DOM DOM ialah singkatan kepada Model objek Dokumen. Model objek dokumen ialah dokumen yang menyatakan XML atau HTML dalam bentuk nod pokok. Menggunakan kaedah dan sifat DOM, anda boleh mengakses, mengubah suai, memadam sebarang elemen pada halaman dan anda juga boleh menambah elemen. DOM ialah API bebas bahasa yang boleh dilaksanakan dalam mana-mana bahasa, termasuk Javascript
Lihatlah salah satu teks di bawah.
Anda boleh melihat bahawa ini adalah tag p. Ia termasuk dalam tag badan. Jadi badan ialah nod induk p, dan p ialah nod anak. Perenggan pertama dan ketiga juga merupakan nod anak badan. Mereka semua adalah nod adik-beradik perenggan kedua. Teg em ini ialah nod anak bagi segmen kedua p. Oleh itu p ialah nod induknya. Hubungan nod ibu bapa-anak boleh menggambarkan hubungan seperti pokok. Jadi ia dipanggil pokok DOM.
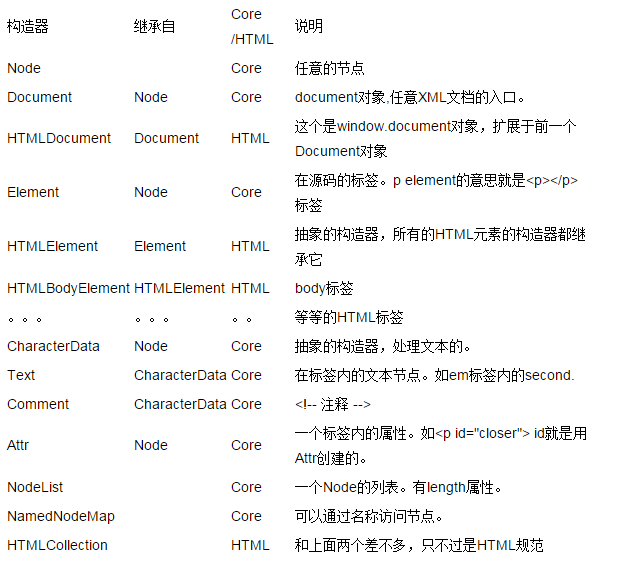
DOM Teras dan DOM HTML Kami sudah tahu bahawa DOM boleh menggambarkan dokumen HTML dan XML. Malah, dokumen HTML ialah dokumen XML, tetapi lebih standard. Oleh itu, sebagai sebahagian daripada DOM Tahap 1, spesifikasi DOM Teras digunakan untuk semua dokumen XML dan spesifikasi DOM HTML melanjutkan DOM Teras Sudah tentu, HTML DOM tidak digunakan untuk semua dokumen XML, hanya untuk dokumen HTML. Mari kita lihat pembina Core DOM dan HTML DOM.
Hubungan pembina
Akses nod DOM Sebelum mengesahkan borang atau menukar imej, kita perlu tahu cara mengakses elemen (elemen.). Terdapat banyak cara untuk mendapatkan elemen.
Nod dokumen Kami boleh mengakses dokumen semasa melalui dokumen. Kita boleh menggunakan pepijat api (pemalam Firefox) untuk melihat sifat dan kaedah dokumen.
Semua nod mempunyai atribut nodeType, nodeName, nodeValue. Mari kita lihat pada nodeType of document
document.nodeType;//9
Salin selepas log masuk
Terdapat 12 jenis nod kesemuanya. dokumen ialah 9. Yang biasa digunakan ialah elemen (elemen: 1), atribut (atribut: 2), dan teks (teks: 3).
Nod juga mempunyai nama. untuk tag HTML. Nama nod ialah nama label. Nama nod teks (teks) ialah #text Nama nod dokumen (dokumen) ialah #document.
Nod juga mempunyai nilai. Untuk nod teks, nilainya ialah teks. Nilai dokumen adalah batal
Elemen dokumen XML akan mempunyai nod ROOT untuk membalut dokumen. untuk dokumen HTML. Nod ROOT ialah tag html. Akses nod akar. Anda boleh menggunakan sifat documentElement.
var bd = document.documentElement.childNodes[1];
bd.childNodes.length;//9
Salin selepas log masuk
Jom tengok struktur badan
<body>
<p class="opener">first paragraph</p>
<p><em>second</em> paragraph</p>
<p id="closer">final</p>
<!-- and that's about it -->
</body>
Salin selepas log masuk
Mengapakah bilangan nod anak 9?
