

Python中顺序表算法复杂度的相关知识介绍

本篇文章给大家带来的内容是关于Python中顺序表算法复杂度的相关知识介绍,有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。
一.算法复杂度的引入
对于算法的时间和空间性质,最重要的是其量级和趋势,所以衡量其复杂度的函数常量因子可以忽略不计.
大O记法通常是某一算法的渐进时间复杂度,常用的渐进复杂度函数复杂度比较如下:
O(1)<O(logn)<O(n)<O(nlogn)<O(n^2)<O(n^3)<O(2^n)<O(n!)<O(n^n)
引入时间复杂度的例子,请比较两段代码的例子,看其计算的结果
import time
start_time = time.time()
for a in range(0,1001):
for b in range(0,1001):
for c in range(0,1001):
if a+b+c ==1000 and a**2 + b**2 == c**2:
print("a, b, c :%d, %d, %d" % (a, b ,c))
end_time = time.time()
print("times:%d" % (end_time-start_time))
print("完成")

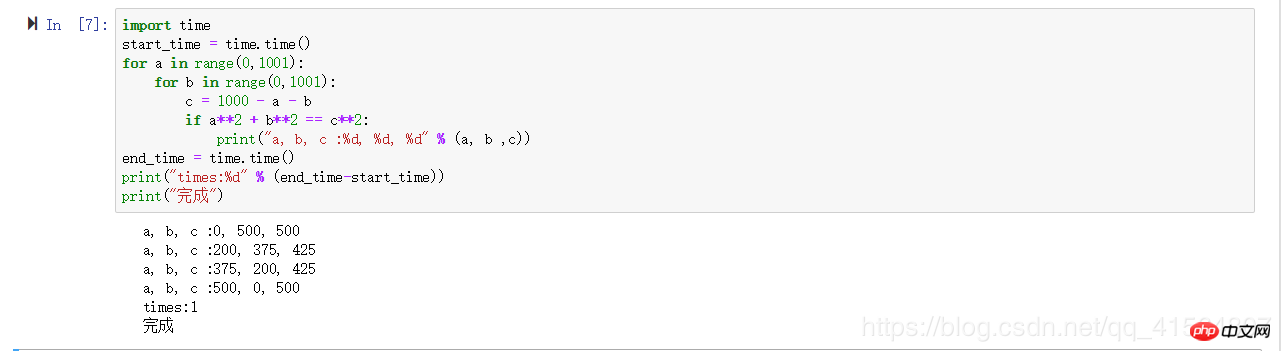
import time
start_time = time.time()
for a in range(0,1001):
for b in range(0,1001):
c = 1000 - a - b
if a**2 + b**2 == c**2:
print("a, b, c :%d, %d, %d" % (a, b ,c))
end_time = time.time()
print("times:%d" % (end_time-start_time))
print("完成")
如何计算时间复杂度:
# 时间复杂度计算 # 1.基本步骤,基本操作,复杂度是O(1) # 2.顺序结构,按加法计算 # 3.循环,按照乘法 # 4.分支结构采用其中最大值 # 5.计算复杂度,只看最高次项,例如n^2+2的复杂度是O(n^2)
二.顺序表的时间复杂度
列表时间复杂度的测试
# 测试
from timeit import Timer
def test1():
list1 = []
for i in range(10000):
list1.append(i)
def test2():
list2 = []
for i in range(10000):
# list2 += [i] # +=本身有优化,所以不完全等于list = list + [i]
list2 = list2 + [i]
def test3():
list3 = [i for i in range(10000)]
def test4():
list4 = list(range(10000))
def test5():
list5 = []
for i in range(10000):
list5.extend([i])
timer1 = Timer("test1()","from __main__ import test1")
print("append:",timer1.timeit(1000))
timer2 = Timer("test2()","from __main__ import test2")
print("+:",timer2.timeit(1000))
timer3 = Timer("test3()","from __main__ import test3")
print("[i for i in range]:",timer3.timeit(1000))
timer4 = Timer("test4()","from __main__ import test4")
print("list(range):",timer4.timeit(1000))
timer5 = Timer("test5()","from __main__ import test5")
print("extend:",timer5.timeit(1000))
输出结果

列表中方法的复杂度:
# 列表方法中复杂度 # index O(1) # append 0(1) # pop O(1) 无参数表示是从尾部向外取数 # pop(i) O(n) 从指定位置取,也就是考虑其最复杂的状况是从头开始取,n为列表的长度 # del O(n) 是一个个删除 # iteration O(n) # contain O(n) 其实就是in,也就是说需要遍历一遍 # get slice[x:y] O(K) 取切片,即K为Y-X # del slice O(n) 删除切片 # set slice O(n) 设置切片 # reverse O(n) 逆置 # concatenate O(k) 将两个列表加到一起,K为第二个列表的长度 # sort O(nlogn) 排序,和排序算法有关 # multiply O(nk) K为列表的长度
字典中方法的复杂度(补充)
# 字典中的复杂度 # copy O(n) # get item O(1) # set item O(1) 设置 # delete item O(1) # contains(in) O(1) 字典不用遍历,所以可以一次找到 # iteration O(n)
三.顺序表的数据结构
一个顺序表的完整信息包括两部分,一部分是表中的元素集合,另一部分是为实现正确操作而需要记录的信息这部分信息主要包括元素存储区的容量和当前表中已有的元素个数两项。
表头和数据区的组合:一体式结构:表头信息(记录容量和已有元素个数的信息)和数据区做连续储存
分离式结构:表头信息和数据区并不是连续存储的,会多处一部分信息用来存储地址单元,用来指向真实的数据区
两者差别和优劣:
