

MySql的事务隔离级别的详细介绍(附代码)

本篇文章给大家带来的内容是关于MySql的事务隔离级别的详细介绍(附代码),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。
一、事务的四大特性(ACID)
了解事务隔离级别之前不得不了解的事务的四大特性。
1、原子性(Atomicity)
事务开始后所有操作,要么全部做完,要么全部不做。事务是一个不可分割的整体。事务在执行过程中出错,会回滚到事务开始之前的状态,以此来保证事务的完整性。类似于原子在物理上的解释:指化学反应不可再分的基本微粒,原子在化学反应中不可分割 。
2、一致性(Consistency)
事务在开始和结束后,能保证数据库完整性约束的正确性即数据的完整性。比如经典的转账案例,A向B转账,我们必须保证A扣了钱,B一定能收到钱。个人理解类似于物理上的能量守恒。
3、隔离性(Isolation)
事务之间的完全隔离。比如A向一张银行卡转账,避免在同一时间过多的操作导致账户金额的缺损,所以在A转入结束之前是不允许其他针对此卡的操作的。
4、持久性(Durability)
事务的对数据的影响是永久性的。通俗的解释为事务完成后,对数据的操作都要进行落盘(持久化)。事务一旦完成就是不可逆的,在数据库的操作上表现为事务一旦完成就是无法回滚的。
二、事务并发问题
在互联网的大潮中,程序存在的价值早已不是在传统行业中为了帮人们解决一些复杂的业务逻辑。用户体验至上的互联网时代,代码就像西二旗地铁站码农的脚步一样,速度、速度、还是速度。当然也不能坐错了方向,本来想去西直门最后到了东直门(暂且理解为正确性吧)。相对于传统行业复杂的业务逻辑,互联网更注重并发带给程序的速度与激情。当然超速也是有代价的。在并发事务中,一不小心可怜的码农就要跑路了。
1、脏读
又称无效数据读出。一个事务读取另外一个事务还没有提交的数据叫脏读。
例如:事务T1修改了一行数据,但是还没有提交,这时候事务T2读取了被事务T1修改后的数据,之后事务T1因为某种原因Rollback了,那么事务T2读取的就是脏数据。
2、不可重复读
同一个事务中,多次读出的同一数据是不一致的。
例如:事务T1读取某一数据,事务T2读取并修改了该数据,T1为了对读取值进行检验而再次读取该数据,便得到了不同的结果。
3、幻读
不好表述直接上例子吧:
在仓库管理中,管理员要给刚到的一批商品进入库管理,当然入库之前肯定是要查一下之前有没有入库记录,确保正确性。管理员A确保库中不存在该商品之后给该商品进行入库操作,假如这时管理员B因为手快将已将该商品进行了入库操作。这时管理员A发现该商品已经在库中。就像刚刚发生了幻读一样,本来不存在的东西,突然之间他就有了。
注:三种问题看似不太好理解,脏读侧重的是数据的正确性。不可重复度侧重的于对数据的修改,幻读侧重于数据的新增和删除。
三、MySql四种事务隔离级别
上一章节了解了高并发下对事务的影响。事务的四种隔离级别就是对以上三种问题的解决方案。
| 隔离级别 | 脏读 | 不可重复度 | 幻读 |
| 读未提交(read-uncommitted) | 是 | 是 | 是 |
| 不可重复读(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 可串行化(serializable) | 否 | 否 | 否 |
四、sql演示四种隔离级别
mysql版本:5.6
存储引擎:InnoDB
工具:navicat
建表语句:
CREATE TABLE `tb_bank` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(16) COLLATE utf8_bin DEFAULT NULL, `account` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin; INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (1, '小明', 1000);
1、通过sql演示------read-uncommitted的脏读
(2)read-uncommit导致的脏读
所谓脏读就是说,两个事务,其中一个事务能读取到另一个事务未提交的数据。
场景:session1要转出200元,session2转入100元。基数为1000。顺利完成正确的结果应该是900元。但是我们假设session2转入因为某种原因事务回滚。这时正确的结果应该是800元。
演示步骤:
① 新建两个session(会话,在navicat中表现为两个查询窗口,在mysql命令行中也是两个窗口),分别执行
select @@tx_isolation;//查询当前事务隔离级别 set session transaction isolation level read uncommitted;//将事务隔离级别设置为 读未提交
