

使用NodeJS编写爬虫示例
本篇文章主要给大家讲解了一下用NodeJS学习爬虫,并通过爬糗事百科来讲解用法和效果,一起学习下吧。
1.前言分析
往常都是利用 Python/.NET 语言实现爬虫,然现在作为一名前端开发人员,自然需要熟练 NodeJS。下面利用 NodeJS 语言实现一个糗事百科的爬虫。另外,本文使用的部分代码是 es6 语法。
实现该爬虫所需要的依赖库如下。
request: 利用 get 或者 post 等方法获取网页的源码。 cheerio: 对网页源码进行解析,获取所需数据。
本文首先对爬虫所需依赖库及其使用进行介绍,然后利用这些依赖库,实现一个针对糗事百科的网络爬虫。
2. request 库
request 是一个轻量级的 http 库,功能十分强大且使用简单。可以使用它实现 Http 的请求,并且支持 HTTP 认证, 自定请求头等。下面对 request 库中一部分功能进行介绍。
安装 request 模块如下:
npm install request
在安装好 request 后,即可进行使用,下面利用 request 请求一下百度的网页。
const req = require('request');
req('http://www.baidu.com', (error, response, body) => {
if (!error && response.statusCode == 200) {
console.log(body)
}
})在没有设置 options 参数时,request 方法默认是 get 请求。而我喜欢利用 request 对象的具体方法,使用如下:
req.get({
url: 'http://www.baidu.com'
},(err, res, body) => {
if (!err && res.statusCode == 200) {
console.log(body)
}
});然而很多时候,直接去请求一个网址所获取的 html 源码,往往得不到我们需要的信息。一般情况下,需要考虑到请求头和网页编码。
网页的请求头网页的编码
下面介绍在请求的时候如何添加网页请求头以及设置正确的编码。
req.get({
url : url,
headers: {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
"Host" : "www.zhihu.com",
"Upgrade-Insecure-Requests" : "1"
},
encoding : 'utf-8'
}, (err, res, body)=>{
if(!err)
console.log(body);
})设置 options 参数, 添加 headers 属性即可实现请求头的设置;添加 encoding 属性即可设置网页的编码。需要注意的是,若 encoding:null ,那么 get 请求所获取的内容则是一个 Buffer 对象,即 body 是一个 Buffer 对象。
上面介绍的功能足矣满足后面的所需了
3. cheerio 库
cheerio 是一款服务器端的 Jquery,以轻、快、简单易学等特点被开发者喜爱。有 Jquery 的基础后再来学习 cheerio 库非常轻松。它能够快速定位到网页中的元素,其规则和 Jquery 定位元素的方法是一样的;它也能以一种非常方便的形式修改 html 中的元素内容,以及获取它们的数据。下面主要针对 cheerio 快速定位网页中的元素,以及获取它们的内容进行介绍。
首先安装 cheerio 库
npm install cheerio
下面先给出一段代码,再对代码进行解释 cheerio 库的用法。对博客园首页进行分析,然后提取每一页中文章的标题。
首先对博客园首页进行分析。如下图:
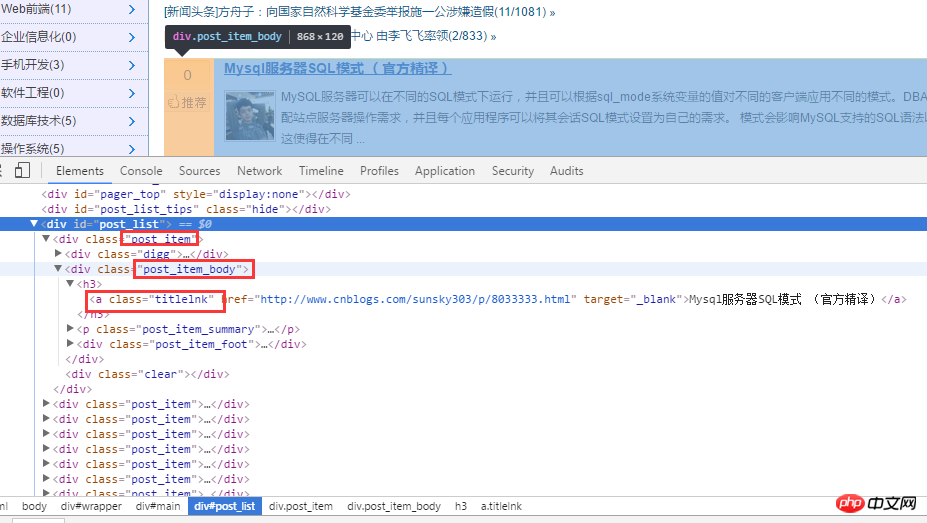
对 html 源代码进行分析后,首先通过 .post_item 获取所有标题,接着对每一个 .post_item 进行分析,使用 a.titlelnk 即可匹配每个标题的 a 标签。下面通过代码进行实现。
const req = require('request');
const cheerio = require('cheerio');
req.get({
url: 'https://www.cnblogs.com/'
}, (err, res, body) => {
if (!err && res.statusCode == 200) {
let cnblogHtmlStr = body;
let $ = cheerio.load(cnblogHtmlStr);
$('.post_item').each((index, ele) => {
let title = $(ele).find('a.titlelnk');
let titleText = title.text();
let titletUrl = title.attr('href');
console.log(titleText, titletUrl);
});
}
});当然,cheerio 库也支持链式调用,上面的代码也可改写成:
let cnblogHtmlStr = body;
let $ = cheerio.load(cnblogHtmlStr);
let titles = $('.post_item').find('a.titlelnk');
titles.each((index, ele) => {
let titleText = $(ele).text();
let titletUrl = $(ele).attr('href');
console.log(titleText, titletUrl);上面的代码非常简单,就不再用文字进行赘述了。下面总结一点自己认为比较重要的几点。
使用 find() 方法获取的节点集合 A,若再次以 A 集合中的元素为根节点定位它的子节点以及获取子元素的内容与属性,需对 A 集合中的子元素进行 $(A[i]) 包装,如上面的$(ele) 一样。在上面代码中使用 $(ele) ,其实还可以使用 $(this) 但是由于我使用的是 es6 的箭头函数,因此改变了 each 方法中回调函数的 this 指针,因此,我使用 $(ele); cheerio 库也支持链式调用,如上面的 $('.post_item').find('a.titlelnk') ,需要注意的是,cheerio 对象 A 调用方法 find(),如果 A 是一个集合,那么 A 集合中的每一个子元素都调用 find() 方法,并放回一个结果结合。如果 A 调用 text() ,那么 A 集合中的每一个子元素都调用 text() 并返回一个字符串,该字符串是所有子元素内容的合并(直接合并,没有分隔符)。