Mula-mula terdapat 4 P dan satu ulasan, sejumlah 4.
4 nod termasuk 3 nod kosong. Itu 7.
Nod kosong ke-8 antara badan dan p pertama.
Yang kesembilan ialah nod kosong antara ulasan dan
.
Terdapat 9 nod kesemuanya.
Hartanah Oleh kerana nod pertama ialah nod kosong, nod kedua ialah label p pertama.
Akses kandungan dalam teg Mari kita lihat pada tag pertama p
Anda boleh mengaksesnya menggunakan sifat textContent. Perlu diingatkan bahawa textContent tidak wujud dalam pelayar IE Sila gantikannya dengan innerText Hasilnya adalah sama.
bg.childNodes[1].textContent;// "first paragraph"
Salin selepas log masuk
Terdapat juga atribut yang dipanggil innerHTML Ini bukan spesifikasi DOM. Tetapi semua pelayar utama menyokong atribut ini. Apa yang dikembalikan ialah kod HTML.
bg.childNodes[1].innerHTML;// "first paragraph"
Salin selepas log masuk
Tiada kod html dalam perenggan pertama, jadi hasilnya adalah sama seperti textContent (innerText dalam IE). Mari kita lihat pada teg kedua yang mengandungi kod HTML
<body>
<p class="opener">first paragraph</p>
<p id="closer">final</p>
<!-- and that's about it -->
</body>
Salin selepas log masuk
我们来看看replaceChild的使用。我们把上一个删除节点来替代第二个p
var replaced = document.body.replaceChild(removed, p);
Salin selepas log masuk
和removeChild返回一样。replaced就是移除的节点。现在结果为
<body>
<p class="opener">first paragraph</p>
<p><em>second</em> paragraph</p>
<!-- and that's about it -->
</body>
Salin selepas log masuk
Kenyataan Laman Web ini
Kandungan artikel ini disumbangkan secara sukarela oleh netizen, dan hak cipta adalah milik pengarang asal. Laman web ini tidak memikul tanggungjawab undang-undang yang sepadan. Jika anda menemui sebarang kandungan yang disyaki plagiarisme atau pelanggaran, sila hubungi admin@php.cn
Cara menggunakan WebSocket dan JavaScript untuk melaksanakan sistem pengecaman pertuturan dalam talian Pengenalan: Dengan perkembangan teknologi yang berterusan, teknologi pengecaman pertuturan telah menjadi bahagian penting dalam bidang kecerdasan buatan. Sistem pengecaman pertuturan dalam talian berdasarkan WebSocket dan JavaScript mempunyai ciri kependaman rendah, masa nyata dan platform merentas, dan telah menjadi penyelesaian yang digunakan secara meluas. Artikel ini akan memperkenalkan cara menggunakan WebSocket dan JavaScript untuk melaksanakan sistem pengecaman pertuturan dalam talian.
