

node如何爬取网页中的图片(附代码)

本篇文章给大家带来的内容是关于node如何爬取网页中的图片(附代码),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。
目录
安装node,并下载依赖
搭建服务
请求我们要爬取的页面,返回json
安装node
我们开始安装node,可以去node官网下载https://nodejs.org/zh-cn/,下载完成后运行node使用,
node -v
安装成功后会出现你所安装的版本号。
接下来我们使用node, 打印出hello world,新建一个名为index.js文件输入
console.log('hello world')
运行这个文件
node index.js
就会在控制面板上输出hello world
搭建服务器
新建一个·名为node的文件夹。
首先你需要下载express依赖
npm install express
再新建一个名为demo.js的文件 目录结构如图:

在demo.js引入下载的express
const express = require('express');
const app = express();
app.get('/index', function(req, res) {
res.end('111')
})
var server = app.listen(8081, function() {
var host = server.address().address
var port = server.address().port
console.log("应用实例,访问地址为 http://%s:%s", host, port)
})运行node demo.js简单的服务就搭起来了,如图: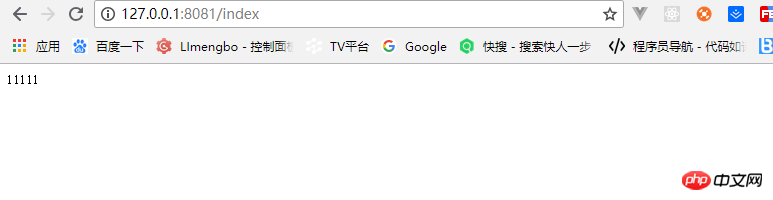
请求我们要爬取的页面
请求我们要爬取的页面
npm install superagent npm install superagent-charset npm install cheerio
superagent 是用来发起请求的,是一个轻量的,渐进式的ajax api,可读性好,学习曲线低,内部依赖nodejs原生的请求api,适用于nodejs环境下.,也可以使用http发起请求
superagent-charset防止爬取下来的数据乱码,更改字符格式
cheerio为服务器特别定制的,快速、灵活、实施的jQuery核心实现.。 安装完依赖就可以引入了
var superagent = require('superagent'); var charset = require('superagent-charset'); charset(superagent); const cheerio = require('cheerio');
引入之后就请求我们的地址,https://www.qqtn.com/tx/weixintx_1.html,如图:
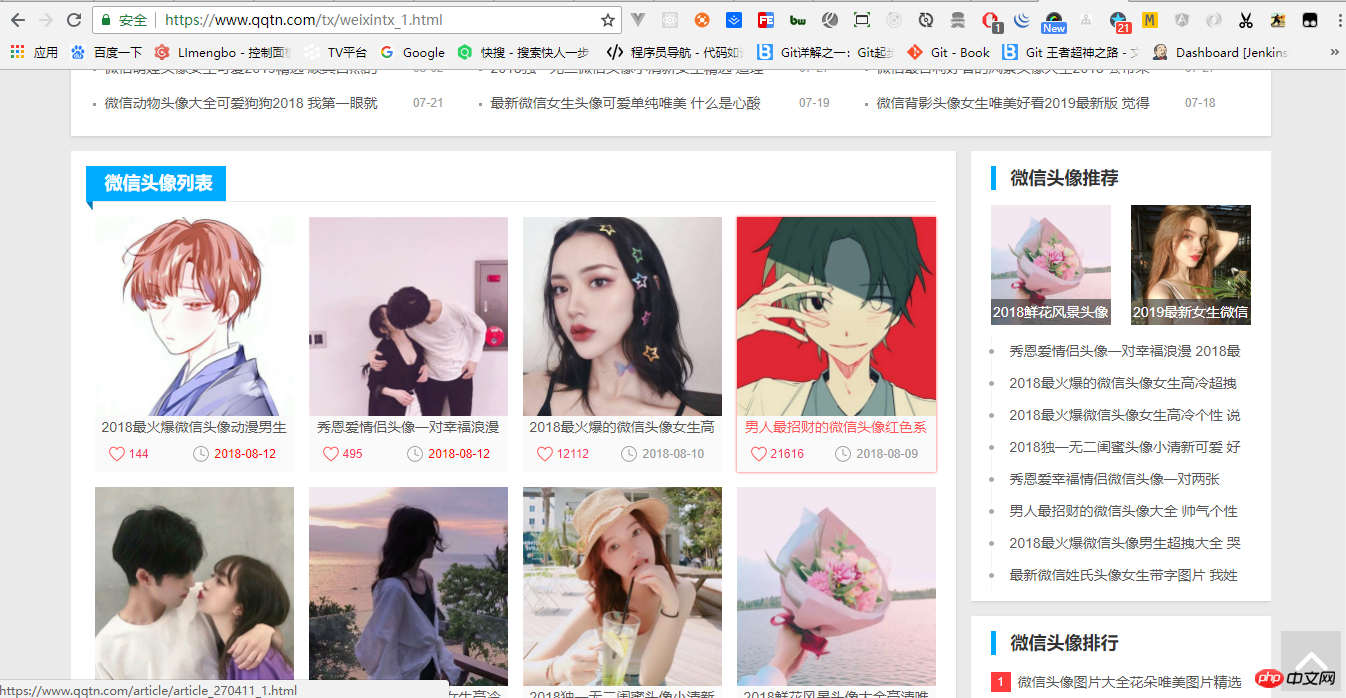
声明地址变量:
const baseUrl = 'https://www.qqtn.com/'
这些设置完之后就是发请求了,接下来请看完整代码demo.js
var superagent = require('superagent');
var charset = require('superagent-charset');
charset(superagent);
var express = require('express');
var baseUrl = 'https://www.qqtn.com/'; //输入任何网址都可以
const cheerio = require('cheerio');
var app = express();
app.get('/index', function(req, res) {
//设置请求头
res.header("Access-Control-Allow-Origin", "*");
res.header('Access-Control-Allow-Methods', 'PUT, GET, POST, DELETE, OPTIONS');
