

分布式的系统核心日志的详细介绍(图文)

本篇文章给大家带来的内容是关于分布式的系统核心日志的详细介绍(图文),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。
什么是日志?
日志就是按照时间顺序追加的、完全有序的记录序列,其实就是一种特殊的文件格式,文件是一个字节数组,而这里日志是一个记录数据,只是相对于文件来说,这里每条记录都是按照时间的相对顺序排列的,可以说日志是最简单的一种存储模型,读取一般都是从左到右,例如消息队列,一般是线性写入log文件,消费者顺序从offset开始读取。
由于日志本身固有的特性,记录从左向右开始顺序插入,也就意味着左边的记录相较于右边的记录“更老”, 也就是说我们可以不用依赖于系统时钟,这个特性对于分布式系统来说相当重要。
日志的应用
日志在数据库中的应用
日志是什么时候出现已经无从得知,可能是概念上来讲太简单。在数据库领域中日志更多的是用于在系统crash的时候同步数据以及索引等,例如MySQL中的redo log,redo log是一种基于磁盘的数据结构,用于在系统挂掉的时候保证数据的正确性、完整性,也叫预写日志,例如在一个事物的执行过程中,首先会写redo log,然后才会应用实际的更改,这样当系统crash后恢复时就能够根据redo log进行重放从而恢复数据(在初始化的过程中,这个时候不会还没有客户端的连接)。日志也可以用于数据库主从之间的同步,因为本质上,数据库所有的操作记录都已经写入到了日志中,我们只要将日志同步到slave,并在slave重放就能够实现主从同步,这里也可以实现很多其他需要的组件,我们可以通过订阅redo log 从而拿到数据库所有的变更,从而实现个性化的业务逻辑,例如审计、缓存同步等等。
日志在分布式系统中的应用
分布式系统服务本质上就是关于状态的变更,这里可以理解为状态机,两个独立的进程(不依赖于外部环境,例如系统时钟、外部接口等)给定一致的输入将会产生一致的输出并最终保持一致的状态,而日志由于其固有的顺序性并不依赖系统时钟,正好可以用来解决变更有序性的问题。
我们利用这个特性实现解决分布式系统中遇到的很多问题。例如RocketMQ中的备节点,主broker接收客户端的请求,并记录日志,然后实时同步到salve中,slave在本地重放,当master挂掉的时候,slave可以继续处理请求,例如拒绝写请求并继续处理读请求。日志中不仅仅可以记录数据,也可以直接记录操作,例如SQL语句。
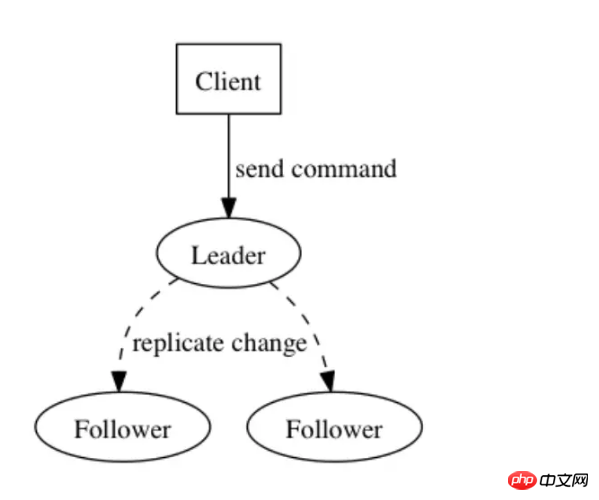
