $stmt->execute();}
?>mysql> select count(*) from member;
+----------+| count(*) |
+----------+| 1000000 |
+----------+1 row in set (0.23 sec)
3.当前数据库版本
mysql> select version(); +-----------+| version() | +-----------+| 5.6.24 | +-----------+1 row in set (0.01 sec)
1.offset较小的情况
mysql> select * from member where gender=1 limit 10,1; +----+------------+--------+| id | name | gender | +----+------------+--------+| 26 | 509e279687 | 1 | +----+------------+--------+1 row in set (0.00 sec)mysql> select * from member where gender=1 limit 100,1; +-----+------------+--------+| id | name | gender | +-----+------------+--------+| 211 | 07c4cbca3a | 1 | +-----+------------+--------+1 row in set (0.00 sec)mysql> select * from member where gender=1 limit 1000,1; +------+------------+--------+| id | name | gender | +------+------------+--------+| 1975 | e95b8b6ca1 | 1 | +------+------------+--------+1 row in set (0.00 sec)
当offset较小时,查询速度很快,效率较高。
2.offset较大的情况
mysql> select * from member where gender=1 limit 100000,1; +--------+------------+--------+| id | name | gender | +--------+------------+--------+| 199798 | 540db8c5bc | 1 | +--------+------------+--------+1 row in set (0.12 sec)mysql> select * from member where gender=1 limit 200000,1; +--------+------------+--------+| id | name | gender | +--------+------------+--------+| 399649 | 0b21fec4c6 | 1 | +--------+------------+--------+1 row in set (0.23 sec)mysql> select * from member where gender=1 limit 300000,1; +--------+------------+--------+| id | name | gender | +--------+------------+--------+| 599465 | f48375bdb8 | 1 | +--------+------------+--------+1 row in set (0.31 sec)
当offset很大时,会出现效率问题,随着offset的增大,执行效率下降。
select * from member where gender=1 limit 300000,1;
因为数据表是InnoDB,根据InnoDB索引的结构,查询过程为:
通过二级索引查到主键值(找出所有gender=1的id)。
再根据查到的主键值通过主键索引找到相应的数据块(根据id找出对应的数据块内容)。
根据offset的值,查询300001次主键索引的数据,最后将之前的300000条丢弃,取出最后1条。
不过既然二级索引已经找到主键值,为什么还需要先用主键索引找到数据块,再根据offset的值做偏移处理呢?
如果在找到主键索引后,先执行offset偏移处理,跳过300000条,再通过第300001条记录的主键索引去读取数据块,这样就能提高效率了。
如果我们只查询出主键,看看有什么不同
mysql> select id from member where gender=1 limit 300000,1; +--------+| id | +--------+| 599465 | +--------+1 row in set (0.09 sec)
很明显,如果只查询主键,执行效率对比查询全部字段,有很大的提升。
只查询主键的情况