② 两个session都开启事务
start transaction;//开启事务
③ session1和session2:证明两个操作执行前账户余额为1000
select * from tb_bank where id=1;//查询结果为1000
④ session2:此时假设session2的更新先执行。
update tb_bank set account = account + 100 where id=1;
⑤ session1:在session2 commit之前session1开始执行。
select * from tb_bank where id=1;//查询结果:1100
⑥ session2:因为某种原因,转入失败,事务回滚。
rollback;//事务回滚 commit;//提交事务
⑦ 这时session1开始转出,并且session1觉得⑤中查询结果1100就是正确的数据。
update tb_bank set account=1100-200 where id=1; commit;
⑧ session1 和 session2查询结果
select * from tb_bank where id=1;//查询结果:900
这时我们发现因为session1的脏读造成了最终数据不一致。正确的结果应该为800;
到此我们怎么避免脏读呢,将事务的隔离性增加一个级别到read-commit
(2)read-commit解决脏读
重置数据,使数据恢复到account=1000
① 新建两个session,分别设置
set session transaction isolation level read committed;//将隔离级别设置为 不可重复读
重复执行(1)中的②③④步
⑤ session1执行查询
select * from tb_bank where id=1;//查询结果为1000,这说明 不可重复读 隔离级别有效的隔离了两个会话的事务。
这时我们发现,将事务的隔离升级为read-committed;后有效的隔离了两个事务,使得session1中的事务无法查询到session2中事务对数据的改动。有效的避免了脏读。
2、通过sql演示-----read-committed的不可重复读
(1)read-commit的不可重复读
重置数据,使数据恢复到account=1000
所谓的不可重复读就是说,一个事务不能读取到另一个未提交的事务的数据,但是可以读取到提交后的数据。这个时候就造成了两次读取的结果不一致了。所以说是不可重复读。
READ COMMITTED 隔离级别下,每次读取都会重新生成一个快照,所以每次快照都是最新的,也因此事务中每次SELECT也可以看到其它已commit事务所作的更改
场景:session1进行账户的查询,session2进行账户的转入100。
session1开启事务准备对账户进行查询然后更新,这时session2也对该账户开启了事务进行更新。正确的结果应该是在session1开启事务以后查询读到的结果应该是一样的。
① 新建两个session,分别设置
set session transaction isolation level read committed;
② session1和session2分别开启事务
start transaction;
③ session1第一次查询:
select * from tb_bank where id=1;//查询结果:1000
④ session2进行更新:
update tb_bank set account = account+100 where id=1; select * from tb_bank where id=1;//查询结果:1100
⑤ session1第二次查询:
select * from tb_bank where id=1;//查询结果:1100。和③中查询结果对比,session1两次查询结果不一致。
查看查询结果可知,session1在开启事务期间发生重复读结果不一致,所以可以看到read commit事务隔离级别是不可重复读的。显然这种结果不是我们想要的。
(2)repeatable-read可重复读
重置数据,使数据恢复到account=1000
① 新建两个session,分别设置
set session transaction isolation level repeatable read;
重复(1)中的②③④
⑤ session1第二次查询:
select * from tb_bank where id=1;//查询结果为:1000
从结果可知,repeatable-read的隔离级别下,多次读取结果是不受其他事务影响的。是可重复读的。到这里产生了一个疑问,那session1在读到的结果中依然是session2更新前的结果,那session1中继续转入100能得到正确的1200的结果吗?