日志是解决一致性问题的关键数据结构,日志就像是操作序列,每一条记录代表一条指令,例如应用广泛的Paxos、Raft协议,都是基于日志构建起来的一致性协议。
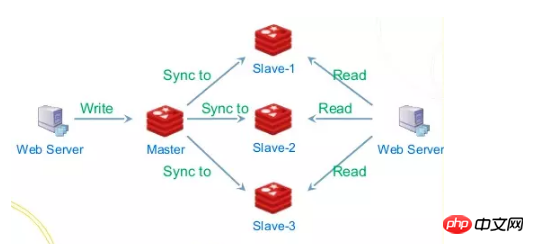
日志在Message Queue中的应用
日志可以很方便的用于处理数据之间的流入流出,每一个数据源都可以产生自己的日志,这里数据源可以来自各个方面,例如某个事件流(页面点击、缓存刷新提醒、数据库binlog变更),我们可以将日志集中存储到一个集群中,订阅者可以根据offset来读取日志的每条记录,根据每条记录中的数据、操作应用自己的变更。
这里的日志可以理解为消息队列,消息队列可以起到异步解耦、限流的作用。为什么说解耦呢?因为对于消费者、生产者来说,两个角色的职责都很清晰,就负责生产消息、消费消息,而不用关心下游、上游是谁,不管是来数据库的变更日志、某个事件也好,对于某一方来说我根本不需要关心,我只需要关注自己感兴趣的日志以及日志中的每条记录。
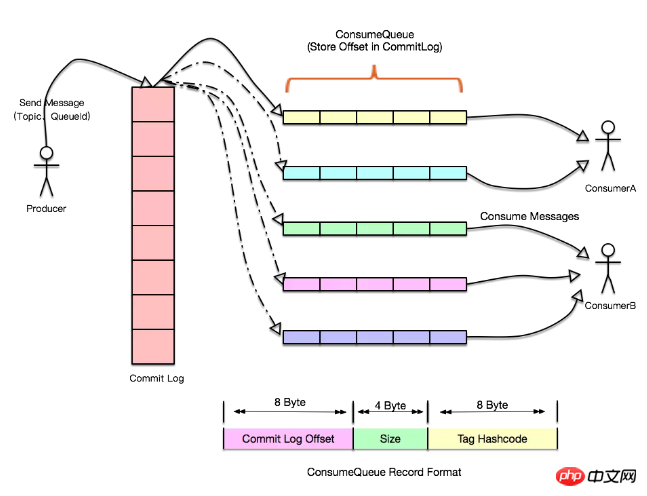
我们知道数据库的QPS是一定的,而上层应用一般可以横向扩容,这个时候如果到了双11这种请求突然的场景,数据库会吃不消,那么我们就可以引入消息队列,将每个队数据库的操作写到日志中,由另外一个应用专门负责消费这些日志记录并应用到数据库中,而且就算数据库挂了,当恢复的时候也可以从上次消息的位置继续处理(RocketMQ和Kafka都支持Exactly Once语义),这里即使生产者的速度异于消费者的速度也不会有影响,日志在这里起到了缓冲的作用,它可以将所有的记录存储到日志中,并定时同步到slave节点,这样消息的积压能力能够得到很好的提升,因为写日志都是有master节点处理,读请求这里分为两种,一种是tail-read,就是说消费速度能够跟得上写入速度的,这种读可以直接走缓存,而另一种也就是落后于写入请求的消费者,这种可以从slave节点读取,这样通过IO隔离以及操作系统自带的一些文件策略,例如pagecache、缓存预读等,性能可以得到很大的提升。
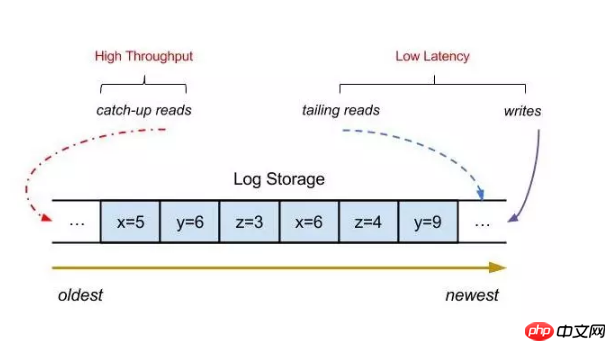
分布式系统中可横向扩展是一个相当重要的特性,加机器能解决的问题都不是问题。那么如何实现一个能够实现横向扩展的消息队列呢? 假如我们有一个单机的消息队列,随着topic数目的上升,IO、CPU、带宽等都会逐渐成为瓶颈,性能会慢慢下降,那么这里如何进行性能优化呢?
