

决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。
由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。Entropy = 系统的凌乱程度,使用算法ID3, C4.5和C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念。 (推荐学习:web前端视频教程)
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
分类树(决策树)是一种十分常用的分类方法。他是一种监管学习,所谓监管学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。这样的机器学习就被称之为监督学习。
组成
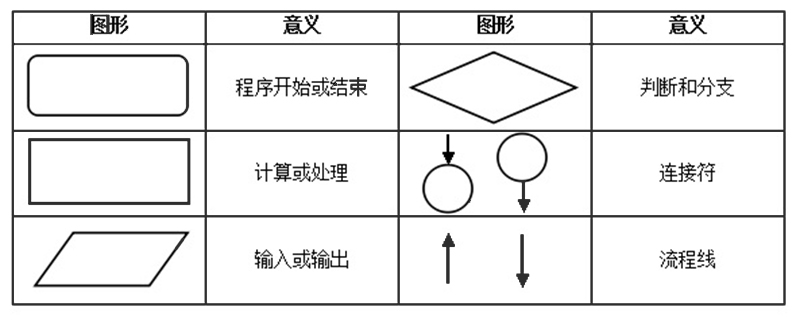
□——决策点,是对几种可能方案的选择,即最后选择的最佳方案。如果决策属于多级决策,则决策树的中间可以有多个决策点,以决策树根部的决策点为最终决策方案。
○——状态节点,代表备选方案的经济效果(期望值),通过各状态节点的经济效果的对比,按照一定的决策标准就可以选出最佳方案。由状态节点引出的分支称为概率枝,概率枝的数目表示可能出现的自然状态数目每个分枝上要注明该状态出现的概率。
△——结果节点,将每个方案在各种自然状态下取得的损益值标注于结果节点的右端。
一个决策树包含三种类型的节点:
决策节点:通常用矩形框来表示
机会节点:通常用圆圈来表示
终结点:通常用三角形来表示
决策树学习也是资料探勘中一个普通的方法。在这里,每个决策树都表述了一种树型结构,它由它的分支来对该类型的对象依靠属性进行分类。每个决策树可以依靠对源数据库的分割进行数据测试。
这个过程可以递归式的对树进行修剪。 当不能再进行分割或一个单独的类可以被应用于某一分支时,递归过程就完成了。另外,随机森林分类器将许多决策树结合起来以提升分类的正确率。
Atas ialah kandungan terperinci 什么是一种基于树结构进行决策的算法. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