Alat penting untuk analisis saham: Pelajari langkah-langkah untuk melukis carta lilin dalam PHP dan JS, contoh kod khusus diperlukan Dengan perkembangan pesat Internet dan teknologi, perdagangan saham telah menjadi salah satu cara penting bagi banyak pelabur. Analisis saham adalah bahagian penting dalam membuat keputusan pelabur, dan carta lilin digunakan secara meluas dalam analisis teknikal. Mempelajari cara melukis carta lilin menggunakan PHP dan JS akan memberikan pelabur maklumat yang lebih intuitif untuk membantu mereka membuat keputusan yang lebih baik. Carta candlestick ialah carta teknikal yang memaparkan harga saham dalam bentuk candlestick. Ia menunjukkan harga saham
Teknologi pengesanan dan pengecaman muka adalah teknologi yang agak matang dan digunakan secara meluas. Pada masa ini, bahasa aplikasi Internet yang paling banyak digunakan ialah JS Melaksanakan pengesanan muka dan pengecaman pada bahagian hadapan Web mempunyai kelebihan dan kekurangan berbanding dengan pengecaman muka bahagian belakang. Kelebihan termasuk mengurangkan interaksi rangkaian dan pengecaman masa nyata, yang sangat memendekkan masa menunggu pengguna dan meningkatkan pengalaman pengguna termasuk: terhad oleh saiz model, ketepatannya juga terhad. Bagaimana untuk menggunakan js untuk melaksanakan pengesanan muka di web? Untuk melaksanakan pengecaman muka di Web, anda perlu biasa dengan bahasa dan teknologi pengaturcaraan yang berkaitan, seperti JavaScript, HTML, CSS, WebRTC, dll. Pada masa yang sama, anda juga perlu menguasai visi komputer yang berkaitan dan teknologi kecerdasan buatan. Perlu diingat bahawa kerana reka bentuk bahagian Web
WebSocket dan JavaScript: Teknologi utama untuk merealisasikan sistem pemantauan masa nyata Pengenalan: Dengan perkembangan pesat teknologi Internet, sistem pemantauan masa nyata telah digunakan secara meluas dalam pelbagai bidang. Salah satu teknologi utama untuk mencapai pemantauan masa nyata ialah gabungan WebSocket dan JavaScript. Artikel ini akan memperkenalkan aplikasi WebSocket dan JavaScript dalam sistem pemantauan masa nyata, memberikan contoh kod dan menerangkan prinsip pelaksanaannya secara terperinci. 1. Teknologi WebSocket
Pengenalan kepada cara menggunakan JavaScript dan WebSocket untuk melaksanakan sistem pesanan dalam talian masa nyata: Dengan populariti Internet dan kemajuan teknologi, semakin banyak restoran telah mula menyediakan perkhidmatan pesanan dalam talian. Untuk melaksanakan sistem pesanan dalam talian masa nyata, kami boleh menggunakan teknologi JavaScript dan WebSocket. WebSocket ialah protokol komunikasi dupleks penuh berdasarkan protokol TCP, yang boleh merealisasikan komunikasi dua hala masa nyata antara pelanggan dan pelayan. Dalam sistem pesanan dalam talian masa nyata, apabila pengguna memilih hidangan dan membuat pesanan
Dengan perkembangan pesat kewangan Internet, pelaburan saham telah menjadi pilihan semakin ramai orang. Dalam perdagangan saham, carta lilin adalah kaedah analisis teknikal yang biasa digunakan Ia boleh menunjukkan trend perubahan harga saham dan membantu pelabur membuat keputusan yang lebih tepat. Artikel ini akan memperkenalkan kemahiran pembangunan PHP dan JS, membawa pembaca memahami cara melukis carta lilin saham dan menyediakan contoh kod khusus. 1. Memahami Carta Lilin Saham Sebelum memperkenalkan cara melukis carta lilin saham, kita perlu memahami dahulu apa itu carta lilin. Carta candlestick telah dibangunkan oleh orang Jepun
JavaScript dan WebSocket: Membina sistem ramalan cuaca masa nyata yang cekap Pengenalan: Hari ini, ketepatan ramalan cuaca sangat penting kepada kehidupan harian dan membuat keputusan. Apabila teknologi berkembang, kami boleh menyediakan ramalan cuaca yang lebih tepat dan boleh dipercayai dengan mendapatkan data cuaca dalam masa nyata. Dalam artikel ini, kita akan mempelajari cara menggunakan teknologi JavaScript dan WebSocket untuk membina sistem ramalan cuaca masa nyata yang cekap. Artikel ini akan menunjukkan proses pelaksanaan melalui contoh kod tertentu. Kami
Tutorial JavaScript: Bagaimana untuk mendapatkan kod status HTTP, contoh kod khusus diperlukan: Dalam pembangunan web, interaksi data dengan pelayan sering terlibat. Apabila berkomunikasi dengan pelayan, kami selalunya perlu mendapatkan kod status HTTP yang dikembalikan untuk menentukan sama ada operasi itu berjaya dan melaksanakan pemprosesan yang sepadan berdasarkan kod status yang berbeza. Artikel ini akan mengajar anda cara menggunakan JavaScript untuk mendapatkan kod status HTTP dan menyediakan beberapa contoh kod praktikal. Menggunakan XMLHttpRequest

 hujung hadapan web
hujung hadapan web