1.topic/日志分片,本质上topic写入的消息就是日志的记录,那么随着写入的数量越多,单机会慢慢的成为瓶颈,这个时候我们可以将单个topic分为多个子topic,并将每个topic分配到不同的机器上,通过这种方式,对于那些消息量极大的topic就可以通过加机器解决,而对于一些消息量较少的可以分到到同一台机器或不进行分区
2.group commit,例如Kafka的producer客户端,写入消息的时候,是先写入一个本地内存队列,然后将消息按照每个分区、节点汇总,进行批量提交,对于服务器端或者broker端,也可以利用这种方式,先写入pagecache,再定时刷盘,刷盘的方式可以根据业务决定,例如金融业务可能会采取同步刷盘的方式。
3.规避无用的数据拷贝
4.IO隔离
结语
日志在分布式系统中扮演了很重要的角色,是理解分布式系统各个组件的关键,随着理解的深入,我们发现很多分布式中间件都是基于日志进行构建的,例如Zookeeper、HDFS、Kafka、RocketMQ、Google Spanner等等,甚至于数据库,例如Redis、MySQL等等,其master-slave都是基于日志同步的方式,依赖共享的日志系统,我们可以实现很多系统: 节点间数据同步、并发更新数据顺序问题(一致性问题)、持久性(系统crash时能够通过其他节点继续提供服务)、分布式锁服务等等,相信慢慢的通过实践、以及大量的论文阅读之后,一定会有更深层次的理解。
Atas ialah kandungan terperinci 分布式的系统核心日志的详细介绍(图文). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Apakah ID acara 6013 dalam win10?
Jan 09, 2024 am 10:09 AM
Apakah ID acara 6013 dalam win10?
Jan 09, 2024 am 10:09 AM
Log win10 boleh membantu pengguna memahami penggunaan sistem secara terperinci Ramai pengguna mesti menemui log 6013 apabila mencari log pengurusan mereka sendiri. Apakah log win10 6013: 1. Ini log biasa. Maklumat dalam log ini tidak bermakna bahawa komputer anda telah dimulakan semula, tetapi ia menunjukkan berapa lama sistem telah berjalan sejak kali terakhir ia dimulakan. Log ini akan muncul sekali setiap hari pada pukul 12 tepat. Bagaimana untuk menyemak berapa lama sistem telah berjalan Anda boleh memasukkan info sistem dalam cmd. Terdapat satu baris di dalamnya.
 Saiz penimbal pembalak untuk kegunaan log
Mar 13, 2023 pm 04:27 PM
Saiz penimbal pembalak untuk kegunaan log
Mar 13, 2023 pm 04:27 PM
Fungsinya adalah untuk memberi maklum balas kepada jurutera mengenai maklumat penggunaan dan rekod untuk memudahkan analisis masalah (digunakan semasa pembangunan); Penampan pembalakan ialah kawasan kecil sementara yang digunakan untuk penyimpanan jangka pendek vektor perubahan bagi log semula untuk ditulis pada cakera. Log penimbal tulis ke cakera ialah kumpulan vektor perubahan daripada berbilang transaksi. Walaupun begitu, vektor perubahan dalam penimbal log ditulis ke cakera dalam hampir masa nyata, dan apabila sesi mengeluarkan kenyataan COMMIT, operasi tulis penimbal log dilakukan dalam masa nyata.