继续操作:
⑥ session1转入100:
update tb_bank set account=account+100 where id=1;
到这里感觉自己被骗了,锁,锁,锁。session1的更新语句被阻塞了。只有session2中的update语句commit之后,session1中才能继续执行。session的执行结果是1200,这时发现session1并不是用1000+100计算的,因为可重复读的隔离级别下使用了MVCC机制,select操作不会更新版本号,是快照读(历史版本)。insert、update和delete会更新版本号,是当前读(当前版本)。
3、通过sql演示-----repeatable-read的幻读
在业务逻辑中,通常我们先获取数据库中的数据,然后在业务中判断该条件是否符合自己的业务逻辑,如果是的话,那么就可以插入一部分数据。但是mysql的快照读可能在这个过程中会产生意想不到的结果。
场景模拟:
session1开启事务,先查询有没有小张的账户信息,没有的话就插入一条。这是session2也执行和session1同样的操作。
准备工作:插入两条数据
INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (2, '小红', 800); INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (3, '小磊', 6000);
(1)repeatable-read的幻读
① 新建两个session都执行
set session transaction isolation level repeatable read; start transaction; select * from tb_bank;//查询结果:(这一步很重要,直接决定了快照生成的时间)
结果都是:
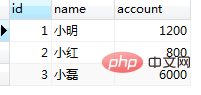
② session2插入数据
INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (4, '小张', 8000); select * from tb_bank;
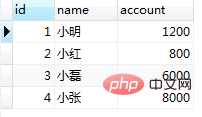
结果数据插入成功。此时session2提交事务
commit;
③ session1进行插入
插入之前我们先看一下当前session1是否有id=4的数据
select * from tb_bank;
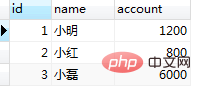
结果session1中没有该条记录,这时按照我们通常的业务逻辑,此时应该是能成功插入id=4的数据。继续执行:
INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (4, '小张', 8000);

结果插入失败,提示该条已经存在,但是我们查询里面并没有这一条数据啊。为什么会插入失败呢?
因为①中的select语句生成了快照,之后的读操作(未加读锁)都是进行的快照读,即在当前事务结束前,所有的读操作的结果都是第一次快照读产生的快照版本。疑问又来了,为什么②步骤中的select语句读到的不是快照版本呢?因为update语句会更新当前事务的快照版本。具体参阅第五章节。
(2)repeatable-read利用当前读解决幻读
重复(1)中的①②
③ session1进行插入
插入之前我们先看一下当前session1是否有id=4的数据
select * from tb_bank;
结果session1中没有该条记录,这时按照我们通常的业务逻辑,此时应该是能成功插入id=4的数据。
select * from tb_bank lock in share mode;//采用当前读
结果:发现当前结果中已经有小张的账户信息了,按照业务逻辑,我们就不在继续执行插入操作了。
这时我们发现用当前读避免了repeatable-read隔离级别下的幻读现象。
4、serializable隔离级别
在此级别下我们就不再做serializable的避免幻读的sql演示了,毕竟是给整张表都加锁的。
五、当前读和快照读
本想把当前读和快照读单开一片博客,但是为了把幻读总结明白,暂且在本章节先简单解释下快照读和当前读。后期再追加一篇MVCC,next-key的博客吧。。。
1、快照读:即一致非锁定读。
① InnoDB存储引擎下,查询语句默认执行快照读。
② RR隔离级别下一个事务中的第一次读操作会产生数据的快照。
③ update,insert,delete操作会更新快照。
四种事务隔离级别下的快照读区别:
① read-uncommitted和read-committed级别:每次读都会产生一个新的快照,每次读取的都是最新的,因此RC级别下select结果能看到其他事务对当前数据的修改,RU级别甚至能读取到其他未提交事务的数据。也因此这两个级别下数据是不可重复读的。
② repeatable-read级别:基于MVCC的并发控制,并发性能极高。第一次读会产生读数据快照,之后在当前事务中未发生快照更新的情况下,读操作都会和第一次读结果保持一致。快照产生于事务中,不同事务中的快照是完全隔离的。
③ serializable级别:从MVCC并发控制退化为基于锁的并发控制。不区别快照读与当前读,所有的读操作均为当前读,读加读锁 (S锁),写加写锁 (X锁)。Serializable隔离级别下,读写冲突,因此并发度急剧下降。(锁表,不建议使用)
2、当前读:即一致锁定读。
如何产生当前读
① select ... lock in share mode
② select ... for update
③ update,insert,delete操作都是当前读。
读取之后,还需要保证当前记录不能被其他并发事务修改,需要对当前记录加锁。①中对读取记录加S锁 (共享锁),②③X锁 (排它锁)。
3、疑问总结
① update,insert,delete操作为什么都是当前读?