res.header("Access-Control-Allow-Headers", "X-Requested-With");
res.header('Access-Control-Allow-Headers', 'Content-Type');
//类型
var type = req.query.type;
//页码
var page = req.query.page;
type = type || 'weixin';
page = page || '1';
var route = `tx/${type}tx_${page}.html`
//网页页面信息是gb2312,所以chaeset应该为.charset('gb2312'),一般网页则为utf-8,可以直接使用.charset('utf-8')
superagent.get(baseUrl + route)
.charset('gb2312')
.end(function(err, sres) {
var items = [];
if (err) {
console.log('ERR: ' + err);
res.json({ code: 400, msg: err, sets: items });
return;
}
var $ = cheerio.load(sres.text);
$('div.g-main-bg ul.g-gxlist-imgbox li a').each(function(idx, element) {
var $element = $(element);
var $subElement = $element.find('img');
var thumbImgSrc = $subElement.attr('src');
items.push({
title: $(element).attr('title'),
href: $element.attr('href'),
thumbSrc: thumbImgSrc
});
});
res.json({ code: 200, msg: "", data: items });
});
});
var server = app.listen(8081, function() {
var host = server.address().address
var port = server.address().port
console.log("应用实例,访问地址为 http://%s:%s", host, port)
})运行demo.js就会返回我们拿到的数据,如图:
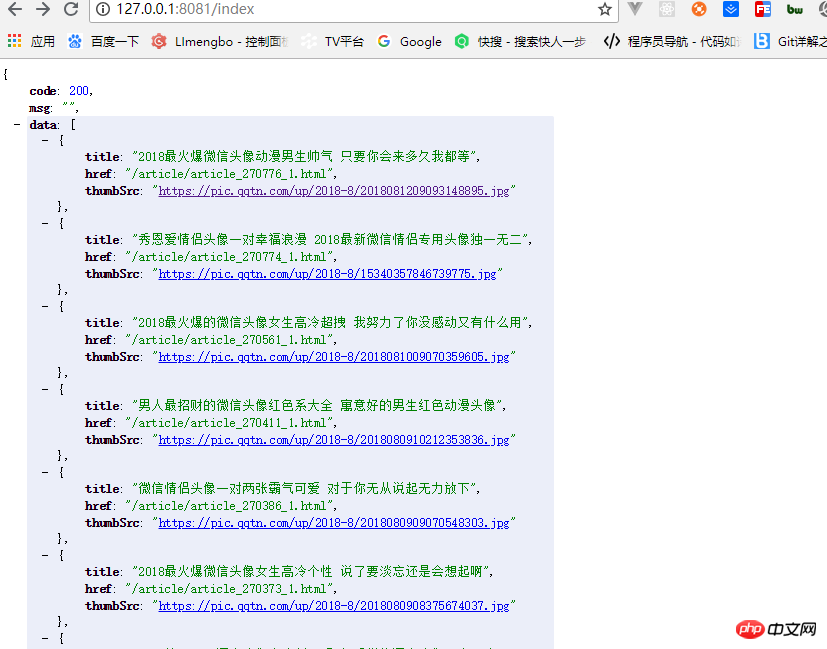
一个简单的node爬虫就完成了。
相关推荐:
node爬虫之gbk网页中文乱码解决方案_html/css_WEB-ITnose
Atas ialah kandungan terperinci node如何爬取网页中的图片(附代码). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1653
1653
 14
1413
52
1304
25
1251
29
1224
24
14
1413
52
1304
25
1251
29
1224
24

 Apa yang perlu saya lakukan jika saya menghadapi percetakan kod yang dihiasi untuk resit kertas terma depan?
Apr 04, 2025 pm 02:42 PM
Apa yang perlu saya lakukan jika saya menghadapi percetakan kod yang dihiasi untuk resit kertas terma depan?
Apr 04, 2025 pm 02:42 PM
Soalan dan penyelesaian yang sering ditanya untuk percetakan tiket kertas terma depan dalam pembangunan front-end, percetakan tiket adalah keperluan umum. Walau bagaimanapun, banyak pemaju sedang melaksanakan ...