最后在总结一些我比较常用的方法。
first() last() children([selector]): 该方法和 find 类似,只不过该方法只搜索子节点,而 find 搜索整个后代节点。
4. 糗事百科爬虫
通过上面对 request 和 cheerio 类库的介绍,下面利用这两个类库对糗事百科的页面进行爬取。
1、在项目目录中,新建 httpHelper.js 文件,通过 url 获取糗事百科的网页源码,代码如下:
//爬虫
const req = require('request');
function getHtml(url){
return new Promise((resolve, reject) => {
req.get({
url : url,
headers: {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
"Referer" : "https://www.qiushibaike.com/"
},
encoding : 'utf-8'
}, (err, res, body)=>{
if(err) reject(err);
else resolve(body);
})
});
}
exports.getHtml = getHtml;2、在项目目录中,新建一个 Splider.js 文件,分析糗事百科的网页代码,提取自己需要的信息,并且建立一个逻辑通过更改 url 的 id 来爬取不同页面的数据。
const cheerio = require('cheerio');
const httpHelper = require('./httpHelper');
function getQBJok(htmlStr){
let $ = cheerio.load(htmlStr);
let jokList = $('#content-left').children('p');
let rst = [];
jokList.each((i, item)=>{
let node = $(item);
let titleNode = node.find('h2');
let title = titleNode ? titleNode.text().trim() : '匿名用户';
let content = node.find('.content span').text().trim();
let likeNumber = node.find('i[class=number]').text().trim();
rst.push({
title : title,
content : content,
likeNumber : likeNumber
});
});
return rst;
}
async function splider(index = 1){
let url = `https://www.qiushibaike.com/8hr/page/${index}/`;
let htmlStr = await httpHelper.getHtml(url);
let rst = getQBJok(htmlStr);
return rst;
}
splider(1);在获取糗事百科网页信息的时候,首先在浏览器中对源码进行分析,定位到自己所需要标签,然后提取标签的文本或者属性值,这样就完成了网页的解析。
Splider.js 文件入口是 splider 方法,首先根据传入该方法的 index 索引,构造糗事百科的 url,接着获取该 url 的网页源码,最后将获取的源码传入 getQBJok 方法,进行解析,本文只解析每条文本笑话的作者、内容以及喜欢个数。
直接运行 Splider.js 文件,即可爬取第一页的笑话信息。然后可以更改 splider 方法的参数,实现抓取不同页面的信息。
在上面已有代码的基础上,使用 koa 和 vue2.0 搭建一个浏览文本的页面,效果如下:

源码已上传到 github 上。下载地址:https://github.com/StartAction/SpliderQB ;
项目运行依赖 node v7.6.0 以上, 首先从 Github 上面克隆整个项目。
git clone https://github.com/StartAction/SpliderQB.git
克隆之后,进入项目目录,运行下面命令即可。
node app.js
上面是我整理给大家的,希望今后会对大家有帮助。
相关文章:
Atas ialah kandungan terperinci 使用NodeJS编写爬虫示例. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Perbezaan antara nodejs dan vuejs
Apr 21, 2024 am 04:17 AM
Perbezaan antara nodejs dan vuejs
Apr 21, 2024 am 04:17 AM
Node.js ialah masa jalan JavaScript bahagian pelayan, manakala Vue.js ialah rangka kerja JavaScript sisi klien untuk mencipta antara muka pengguna interaktif. Node.js digunakan untuk pembangunan bahagian pelayan, seperti pembangunan API perkhidmatan belakang dan pemprosesan data, manakala Vue.js digunakan untuk pembangunan sisi klien, seperti aplikasi satu halaman dan antara muka pengguna yang responsif.
