

python爬虫可以爬视频吗

网络爬虫又称网络蜘蛛,是指按照某种规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常包含其他网页的入口,网络爬虫则通过一个网址依次进入其他网址获取所需内容。

爬虫结构
爬虫调度程序(程序的入口,用于启动整个程序)
url管理器(用于管理未爬取得url及已经爬取过的url)
网页下载器(用于下载网页内容用于分析)
网页解析器(用于解析下载的网页,获取新的url和所需内容)
网页输出器(用于把获取到的内容以文件的形式输出)
第一步
分析网页源码。 例如:http://video.weibo.com/show?fid=1034:0988e59a12e5178acb7f23adc3fe5e97,右键查看源码,一般视频都是mp4后缀,搜索发现没有,但是有的直接就能看到了比如美拍的视频。
相关推荐:《python视频教程》
第二步
抓包,分析请求和返回。这个也可以通过强大的chrome实现,还是上面的例子,右键->审查元素->NetWork,然后F5刷新网页
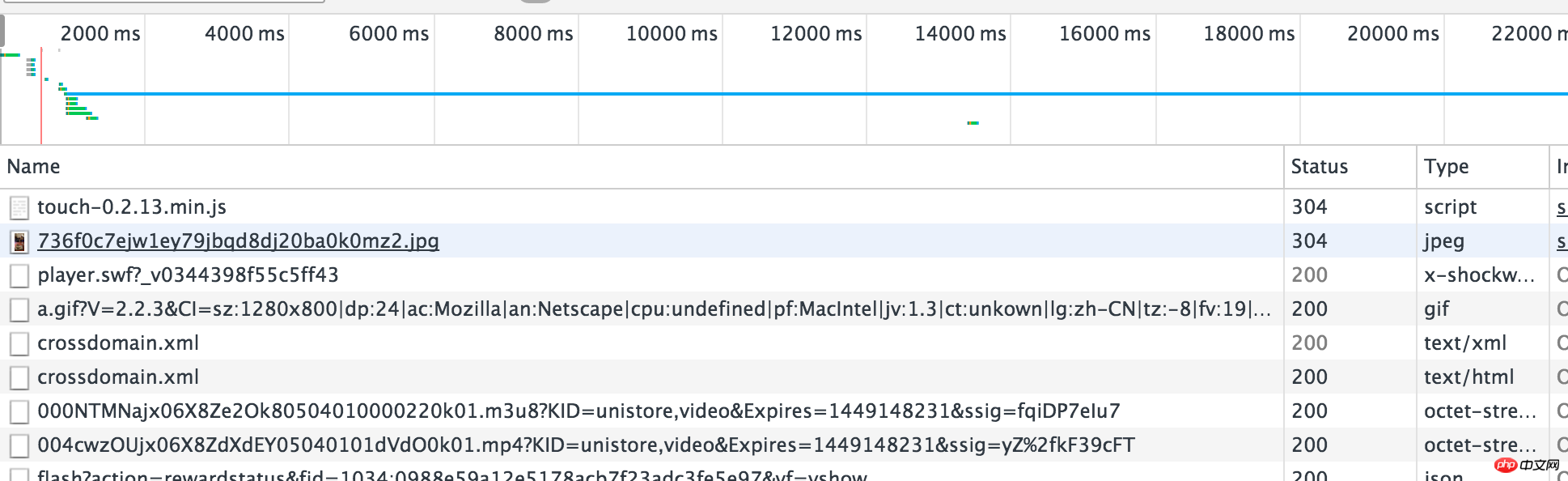
发现有很多请求,只能一条一条的分析了,其实视频格式就是那几种mp4,flv,avi了,一下就能看到了,复制到浏览器中打开,果然就是我们想要的下载链接了。
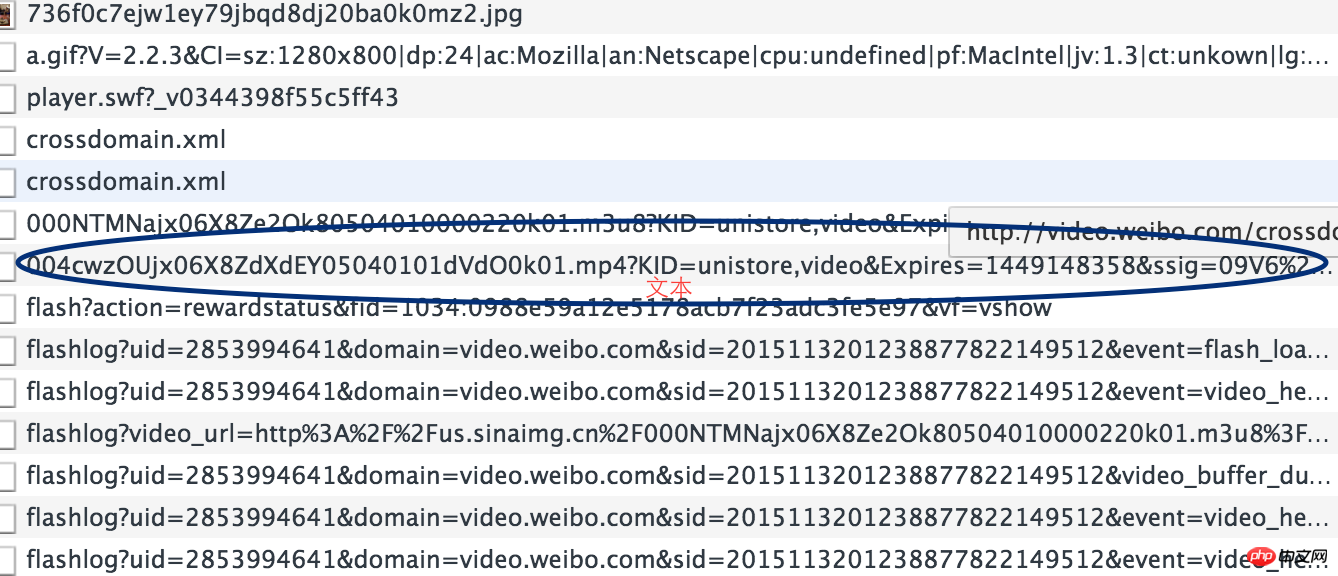
第三步
分析下载链接和视频链接的规律。即http://video.weibo.com/show?fid=1034:0988e59a12e5178acb7f23adc3fe5e97与xxx.mp4的关系。这个又需要分析网页源码了,其实可以注意上面那个以.m3u8后缀的链接,m3u8记录了一个索引纯文本文件,打开它时播放软件并不是播放它,而是根据它的索引找到对应的音视频文件的网络地址进行在线播放,打开看,里面确实记录着我们想要的下载链接。而且.m3u8后缀的链接就在网页源码中。