 Demystifying JavaScript: Apa yang berlaku dan mengapa penting
Apr 09, 2025 am 12:07 AM
Demystifying JavaScript: Apa yang berlaku dan mengapa penting
Apr 09, 2025 am 12:07 AM
JavaScript adalah asas kepada pembangunan web moden, dan fungsi utamanya termasuk pengaturcaraan yang didorong oleh peristiwa, penjanaan kandungan dinamik dan pengaturcaraan tak segerak. 1) Pengaturcaraan yang didorong oleh peristiwa membolehkan laman web berubah secara dinamik mengikut operasi pengguna. 2) Penjanaan kandungan dinamik membolehkan kandungan halaman diselaraskan mengikut syarat. 3) Pengaturcaraan Asynchronous memastikan bahawa antara muka pengguna tidak disekat. JavaScript digunakan secara meluas dalam interaksi web, aplikasi satu halaman dan pembangunan sisi pelayan, sangat meningkatkan fleksibiliti pengalaman pengguna dan pembangunan silang platform.
 Siapa yang dibayar lebih banyak Python atau JavaScript?
Apr 04, 2025 am 12:09 AM
Siapa yang dibayar lebih banyak Python atau JavaScript?
Apr 04, 2025 am 12:09 AM
Tidak ada gaji mutlak untuk pemaju Python dan JavaScript, bergantung kepada kemahiran dan keperluan industri. 1. Python boleh dibayar lebih banyak dalam sains data dan pembelajaran mesin. 2. JavaScript mempunyai permintaan yang besar dalam perkembangan depan dan stack penuh, dan gajinya juga cukup besar. 3. Faktor mempengaruhi termasuk pengalaman, lokasi geografi, saiz syarikat dan kemahiran khusus.
 Bagaimana untuk mencapai kesan menatal paralaks dan kesan animasi elemen, seperti laman web rasmi Shiseido?
atau:
Bagaimanakah kita dapat mencapai kesan animasi yang disertai dengan menatal halaman seperti laman web rasmi Shiseido?
Apr 04, 2025 pm 05:36 PM
Bagaimana untuk mencapai kesan menatal paralaks dan kesan animasi elemen, seperti laman web rasmi Shiseido?
atau:
Bagaimanakah kita dapat mencapai kesan animasi yang disertai dengan menatal halaman seperti laman web rasmi Shiseido?
Apr 04, 2025 pm 05:36 PM
Perbincangan mengenai realisasi kesan animasi tatal dan elemen Parallax dalam artikel ini akan meneroka bagaimana untuk mencapai yang serupa dengan laman web rasmi Shiseido (https://www.shiseido.co.jp/sb/wonderland/) ... ...
 Adakah JavaScript sukar belajar?
Apr 03, 2025 am 12:20 AM
Adakah JavaScript sukar belajar?
Apr 03, 2025 am 12:20 AM
Pembelajaran JavaScript tidak sukar, tetapi ia mencabar. 1) Memahami konsep asas seperti pembolehubah, jenis data, fungsi, dan sebagainya. 2) Pengaturcaraan asynchronous tuan dan melaksanakannya melalui gelung acara. 3) Gunakan operasi DOM dan berjanji untuk mengendalikan permintaan tak segerak. 4) Elakkan kesilapan biasa dan gunakan teknik debugging. 5) Mengoptimumkan prestasi dan mengikuti amalan terbaik.
 Evolusi JavaScript: Trend Semasa dan Prospek Masa Depan
Apr 10, 2025 am 09:33 AM
Evolusi JavaScript: Trend Semasa dan Prospek Masa Depan
Apr 10, 2025 am 09:33 AM
Trend terkini dalam JavaScript termasuk kebangkitan TypeScript, populariti kerangka dan perpustakaan moden, dan penerapan webassembly. Prospek masa depan meliputi sistem jenis yang lebih berkuasa, pembangunan JavaScript, pengembangan kecerdasan buatan dan pembelajaran mesin, dan potensi pengkomputeran IoT dan kelebihan.
 Bagaimana untuk menggabungkan elemen array dengan ID yang sama ke dalam satu objek menggunakan JavaScript?
Apr 04, 2025 pm 05:09 PM
Bagaimana untuk menggabungkan elemen array dengan ID yang sama ke dalam satu objek menggunakan JavaScript?
Apr 04, 2025 pm 05:09 PM
Bagaimana cara menggabungkan elemen array dengan ID yang sama ke dalam satu objek dalam JavaScript? Semasa memproses data, kita sering menghadapi keperluan untuk mempunyai id yang sama ...
 Bagaimana untuk melaksanakan fungsi seretan panel dan drop pelarasan yang serupa dengan vscode dalam pembangunan front-end?
Apr 04, 2025 pm 02:06 PM
Bagaimana untuk melaksanakan fungsi seretan panel dan drop pelarasan yang serupa dengan vscode dalam pembangunan front-end?
Apr 04, 2025 pm 02:06 PM
Terokai pelaksanaan fungsi seretan panel dan drop panel seperti VSCode di bahagian depan. Dalam pembangunan front-end, bagaimana untuk melaksanakan vscode seperti ...