简单来说,不执行当前读,数据的完整性约束就有可能遭到破坏。尤其在高并发的环境下。
分析update语句的执行步骤:update table set ... where ...;
InnoDB引擎首先进行where的查询,查询到的结果集从第一条开始执行当前读,然后执行update操作,然后当前读第二条数据,执行update操作......所以每次执行update都伴随着当前读。delete也是一样,毕竟要先查到该数据才能删除。insert有点不同,insert操作执行前需要执行唯一键的检查。【相关推荐:MySQL教程】
Atas ialah kandungan terperinci MySql的事务隔离级别的详细介绍(附代码). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1659
1659
 14
1416
52
1310
25
1259
29
1233
24
14
1416
52
1310
25
1259
29
1233
24

 Peranan MySQL: Pangkalan Data dalam Aplikasi Web
Apr 17, 2025 am 12:23 AM
Peranan MySQL: Pangkalan Data dalam Aplikasi Web
Apr 17, 2025 am 12:23 AM
Peranan utama MySQL dalam aplikasi web adalah untuk menyimpan dan mengurus data. 1.MYSQL dengan cekap memproses maklumat pengguna, katalog produk, rekod urus niaga dan data lain. 2. Melalui pertanyaan SQL, pemaju boleh mengekstrak maklumat dari pangkalan data untuk menghasilkan kandungan dinamik. 3.MYSQL berfungsi berdasarkan model klien-pelayan untuk memastikan kelajuan pertanyaan yang boleh diterima.
 Cara Memulakan MySQL oleh Docker
Apr 15, 2025 pm 12:09 PM
Cara Memulakan MySQL oleh Docker
Apr 15, 2025 pm 12:09 PM
Proses memulakan MySQL di Docker terdiri daripada langkah -langkah berikut: Tarik imej MySQL untuk membuat dan memulakan bekas, tetapkan kata laluan pengguna root, dan memetakan sambungan pengesahan port Buat pangkalan data dan pengguna memberikan semua kebenaran ke pangkalan data
 Contoh Pengenalan Laravel
Apr 18, 2025 pm 12:45 PM
Contoh Pengenalan Laravel
Apr 18, 2025 pm 12:45 PM
Laravel adalah rangka kerja PHP untuk membina aplikasi web yang mudah. Ia menyediakan pelbagai ciri yang kuat termasuk: Pemasangan: Pasang Laravel CLI secara global dengan komposer dan buat aplikasi dalam direktori projek. Routing: Tentukan hubungan antara URL dan pengendali dalam laluan/web.php. Lihat: Buat pandangan dalam sumber/pandangan untuk menjadikan antara muka aplikasi. Integrasi Pangkalan Data: Menyediakan integrasi keluar-of-the-box dengan pangkalan data seperti MySQL dan menggunakan penghijrahan untuk membuat dan mengubah suai jadual. Model dan Pengawal: Model mewakili entiti pangkalan data dan proses pengawal permintaan HTTP.