# 1.一体式结构:数据必须整体迁移 # 2.分离式结构:在数据动态的过错中有优势
# 申请多大的空间? # 扩充政策: # 1.每次增加相同的空间,线性增长 # 特点:节省空间但操作次数多 # 2.每次扩容加倍,例如每次扩充增加一倍 # 特点:减少执行次数,用空间换效率 # 数据表的操作: # 1.增加元素: # a.尾端加入元素,时间复杂度为O(1) # b.非保序的元素插入:O(1) # c.保序的元素插入:时间度杂度O(n)(保序不改变其原有的顺序) # 2.删除元素: # a.末尾:时间复杂度:O(1) # b.非保序:O(1) # c.保序:O(n) # python中list与tuple采用了顺序表的实现技术 # list可以按照下标索引,时间度杂度O(1),采用的是分离式的存储区,动态顺序表
四. python中变量空间扩充的策略
1.在建立空表(或很小的表)时,系统分配的是一块能容纳8个元素的存储区
2.在执行插入操作(insert,append)时,如果元素存储区满就换一块四倍大的存储区
3.如果此时的表已经很大(阀值是50000),则改变政策,采用加一倍的方法。为了避免出现过多空闲的空间。
Atas ialah kandungan terperinci Python中顺序表算法复杂度的相关知识介绍. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Artikel ini memperkenalkan operasi pangkalan data MySQL. Pertama, anda perlu memasang klien MySQL, seperti MySqlworkbench atau Command Line Client. 1. Gunakan perintah MySQL-Uroot-P untuk menyambung ke pelayan dan log masuk dengan kata laluan akaun root; 2. Gunakan CreateTatabase untuk membuat pangkalan data, dan gunakan Pilih pangkalan data; 3. Gunakan createtable untuk membuat jadual, menentukan medan dan jenis data; 4. Gunakan InsertInto untuk memasukkan data, data pertanyaan, kemas kini data dengan kemas kini, dan padam data dengan padam. Hanya dengan menguasai langkah -langkah ini, belajar menangani masalah biasa dan mengoptimumkan prestasi pangkalan data anda boleh menggunakan MySQL dengan cekap.
 Bagaimanakah Feathering PS mengawal kelembutan peralihan?
Apr 06, 2025 pm 07:33 PM
Bagaimanakah Feathering PS mengawal kelembutan peralihan?
Apr 06, 2025 pm 07:33 PM
Kunci kawalan bulu adalah memahami sifatnya secara beransur -ansur. PS sendiri tidak menyediakan pilihan untuk mengawal lengkung kecerunan secara langsung, tetapi anda boleh melaraskan radius dan kelembutan kecerunan dengan pelbagai bulu, topeng yang sepadan, dan pilihan halus untuk mencapai kesan peralihan semula jadi.
 Adakah Mysql perlu membayar
Apr 08, 2025 pm 05:36 PM
Adakah Mysql perlu membayar
Apr 08, 2025 pm 05:36 PM
MySQL mempunyai versi komuniti percuma dan versi perusahaan berbayar. Versi komuniti boleh digunakan dan diubahsuai secara percuma, tetapi sokongannya terhad dan sesuai untuk aplikasi dengan keperluan kestabilan yang rendah dan keupayaan teknikal yang kuat. Edisi Enterprise menyediakan sokongan komersil yang komprehensif untuk aplikasi yang memerlukan pangkalan data yang stabil, boleh dipercayai, berprestasi tinggi dan bersedia membayar sokongan. Faktor yang dipertimbangkan apabila memilih versi termasuk kritikal aplikasi, belanjawan, dan kemahiran teknikal. Tidak ada pilihan yang sempurna, hanya pilihan yang paling sesuai, dan anda perlu memilih dengan teliti mengikut keadaan tertentu.
 Bagaimana cara menyediakan bulu ps?
Apr 06, 2025 pm 07:36 PM
Bagaimana cara menyediakan bulu ps?