因为二级索引已经找到主键值,而查询只需要读取主键,因此mysql会先执行offset偏移操作,再根据后面的主键索引读取数据块。
需要查询所有字段的情况
因为二级索引只找到主键值,但其他字段的值需要读取数据块才能获取。因此mysql会先读出数据块内容,再执行offset偏移操作,最后丢弃前面需要跳过的数据,返回后面的数据。
InnoDB中有buffer pool,存放最近访问过的数据页,包括数据页和索引页。
为了测试,先把mysql重启,重启后查看buffer pool的内容。
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('primary','gender') and TABLE_NAME like '%member%' group by index_name; Empty set (0.04 sec)
可以看到,重启后,没有访问过任何的数据页。
查询所有字段,再查看buffer pool的内容
mysql> select * from member where gender=1 limit 300000,1; +--------+------------+--------+| id | name | gender | +--------+------------+--------+| 599465 | f48375bdb8 | 1 | +--------+------------+--------+1 row in set (0.38 sec)mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('primary','gender') and TABLE_NAME like '%member%' group by index_name; +------------+----------+| index_name | count(*) | +------------+----------+| gender | 261 || PRIMARY | 1385 | +------------+----------+2 rows in set (0.06 sec)
可以看出,此时buffer pool中关于member表有1385个数据页,261个索引页。
重启mysql清空buffer pool,继续测试只查询主键
mysql> select id from member where gender=1 limit 300000,1; +--------+| id | +--------+| 599465 | +--------+1 row in set (0.08 sec)mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('primary','gender') and TABLE_NAME like '%member%' group by index_name; +------------+----------+| index_name | count(*) | +------------+----------+| gender | 263 || PRIMARY | 13 | +------------+----------+2 rows in set (0.04 sec)
可以看出,此时buffer pool中关于member表只有13个数据页,263个索引页。因此减少了多次通过主键索引访问数据块的I/O操作,提高执行效率。
因此可以证实,mysql查询时,offset过大影响性能的原因是多次通过主键索引访问数据块的I/O操作。(注意,只有InnoDB有这个问题,而MYISAM索引结构与InnoDB不同,二级索引都是直接指向数据块的,因此没有此问题 )。
InnoDB与MyISAM引擎索引结构对比图
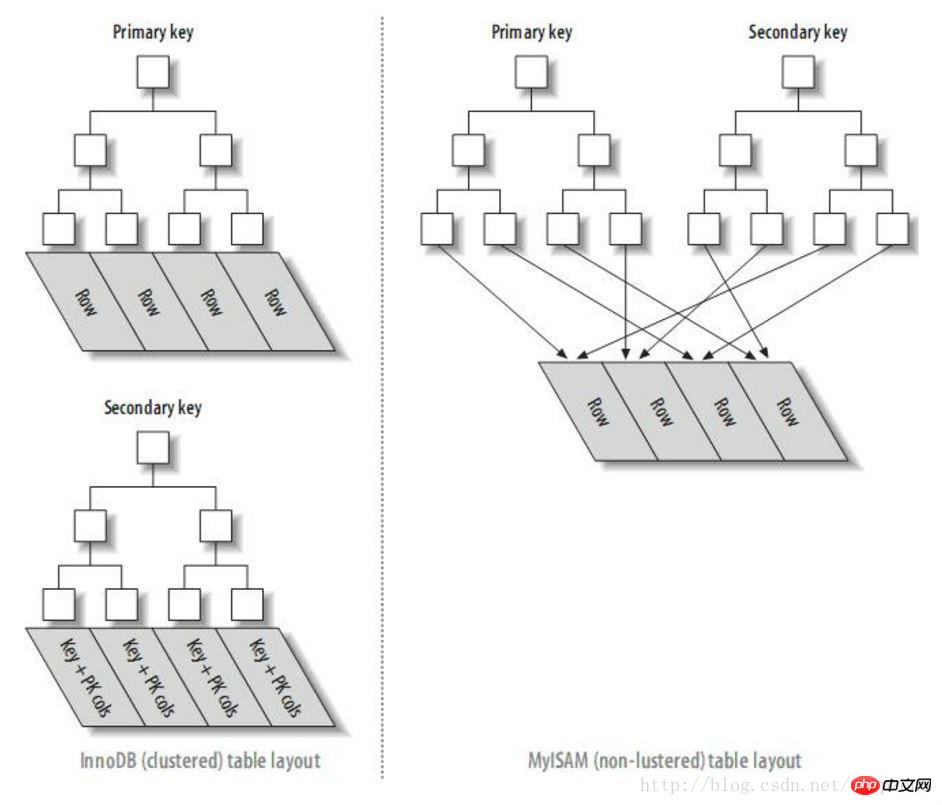
根据上面的分析,我们知道查询所有字段会导致主键索引多次访问数据块造成的I/O操作。
因此我们先查出偏移后的主键,再根据主键索引查询数据块的所有内容即可优化。
mysql> select a.* from member as a inner join (select id from member where gender=1 limit 300000,1) as b on a.id=b.id; +--------+------------+--------+| id | name | gender | +--------+------------+--------+| 599465 | f48375bdb8 | 1 | +--------+------------+--------+1 row in set (0.08 sec)
本篇文章讲解了在mysql查询时,offset过大影响性能的原因与优化方法 ,更多相关内容请关注php中文网。
相关推荐:
Atas ialah kandungan terperinci 详解在mysql查询时,offset过大影响性能的原因与优化方法. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