 Selesaikan masalah sambungan pangkalan data: Kes praktikal menggunakan perpustakaan mini/db
Apr 18, 2025 am 07:09 AM
Selesaikan masalah sambungan pangkalan data: Kes praktikal menggunakan perpustakaan mini/db
Apr 18, 2025 am 07:09 AM
Saya menghadapi masalah yang rumit ketika membangunkan aplikasi kecil: keperluan untuk mengintegrasikan perpustakaan operasi pangkalan data ringan dengan cepat. Selepas mencuba beberapa perpustakaan, saya mendapati bahawa mereka mempunyai terlalu banyak fungsi atau tidak serasi. Akhirnya, saya dapati Minii/DB, versi mudah berdasarkan YII2 yang menyelesaikan masalah saya dengan sempurna.
 MySQL dan PHPMyAdmin: Ciri dan Fungsi Teras
Apr 22, 2025 am 12:12 AM
MySQL dan PHPMyAdmin: Ciri dan Fungsi Teras
Apr 22, 2025 am 12:12 AM
MySQL dan phpmyadmin adalah alat pengurusan pangkalan data yang kuat. 1) MySQL digunakan untuk membuat pangkalan data dan jadual, dan untuk melaksanakan pertanyaan DML dan SQL. 2) Phpmyadmin menyediakan antara muka intuitif untuk pengurusan pangkalan data, pengurusan struktur meja, operasi data dan pengurusan kebenaran pengguna.
 Mysql vs Bahasa Pengaturcaraan Lain: Perbandingan
Apr 19, 2025 am 12:22 AM
Mysql vs Bahasa Pengaturcaraan Lain: Perbandingan
Apr 19, 2025 am 12:22 AM
Berbanding dengan bahasa pengaturcaraan lain, MySQL digunakan terutamanya untuk menyimpan dan mengurus data, manakala bahasa lain seperti Python, Java, dan C digunakan untuk pemprosesan logik dan pembangunan aplikasi. MySQL terkenal dengan prestasi tinggi, skalabilitas dan sokongan silang platform, sesuai untuk keperluan pengurusan data, sementara bahasa lain mempunyai kelebihan dalam bidang masing-masing seperti analisis data, aplikasi perusahaan, dan pengaturcaraan sistem.
 Kaedah pemasangan kerangka Laravel
Apr 18, 2025 pm 12:54 PM
Kaedah pemasangan kerangka Laravel
Apr 18, 2025 pm 12:54 PM
Ringkasan Artikel: Artikel ini menyediakan arahan langkah demi langkah terperinci untuk membimbing pembaca tentang cara memasang rangka kerja Laravel dengan mudah. Laravel adalah rangka kerja PHP yang kuat yang mempercepat proses pembangunan aplikasi web. Tutorial ini merangkumi proses pemasangan dari keperluan sistem untuk mengkonfigurasi pangkalan data dan menyediakan penghalaan. Dengan mengikuti langkah -langkah ini, pembaca dapat dengan cepat dan cekap meletakkan asas yang kukuh untuk projek Laravel mereka.
 MySQL vs Pangkalan Data Lain: Membandingkan Pilihan
Apr 15, 2025 am 12:08 AM
MySQL vs Pangkalan Data Lain: Membandingkan Pilihan
Apr 15, 2025 am 12:08 AM
MySQL sesuai untuk aplikasi web dan sistem pengurusan kandungan dan popular untuk sumber terbuka, prestasi tinggi dan kemudahan penggunaan. 1) Berbanding dengan PostgreSQL, MySQL melakukan lebih baik dalam pertanyaan mudah dan operasi membaca serentak yang tinggi. 2) Berbanding dengan Oracle, MySQL lebih popular di kalangan perusahaan kecil dan sederhana kerana sumber terbuka dan kos rendah. 3) Berbanding dengan Microsoft SQL Server, MySQL lebih sesuai untuk aplikasi silang platform. 4) Tidak seperti MongoDB, MySQL lebih sesuai untuk data berstruktur dan pemprosesan transaksi.