Apr 06, 2025 pm 07:36 PM
PS Feathering adalah kesan kabur tepi imej, yang dicapai dengan purata piksel berwajaran di kawasan tepi. Menetapkan jejari bulu dapat mengawal tahap kabur, dan semakin besar nilai, semakin kaburnya. Pelarasan fleksibel radius dapat mengoptimumkan kesan mengikut imej dan keperluan. Sebagai contoh, menggunakan jejari yang lebih kecil untuk mengekalkan butiran apabila memproses foto watak, dan menggunakan radius yang lebih besar untuk mewujudkan perasaan kabur ketika memproses karya seni. Walau bagaimanapun, perlu diperhatikan bahawa terlalu besar jejari boleh dengan mudah kehilangan butiran kelebihan, dan terlalu kecil kesannya tidak akan jelas. Kesan bulu dipengaruhi oleh resolusi imej dan perlu diselaraskan mengikut pemahaman imej dan kesan genggaman.
 Cara mengoptimumkan prestasi pangkalan data selepas pemasangan MySQL
Apr 08, 2025 am 11:36 AM
Cara mengoptimumkan prestasi pangkalan data selepas pemasangan MySQL
Apr 08, 2025 am 11:36 AM
Pengoptimuman prestasi MySQL perlu bermula dari tiga aspek: konfigurasi pemasangan, pengindeksan dan pengoptimuman pertanyaan, pemantauan dan penalaan. 1. Selepas pemasangan, anda perlu menyesuaikan fail my.cnf mengikut konfigurasi pelayan, seperti parameter innodb_buffer_pool_size, dan tutup query_cache_size; 2. Buat indeks yang sesuai untuk mengelakkan indeks yang berlebihan, dan mengoptimumkan pernyataan pertanyaan, seperti menggunakan perintah menjelaskan untuk menganalisis pelan pelaksanaan; 3. Gunakan alat pemantauan MySQL sendiri (ShowProcessList, ShowStatus) untuk memantau kesihatan pangkalan data, dan kerap membuat semula dan mengatur pangkalan data. Hanya dengan terus mengoptimumkan langkah -langkah ini, prestasi pangkalan data MySQL diperbaiki.
 Apakah kesan PS Feathering pada kualiti imej?
Apr 06, 2025 pm 07:21 PM
Apakah kesan PS Feathering pada kualiti imej?
Apr 06, 2025 pm 07:21 PM
PS Feathering boleh menyebabkan kehilangan butiran imej, ketepuan warna yang dikurangkan dan peningkatan bunyi. Untuk mengurangkan kesan, disarankan untuk menggunakan radius bulu yang lebih kecil, menyalin lapisan dan kemudian bulu, dan berhati -hati membandingkan kualiti imej sebelum dan selepas bulu. Di samping itu, bulu tidak sesuai untuk semua kes, dan kadang -kadang alat seperti topeng lebih sesuai untuk mengendalikan tepi imej.
 Bagaimana untuk mengoptimumkan prestasi MySQL untuk aplikasi beban tinggi?
Apr 08, 2025 pm 06:03 PM
Bagaimana untuk mengoptimumkan prestasi MySQL untuk aplikasi beban tinggi?
Apr 08, 2025 pm 06:03 PM
Panduan Pengoptimuman Prestasi Pangkalan Data MySQL Dalam aplikasi yang berintensifkan sumber, pangkalan data MySQL memainkan peranan penting dan bertanggungjawab untuk menguruskan urus niaga besar-besaran. Walau bagaimanapun, apabila skala aplikasi berkembang, kemunculan prestasi pangkalan data sering menjadi kekangan. Artikel ini akan meneroka satu siri strategi pengoptimuman prestasi MySQL yang berkesan untuk memastikan aplikasi anda tetap cekap dan responsif di bawah beban tinggi. Kami akan menggabungkan kes-kes sebenar untuk menerangkan teknologi utama yang mendalam seperti pengindeksan, pengoptimuman pertanyaan, reka bentuk pangkalan data dan caching. 1. Reka bentuk seni bina pangkalan data dan seni bina pangkalan data yang dioptimumkan adalah asas pengoptimuman prestasi MySQL. Berikut adalah beberapa prinsip teras: Memilih jenis data yang betul dan memilih jenis data terkecil yang memenuhi keperluan bukan sahaja dapat menjimatkan ruang penyimpanan, tetapi juga meningkatkan kelajuan pemprosesan data.
 Cara Pratonton halaman Bootstrap
Apr 07, 2025 am 10:06 AM
Cara Pratonton halaman Bootstrap
Apr 07, 2025 am 10:06 AM
Kaedah pratonton halaman bootstrap adalah: buka fail HTML secara langsung dalam penyemak imbas; Secara automatik menyegarkan penyemak imbas menggunakan plug-in pelayan langsung; dan membina pelayan tempatan untuk mensimulasikan persekitaran dalam talian.