 Adakah nodejs rangka kerja bahagian belakang?
Apr 21, 2024 am 05:09 AM
Adakah nodejs rangka kerja bahagian belakang?
Apr 21, 2024 am 05:09 AM
Node.js boleh digunakan sebagai rangka kerja bahagian belakang kerana ia menawarkan ciri seperti prestasi tinggi, kebolehskalaan, sokongan merentas platform, ekosistem yang kaya dan kemudahan pembangunan.
 Bagaimana untuk menyambungkan nodejs ke pangkalan data mysql
Apr 21, 2024 am 06:13 AM
Bagaimana untuk menyambungkan nodejs ke pangkalan data mysql
Apr 21, 2024 am 06:13 AM
Untuk menyambung ke pangkalan data MySQL, anda perlu mengikuti langkah berikut: Pasang pemacu mysql2. Gunakan mysql2.createConnection() untuk mencipta objek sambungan yang mengandungi alamat hos, port, nama pengguna, kata laluan dan nama pangkalan data. Gunakan connection.query() untuk melaksanakan pertanyaan. Akhir sekali gunakan connection.end() untuk menamatkan sambungan.
 Apakah perbezaan antara fail npm dan npm.cmd dalam direktori pemasangan nodejs?
Apr 21, 2024 am 05:18 AM
Apakah perbezaan antara fail npm dan npm.cmd dalam direktori pemasangan nodejs?
Apr 21, 2024 am 05:18 AM
Terdapat dua fail berkaitan npm dalam direktori pemasangan Node.js: npm dan npm.cmd Perbezaannya adalah seperti berikut: sambungan berbeza: npm ialah fail boleh laku dan npm.cmd ialah pintasan tetingkap arahan. Pengguna Windows: npm.cmd boleh digunakan daripada command prompt, npm hanya boleh dijalankan dari baris arahan. Keserasian: npm.cmd adalah khusus untuk sistem Windows, npm tersedia merentas platform. Cadangan penggunaan: Pengguna Windows menggunakan npm.cmd, sistem pengendalian lain menggunakan npm.
 Apakah pembolehubah global dalam nodejs
Apr 21, 2024 am 04:54 AM
Apakah pembolehubah global dalam nodejs
Apr 21, 2024 am 04:54 AM
Pembolehubah global berikut wujud dalam Node.js: Objek global: modul Teras global: proses, konsol, memerlukan pembolehubah persekitaran Runtime: __dirname, __filename, __line, __column Constants: undefined, null, NaN, Infinity, -Infinity
 Adakah terdapat perbezaan besar antara nodejs dan java?
Apr 21, 2024 am 06:12 AM
Adakah terdapat perbezaan besar antara nodejs dan java?
Apr 21, 2024 am 06:12 AM
Perbezaan utama antara Node.js dan Java ialah reka bentuk dan ciri: Didorong peristiwa vs. didorong benang: Node.js dipacu peristiwa dan Java dipacu benang. Satu-benang vs. berbilang benang: Node.js menggunakan gelung acara satu-benang dan Java menggunakan seni bina berbilang benang. Persekitaran masa jalan: Node.js berjalan pada enjin JavaScript V8, manakala Java berjalan pada JVM. Sintaks: Node.js menggunakan sintaks JavaScript, manakala Java menggunakan sintaks Java. Tujuan: Node.js sesuai untuk tugas intensif I/O, manakala Java sesuai untuk aplikasi perusahaan besar.
 Adakah nodejs bahasa pembangunan bahagian belakang?
Apr 21, 2024 am 05:09 AM
Adakah nodejs bahasa pembangunan bahagian belakang?
Apr 21, 2024 am 05:09 AM
Ya, Node.js ialah bahasa pembangunan bahagian belakang. Ia digunakan untuk pembangunan bahagian belakang, termasuk mengendalikan logik perniagaan sebelah pelayan, mengurus sambungan pangkalan data dan menyediakan API.
 Bagaimana untuk menggunakan projek nodejs ke pelayan
Apr 21, 2024 am 04:40 AM
Bagaimana untuk menggunakan projek nodejs ke pelayan
Apr 21, 2024 am 04:40 AM
Langkah-langkah penggunaan pelayan untuk projek Node.js: Sediakan persekitaran penggunaan: dapatkan akses pelayan, pasang Node.js, sediakan repositori Git. Bina aplikasi: Gunakan npm run build untuk menjana kod dan kebergantungan yang boleh digunakan. Muat naik kod ke pelayan: melalui Git atau Protokol Pemindahan Fail. Pasang kebergantungan: SSH ke dalam pelayan dan gunakan pemasangan npm untuk memasang kebergantungan aplikasi. Mulakan aplikasi: Gunakan arahan seperti node index.js untuk memulakan aplikasi, atau gunakan pengurus proses seperti pm2. Konfigurasikan proksi terbalik (pilihan): Gunakan proksi terbalik seperti Nginx atau Apache untuk menghalakan trafik ke aplikasi anda