总结
经过前三步的分析,获取视频下载链接的思路就是先从网页源码中获取.m3u8后缀的链接,下载该文件,从里面得到视频下载链接,最后下载视频就好了
源码
#coding=utf-8
import os
import re
import urllib2
import urllib
from common import Common
class SinaVideo():
URL_PIRFIX = "http://us.sinaimg.cn/"
def getM3u8(self,html):
reg = re.compile(r'list=([\s\S]*?)&fid')
result = reg.findall(html)
return result[0]
def getName(self,url):
return url.split('=')[1]
def getSinavideoUrl(self,filepath):
f = open(filepath,'r')
lines = f.readlines()
f.close()
for line in lines:
if line[0] !='#':
return line
def download(self,url,filepath):
#获取名称
name = self.getName(url)
html = Common.getHtml(url)
m3u8 = self.getM3u8(html)
Common.download(urllib.unquote(m3u8),filepath,name + '.m3u8')
url = self.URL_PIRFIX + self.getSinavideoUrl(filepath+name+'.m3u8')
Common.download(url,filepath,name+'.mp4')#common.py
#coding=utf-8
import urllib2
import os
import re
class Common():
# 获取网页源码
@staticmethod
def getHtml(url):
html = urllib2.urlopen(url).read()
print "[+]获取网页源码:"+url
return html
# 下载文件
@staticmethod
def download(url,filepath,filename):
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Charset': 'UTF-8,*;q=0.5',
'Accept-Encoding': 'gzip,deflate,sdch',
'Accept-Language': 'en-US,en;q=0.8',
'User-Agent': 'Mozilla/5.0 (Linux; Android 4.4.2; Nexus 4 Build/KOT49H)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.114 Mobile Safari/537.36'
}
request = urllib2.Request(url,headers = headers);
response = urllib2.urlopen(request)
path = filepath + filename
with open(path,'wb') as output:
while True:
buffer = response.read(1024*256);
if not buffer:
break
# received += len(buffer)
output.write(buffer)
print "[+]下载文件成功:"+path
@staticmethod
def isExist(filepath):
return os.path.exists(filepath)
@staticmethod
def createDir(filepath):
os.makedirs(filepath,0777)调用方式:
url = "http://video.weibo.com/show?fid=1034:0988e59a12e5178acb7f23adc3fe5e97"sinavideo = SinaVideo() sinavideo.download(url,""/Users/cheng/Documents/PyScript/res/"")
结果:

Atas ialah kandungan terperinci python爬虫可以爬视频吗. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Python: Permainan, GUI, dan banyak lagi
Apr 13, 2025 am 12:14 AM
Python: Permainan, GUI, dan banyak lagi
Apr 13, 2025 am 12:14 AM
Python cemerlang dalam permainan dan pembangunan GUI. 1) Pembangunan permainan menggunakan pygame, menyediakan lukisan, audio dan fungsi lain, yang sesuai untuk membuat permainan 2D. 2) Pembangunan GUI boleh memilih tkinter atau pyqt. TKInter adalah mudah dan mudah digunakan, PYQT mempunyai fungsi yang kaya dan sesuai untuk pembangunan profesional.
 PHP dan Python: Membandingkan dua bahasa pengaturcaraan yang popular
Apr 14, 2025 am 12:13 AM
PHP dan Python: Membandingkan dua bahasa pengaturcaraan yang popular
Apr 14, 2025 am 12:13 AM
PHP dan Python masing -masing mempunyai kelebihan mereka sendiri, dan memilih mengikut keperluan projek. 1.PHP sesuai untuk pembangunan web, terutamanya untuk pembangunan pesat dan penyelenggaraan laman web. 2. Python sesuai untuk sains data, pembelajaran mesin dan kecerdasan buatan, dengan sintaks ringkas dan sesuai untuk pemula.
 Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Fungsi Readdir dalam sistem Debian adalah panggilan sistem yang digunakan untuk membaca kandungan direktori dan sering digunakan dalam pengaturcaraan C. Artikel ini akan menerangkan cara mengintegrasikan Readdir dengan alat lain untuk meningkatkan fungsinya. Kaedah 1: Menggabungkan Program Bahasa C dan Pipeline Pertama, tulis program C untuk memanggil fungsi Readdir dan output hasilnya:#termasuk#termasuk#includeintMain (intargc, char*argv []) {dir*dir; structdirent*entry; if (argc! = 2) {
 Python dan Masa: Memanfaatkan masa belajar anda
Apr 14, 2025 am 12:02 AM
Python dan Masa: Memanfaatkan masa belajar anda
Apr 14, 2025 am 12:02 AM
Untuk memaksimumkan kecekapan pembelajaran Python dalam masa yang terhad, anda boleh menggunakan modul, masa, dan modul Python. 1. Modul DateTime digunakan untuk merakam dan merancang masa pembelajaran. 2. Modul Masa membantu menetapkan kajian dan masa rehat. 3. Modul Jadual secara automatik mengatur tugas pembelajaran mingguan.
 Nginx SSL Sijil Tutorial Debian
Apr 13, 2025 am 07:21 AM
Nginx SSL Sijil Tutorial Debian
Apr 13, 2025 am 07:21 AM
Artikel ini akan membimbing anda tentang cara mengemas kini sijil NginxSSL anda pada sistem Debian anda. Langkah 1: Pasang Certbot terlebih dahulu, pastikan sistem anda mempunyai pakej CertBot dan Python3-CertBot-Nginx yang dipasang. Jika tidak dipasang, sila laksanakan arahan berikut: sudoapt-getupdateudoapt-getinstallcertbotpython3-certbot-nginx Langkah 2: Dapatkan dan konfigurasikan sijil Gunakan perintah certbot untuk mendapatkan sijil let'Sencrypt dan konfigurasikan nginx: sudoCertBot-ninx ikuti
 Cara mengkonfigurasi pelayan https di debian openssl
Apr 13, 2025 am 11:03 AM
Cara mengkonfigurasi pelayan https di debian openssl
Apr 13, 2025 am 11:03 AM
Mengkonfigurasi pelayan HTTPS pada sistem Debian melibatkan beberapa langkah, termasuk memasang perisian yang diperlukan, menghasilkan sijil SSL, dan mengkonfigurasi pelayan web (seperti Apache atau Nginx) untuk menggunakan sijil SSL. Berikut adalah panduan asas, dengan mengandaikan anda menggunakan pelayan Apacheweb. 1. Pasang perisian yang diperlukan terlebih dahulu, pastikan sistem anda terkini dan pasang Apache dan OpenSSL: sudoaptDateSudoaptgradesudoaptinsta
 Panduan Pembangunan Plug-In Gitlab di Debian
Apr 13, 2025 am 08:24 AM
Panduan Pembangunan Plug-In Gitlab di Debian
Apr 13, 2025 am 08:24 AM
Membangunkan plugin Gitlab pada Debian memerlukan beberapa langkah dan pengetahuan tertentu. Berikut adalah panduan asas untuk membantu anda memulakan proses ini. Memasang GitLab terlebih dahulu, anda perlu memasang GitLab pada sistem Debian anda. Anda boleh merujuk kepada manual pemasangan rasmi GitLab. Dapatkan token akses API sebelum melakukan integrasi API, anda perlu mendapatkan token akses API Gitlab terlebih dahulu. Buka papan pemuka Gitlab, cari pilihan "AccessTokens" dalam tetapan pengguna, dan menghasilkan token akses baru. Akan dijana
 Perkhidmatan apa yang Apache
Apr 13, 2025 pm 12:06 PM
Perkhidmatan apa yang Apache
Apr 13, 2025 pm 12:06 PM
Apache adalah wira di belakang internet. Ia bukan sahaja pelayan web, tetapi juga platform yang kuat yang menyokong lalu lintas yang besar dan menyediakan kandungan dinamik. Ia memberikan fleksibiliti yang sangat tinggi melalui reka bentuk modular, yang membolehkan pengembangan pelbagai fungsi seperti yang diperlukan. Walau bagaimanapun, modulariti juga membentangkan cabaran konfigurasi dan prestasi yang memerlukan pengurusan yang teliti. Apache sesuai untuk senario pelayan yang memerlukan keperluan yang sangat disesuaikan dan memenuhi keperluan kompleks.