 Menyelesaikan masalah Isu Log Ralat Acara 7034 dalam Win10
Jan 11, 2024 pm 02:06 PM
Menyelesaikan masalah Isu Log Ralat Acara 7034 dalam Win10
Jan 11, 2024 pm 02:06 PM
Log win10 boleh membantu pengguna memahami penggunaan sistem secara terperinci Ramai pengguna telah melihat banyak log ralat semasa mencari log pengurusan mereka sendiri. Bagaimana untuk menyelesaikan peristiwa log win10 7034: 1. Klik "Mula" untuk membuka "Panel Kawalan" 2. Cari "Alat Pentadbiran" 3. Klik "Perkhidmatan" 4. Cari HDZBCommServiceForV2.0, klik kanan "Stop Service" dan ubahnya kepada "Mula Manual"
 Cara menggunakan pengelogan dalam ThinkPHP6
Jun 20, 2023 am 08:37 AM
Cara menggunakan pengelogan dalam ThinkPHP6
Jun 20, 2023 am 08:37 AM
Dengan perkembangan pesat Internet dan aplikasi Web, pengurusan log menjadi semakin penting. Apabila membangunkan aplikasi web, cara mencari dan mencari masalah adalah isu yang sangat kritikal. Sistem pembalakan ialah alat yang sangat berkesan yang boleh membantu kami mencapai tugasan ini. ThinkPHP6 menyediakan sistem pengelogan berkuasa yang boleh membantu pembangun aplikasi mengurus dan menjejaki peristiwa yang berlaku dalam aplikasi dengan lebih baik. Artikel ini akan memperkenalkan cara menggunakan sistem pembalakan dalam ThinkPHP6 dan cara menggunakan sistem pembalakan
 Cara melihat sejarah log ubat anda dalam apl Kesihatan pada iPhone
Nov 29, 2023 pm 08:46 PM
Cara melihat sejarah log ubat anda dalam apl Kesihatan pada iPhone
Nov 29, 2023 pm 08:46 PM
iPhone membolehkan anda menambah ubat dalam apl Kesihatan untuk menjejak dan mengurus ubat, vitamin dan suplemen yang anda ambil setiap hari. Anda kemudian boleh log ubat yang telah anda ambil atau langkau apabila anda menerima pemberitahuan pada peranti anda. Selepas anda mencatatkan ubat anda, anda boleh melihat kekerapan anda mengambil atau melangkaunya untuk membantu anda menjejaki kesihatan anda. Dalam siaran ini, kami akan membimbing anda untuk melihat sejarah log ubat yang dipilih dalam apl Kesihatan pada iPhone. Panduan ringkas tentang cara melihat sejarah log ubat anda dalam Apl Kesihatan: Pergi ke Apl Kesihatan>Semak imbas>Ubat>Ubat>Pilih Ubat>Pilihan&a
 Penjelasan terperinci tentang arahan melihat log dalam sistem Linux!
Mar 06, 2024 pm 03:55 PM
Penjelasan terperinci tentang arahan melihat log dalam sistem Linux!
Mar 06, 2024 pm 03:55 PM
Dalam sistem Linux, anda boleh menggunakan arahan berikut untuk melihat kandungan fail log: perintah ekor: Perintah ekor digunakan untuk memaparkan kandungan pada akhir fail log. Ia adalah arahan biasa untuk melihat maklumat log terkini. ekor [pilihan] [nama fail] Pilihan yang biasa digunakan termasuk: -n: Tentukan bilangan baris yang akan dipaparkan, lalai ialah 10 baris. -f: Pantau kandungan fail dalam masa nyata dan secara automatik memaparkan kandungan baharu apabila fail dikemas kini. Contoh: tail-n20logfile.txt#Paparkan 20 baris terakhir fail logfile.txt tail-flogfile.txt#Pantau kandungan kemas kini fail logfile.txt dalam arahan kepala masa nyata: Perintah kepala digunakan untuk memaparkan permulaan daripada fail log
 Fahami maksud acara ID455 dalam log win10
Jan 12, 2024 pm 09:45 PM
Fahami maksud acara ID455 dalam log win10
Jan 12, 2024 pm 09:45 PM
Log win10 mempunyai banyak kandungan yang kaya. Ramai pengguna mesti melihat ralat paparan ID455 semasa mencari log pengurusan mereka sendiri. Jadi apa maksudnya. Apakah peristiwa ID455 dalam log win10: 1. ID455 ialah ralat <ralat> yang berlaku dalam <fail> apabila stor maklumat membuka fail log.
 Tiga arahan untuk melihat log dalam Linux
Jan 04, 2023 pm 02:00 PM
Tiga arahan untuk melihat log dalam Linux
Jan 04, 2023 pm 02:00 PM
Tiga arahan untuk melihat log dalam Linux ialah: 1. perintah ekor, yang boleh melihat perubahan dalam kandungan fail dan fail log dalam masa nyata 2. perintah berbilang ekor, yang boleh memantau berbilang fail log pada masa yang sama; yang boleh Perubahan pada log boleh dilihat dengan cepat tanpa mengacaukan skrin.
